Semantic search
From vexing uncertainty to intellectual humility
A philosopher with schizophrenia wrote a harrowing account of how he experiences schizophrenia. And I wonder if some of the lessons are true for everyone, and what that means for society.
- "It’s definite belief, not certainty, that allows me to get along. It’s not that certainty, or something like it, never matters. If you are fixing dinner for me I’ll try to be clear about the eggplant allergy [...] But most of the time, just having a definite, if unconfirmed and possibly false, belief about the situation is fine. It allows one to get along.
- "I think of this attitude as a kind of “intellectual humility” because although I do care about truth—and as a consequence of caring about truth, I do form beliefs about what is true—I no longer agonize about whether my judgments are wrong. For me, living relatively free from debilitating anxiety is incompatible with relentless pursuit of truth. Instead, I need clear beliefs and a willingness to change them when circumstances and evidence demand, without worrying about, or getting upset about, being wrong. This attitude has made life better and has made the “near-collapses” much rarer."
(first published on Facebook March 13, 2024)
Feeding the cat
Every morning, I lovingly and carefully scoop out every single morsel of meat from the tin of wet food for our cat. And then he eats a tenth of it.
Dolly Parton's What's up?
Dolly Parton is an amazing person. On "Rockstar", her latest album, she covered a great number of songs, with amazing collaborators, often the original interpreters or writers. In her cover of "What's up?", a song I really love, with Linda Perry, she changed a few lines of the lyrics, as one often does when covering, to make a song their own.
Instead of "Twenty-five years and my life is still...", she's singing "All of these years and my life is still..." - and makes total sense, because unlike Linda Perry she wasn't 25 when she wrote it, she was 77 when she recorded it.
Instead of "I take a deep breath and I get real high", Dolly takes "a deep breath and wonders why", and it makes sense, because, hey, it's Dolly Parton.
But here's the line that hurts, right there when the song reaches its high point:
- "And I pray,
- Oh my God do I pray!
- I pray every. single. day.
- for a revolution!"
She changed one letter in the last word:
- "for a resolution"
And it just breaks my heart. Because it feels so weak. Because it seems to betray the song. Because it seems to betray everything. And also because I might agree with her, and that feels like betrayal too.
Views on the US economy 2024
By most metrics, the American economy is doing well. But the perception of the American economy is much weaker than its actual strength. This seems to finally slowly break up a bit, and people are realizing that things are actually not that bad.
Here's an article that tries to explain it: because of high interest rates, credit is expensive, including credit card debt, and if someone is buying a home now.
But if you go beyond the anecdotes as this essay does, and look at the actual data, you will find something else: it is a very partisan thing.
For Democrats we find that it depends. Basically, the more you fit to the dominant group - the richer you are, the older, the better educated, the "whiter", the "maler" - the better your view of the economy.
For Republicans we don't find any such differentiation. Everyone is negative about it, across the board. Their perception of the economic situation are crassly different from the perception of their Democratic peers.
Libertarian cities
I usually try to contain my "Schadenfreude", but reading this article made it really difficult to do so. It starts with the story of Rio Verde Foothills and its lack of water supply after it was intentionally built to circumvent zoning regulations regarding water supply, and lists a few other examples, such as
- "Grafton, New Hampshire. It’s a tiny town that was taken over by libertarians who moved there en masse to create their vision of heaven on earth. They voted themselves into power, slashed taxes and cut the town’s already minuscule budget to the bone. Journalist Matthew Hongoltz-Hetling recounts what happened next:
- 'Grafton was a poor town to begin with, but with tax revenue dropping even as its population expanded, things got steadily worse. Potholes multiplied, domestic disputes proliferated, violent crime spiked, and town workers started going without heat. ...'
- Then the town was taken over by bears."
The article is worth reading:
The Wikipedia article is even more damning:
- "Grafton is an active hub for Libertarians as part of the Free Town Project, an offshoot of the Free State Project. Grafton's appeal as a favorable destination was due to its absence of zoning laws and a very low property tax rate. Grafton was the focus of a movement begun by members of the Free State Project that sought to encourage libertarians to move to the town. After a rash of lawsuits from Free Towners, an influx of sex offenders, an increase of crime, problems with bold local bears, and the first murders in the town's history, the Libertarian project ended in 2016."
Get Morse code from text
On Wikifunctions we have a function that translates text to Morse code. Go ahead, try it out.
I am stating that mostly in order to see if we can get Google to index the function pages on Wikifunctions, because we initially accidentally had them all set to not be indexed.
Playing around with Aliquot
- Warning! Very technical, not particularly insightful, and overly long post about hacking, discrete mathematics, and rabbit holes. I don't think that anything here is novel, others have done more comprehensive work, and found out more interesting stuff. This is not research, I am just playing around.
Ernest Davis is a NYU professor, author of many publications (including “Rebooting AI” with Gary Marcus) and a friend on Facebook. Two days ago he posted about Aliquot sequences, and that it is yet unknown how they behave.
What is an Aliquot sequence? Given a number, take all its proper divisors, and add them up. That’s the next number in the sequence.
It seems that most of these either lead to 0 or end in a repeating pattern. But it may also be that they just keep on going indefinitely. We don’t know if there is any starting number for which that is the case. But the smallest candidate for that is 276.
So far, we know the first 2,145 steps for the Aliquot sequence starting at 276. That results in a number with 214 digits. We don’t know the successor of that number.
I was curious. I know that I wouldn’t be able to figure this out quickly, or, probably ever, because I simply don’t have enough skills in discrete mathematics (it’s not my field), but I wanted to figure out how much progress I can make with little effort. So I coded something up.
Anyone who really wanted to make a crack on this problem would probably choose C. Or, on the other side of the spectrum, Mathematica, but I don’t have a license and I am lazy. So I chose JavaScript. There were two hunches for going with JavaScript instead of my usual first language, Python, which would pay off later, but I will reveal them later in this post.
So, my first implementation was very naïve (source code). The function that calculates the next step in the Aliquot sequence is usually called s in the literature, so I kept that name:
const divisors = (integer) => {
const result = []
for(let i = BigInt(1); i < integer; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
const sum = x => x.reduce( (partialSum, i) => partialSum + i, BigInt(0) )
const s = (integer) => sum(divisors(integer))
I went for BigInt, not integer, because Ernest said that the 2,145th step had 214 digits, and the standard integer numbers in JavaScript stop being exact before we reach 16 digits (at 9,007,199,254,740,991, to be exact), so I chose BigInt, which supports arbitrary long integer numbers.
The first 30 steps ran each under a second on my one decade old 4 core Mac occupying one of the cores, reaching 8 digits, but then already the 36th step took longer than a minute - and we only had 10 digits so far. Worrying about the limits of integers turned out to be a bit preliminary: With this approach I would probably not reach that limit in a lifetime.
I dropped BigInt and just used the normal integers (source code). That gave me 10x-40x speedup! Now the first 33 steps were faster than a second, reaching 9 digits, and it took until the 45th step with 10 digits to be the first one to take longer than a minute. Unsurprisingly, a constant factor speedup wouldn’t do the trick here, we’re fighting against an exponential problem after all.
It was time to make the code less naïve (source code), and the first idea was to not check every number smaller than the target integer whether it divides (line 3 above), but only up to half of the target integer.
const divisors = (integer) => {
const result = []
const half = integer / 2
for(let i = 1; i <= half; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
Tiny change. And exactly the expected impact: it ran double as fast. Now the first 34 steps ran under one second each (9 digits), and the first one to take longer than a minute was the 48th step (11 digits).
Checking until half of the target seemed still excessive. After all, for factorization we only need to check until the square root. That should be a more than constant speedup. And once we have all the factors, we should be able to quickly reconstruct all the divisors. Now this is the point where I have to admit that I have a cold or something, and the code for creating the divisors from the factors is probably overly convoluted and slow, but you know what? It doesn’t matter. The only thing that matters will be the speed of the factorization.
So my next step (source code) was a combination of a still quite naïve approach to factorization, with another function that recreates all the divisors.
const factorize = (integer) => {
const result = [ 1 ]
let i = 2
let product = 1
let rest = integer
let limit = Math.ceil(Math.sqrt(integer))
while (i <= limit) {
if (rest % i == 0) {
result.push(i)
product *= i
rest = integer / product
limit = Math.ceil(Math.sqrt(rest))
} else {
i++
}
}
result.push(rest)
return result
}
const divisors = (integer) => {
const result = [ 1 ]
const inner = (integer, list) => {
result.push(integer)
if (list.length === 0) {
return [ integer ]
}
const in_results = [ integer ]
const in_factors = inner(list[0], list.slice(1))
for (const f of in_factors) {
result.push(integer*f)
result.push(f)
in_results.push(integer*f)
in_results.push(f)
}
return in_results
}
const list = factorize(integer)
inner(list[0], list.slice(1))
const im = [...new Set(result)].sort((a, b) => a - b)
return im.slice(0, im.length-1)
}
That made a big difference! The first 102 steps all were faster than a second, reaching 20 digits! That’s more than 100x speedup! And then, after step 116, the thing crashed.
Remember, integer only does well until 16 digits. The numbers were just too big for the standard integer type. So, back to BigInt. The availability of BigInt in JavaScript was my first hunch for choosing JavaScript (although that would have worked just fine in Python 3 as well). And that led to two surprises.
First, sorting arrays with BigInts is different from sorting arrays with integers. Well, I find already sorting arrays of integers a bit weird in JavaScript. If you don’t specify otherwise it sorts numbers lexicographically, instead of by value:
[ 10, 2, 1 ].sort() == [ 1, 10, 2 ]
You need to provide a custom sorting function in order to sort the numbers by value, e.g.
[ 10, 2, 1 ].sort((a, b) => a-b) == [ 1, 2, 10 ]
The same custom sorting functions won’t work for BigInt, though. The custom function for sorting requires an integer result, not a BigInt. We can write something like this:
.sort((a, b) => (a < b)?-1:((a > b)?1:0))
The second surprise was that BigInt doesn’t have a square root function in the standard library. So I need to write one. Well, Newton is quickly implemented, or copy and pasted (source code).
Now, with switching to BigInt, we get the expected slowdown. The first 92 steps run faster than a second, reaching 19 digits, and then the first step to take longer than a minute is step 119, with 22 digits.
Also, the actual sequences started indeed diverging, due to the inaccuracy of large JavaScript integer: step 83 resulted in 23,762,659,088,671,304 using integers, but 23,762,659,088,671,300 using BigInt. And whereas that looks like a tiny difference on only the last digit, the number for the 84th step showed already what a big difference that makes: 20,792,326,702,587,410 with integers, and 35,168,735,451,235,260 with BigInt. The two sequences went entirely off.
What was also very evident is that at this point some numbers took a long time, and others were very quick. This is what you would expect from a more sophisticated approach to factorization, that it depends on the number and size of the factors. For example, calculating step 126 required to factorize the number 169,306,878,754,562,576,009,556, leading to 282,178,131,257,604,293,349,484, and that took more than 2 hours with that script on my machine. But then in Step 128 the result 552,686,316,482,422,494,409,324 was calculated from 346,582,424,991,772,739,637,140 in less than a second.
At that point I also started taking some of the numbers, and googled them, surfacing a Japanese blog post from ten years ago that posted the first 492 numbers, and also confirming that the 450th of these numbers corresponds to a published source. I compared the list with my numbers and was happy to see they corresponded so far. But I guesstimated I would not in a lifetime reach 492 steps, never mind the actual 2,145.
But that’s OK. Some things just need to be let rest.
That’s also when I realized that I was overly optimistic because I simply misread the number of steps that have been already calculated when reading the original post: I thought it was about 200-something steps, not 2,000-something steps. Or else I would have never started this. But now, thanks to the sunk cost fallacy, I wanted to push it just a bit further.
I took the biggest number that was posted on that blog post, 111,953,269,160,850,453,359,599,437,882,515,033,017,844,320,410,912, and let the algorithm work on that. No point in calculating steps 129, which is how far I have come, through step 492, if someone else already did that work.
While the computer was computing, I leisurely looked for libraries for fast factorization, but I told myself that no way am I going to install some scientific C library for this. And indeed, I found a few, such as the msieve project. Unsurprising, it was in C. But I also found a Website, CrypTool-Online with msieve on the Web (that’s pretty much one of the use cases I hope Wikifunctions will also support rather soonish). And there, I could not only run the numbers I already calculated locally, getting results in subsecond speed which took minutes and hours on my machine, but also the largest number from the Japanese website was factorized in seconds.
That just shows how much better a good library is than my naïve approach. I was slightly annoyed and challenged by the fact how much faster it is. Probably also runs on some fast machine in the cloud. Pretty brave to put a site like that up, and potentially have other people profit from the factorization of large numbers for, e.g. Bitcoin mining on your hardware.
The site is fortunately Open Source, and when I checked the source code I was surprised, delighted, and I understood why they would make it available through a Website: they don’t factorize the number in the cloud, but on the edge, in your browser! If someone uses a lot of resources, they don’t mind: it’s their own resources!
They took the msieve C library and compiled it to WebAssembly. And now I was intrigued. That’s something that’s useful for my work too, to better understand WebAssembly, as we use that in Wikifunctions too, although for now server side. So I rationalized, why not see if I can get that run on Node.
It was a bit of guessing and hacking. The JavaScript binding was written to be used in the browser, and the binary was supposed to be loaded through fetch. I guessed a few modifications, replacing fetch with Node’s FS, and managed to run it in Node. The hacks are terrible, but again, it doesn’t really matter as long as the factorization would speed up.
And after a bit of trying and experimenting, I got it running (source code). And that was my second hunch for choosing JavaScript: it had a great integration for using WebAssembly, and I figured it might come in handy to replace the JavaScript based solution. And now indeed, the factorization was happening in WebAssembly. I didn’t need to install any C libraries, no special environments, no nothing. I just could run Node, and it worked. I am absolutely positive there are is cleaner code out there, and I am sure I mismanaged that code terribly, but I got it to run. At the first run I found that it added an overhead of 4-5 milliseconds on each step, making the first few steps much slower than with pure JavaScript. That was a moment of disappointment.
But then: the first 129 steps, which I was waiting hours and hours to run, zoomed by before I could even look. Less than a minute, and all the 492 steps published on the Japanese blog post were done, allowing me to use them for reference and compare for correctness so far. The overhead was irrelevant, even across the 2,000 steps the overhead wouldn’t amount to more than 10 seconds.
The first step that took longer than a second was step 596, working on a 58 digit number. All the first 595 steps took less than a second each. The first step that took more than a minute, was step 751, a 76 digit number, taking 62 seconds, factorizing 3,846,326,269,123,604,249,534,537,245,589,642,779,527,836,356,985,238,147,044,691,944,551,978,095,188. The next step was done in 33 milliseconds.
The first 822 steps took an hour. Step 856 was reached after two hours, so that’s another 34 steps in the second hour. Unexpectedly, things slowed down again. Using faster machines, modern architectures, GPUs, TPUs, potentially better algorithms, such as CADO-NFS or GGNFS, all of that could speed that up by a lot, but I am happy how far I’ve gotten with, uhm, little effort. After 10 hours, we had 943 steps and a 92 digit number, 20 hours to get to step 978 and 95 digits. My goal was to reach step 1,000, and then publish this post and call it a day. By then, a number of steps already took more than an hour to compute. I hit step 1000 after about 28 and a half hours, a 96 digit number: 162,153,732,827,197,136,033,622,501,266,547,937,307,383,348,339,794,415,105,550,785,151,682,352,044,744,095,241,669,373,141,578.
I rationalize this all through “I had fun” and “I learned something about JavaScript, Node, and WebAssembly that will be useful for my job too”. But really, it was just one of these rabbit holes that I love to dive in. And if you read this post so far, you seem to be similarly inclined. Thanks for reading, and I hope I didn’t steal too much of your time.
I also posted a list of all the numbers I calculated so far, because I couldn’t find that list on the Web, and I found the list I found helpful. Maybe it will be useful for something. I doubt it. (P.S.: the list was already on the Web, I just wasn't looking careful enough. Both, OEIS and FactorDB have the full list.)
I don’t think any of the lessons here are surprising:
- for many problems a naïve algorithm will take you to a good start, and might be sufficient
- but never fight against an exponential algorithm that gets big enough, with constant speedups such as faster hardware. It’s a losing proposition
- But hey, first wait if it gets big enough! Many problems with exponential complexity are perfectly solvable with naïve approaches if the problem stays small enough
- better algorithms really make a difference
- use existing libraries!
- advancing research is hard
- WebAssembly is really cool and you should learn more about it
- the state of WebAssembly out there can still be wacky, and sometimes you need to hack around to get things to work
In the meantime I played a bit with other numbers (thanks to having a 4 core computer!), and I will wager one ambitious hypothesis: if 276 diverges, so does 276,276, 276,276,276, 276,276,276,276, etc., all the way to 276,276,276,276,276,276,276,276,276, i.e. 9 times "276".
I know that 10 times "276" converges after 300 steps, but I have tested all the other "lexical multiples" of 276, and reached 70 digit numbers after hundreds of steps. For 276,276 I pushed it further, reaching 96 digits at step 640. (And for at least 276,276 we should already know the current best answer, because the Wikipedia article states that all the numbers under one million have been calculated, and only about 9,000 have an unclear fate. We should be able to check if 276,276 is one of those, which I didn't come around to yet).
Again, this is not research, but just fooling around. If you want actual systematic research, the Wikipedia article has a number of great links.
Thank you for reading so far!
P.S.: Now that I played around, I started following some of the links, and wow, there's a whole community with great tools and infrastructure having fun about Aliquot sequences and prime numbers doing this for decades. This is extremely fascinating.
The Surrounding Sea
Explore the ocean of words in which we all are swimming, day in day out. A site that allows you to browse through the lexicographic data in Wikidata along four dimensions:
- alphabetical, like in a good old fashioned dictionary
- through translations and synonyms
- where does this word come from, and where did it go
- narrower and wider words, describing a hierarchy of meanings
Wikidata contains over 1.2 million lexicographic entries, but you will see the many gaps when exploring the sea of words. Please join us in charting out more of the world of words.
Happy 23rd birthday to Wikipedia and the movement it started!
Das Mädchen Doch
Sie sagten ihrer Mutter
Kinder werde sie nie haben
Und als sie geboren wurde
Nannte ihre Mutter sie
Doch
Sie sagten sie sei schwach
Und klein und krank
Und dass sie nicht
Lange zu leben habe
Doch
Ihre Mutter hoffte
Das sie in einer Welt aufwuchs
In der alle gleich behandelt wurden
Aber leider
Doch
Sie sagten Mathe und Autos
Seien nichts für Mädchen
Dass sie sich interessiert
Für Puppen und für Kleidung
Doch
Sie sagten die Welt
Ist wie sie ist
Und sie zu ändern
Sei nichts für kleine kranke Mädchen
Doch
Sie sagten gut dass Du darüber sprachst
Wir sollten darüber nachdenken
Lass uns jetzt darüber debattieren
Und wir (nicht Du) entscheiden dann
Doch
Sie sagten man kann nicht alles haben
Man muss sich entscheiden
Aber so selbstsüchtig
Ich meine, keine Kinder zu wollen
Doch
Sie sagten sie sei unanständig
So ein Leben sei nicht richtig
Benannten sie mit unanständigen Worten
Was sie sich denn erlaube
Doch
Sie sagten das geht doch nicht
So ein Leben sei kein Leben
Das ist jetzt schon sehr anders
Das ist nicht einfach nur Neid
Doch
Sie sagten wir sind halt nicht so
Und wollen auch nicht so sein
Wir sind glücklich wie wir sind
Und deswegen darfst du glücklich nicht sein
Doch
Languages with the best lexicographic data coverage in Wikidata 2023
Languages with the best coverage as of the end of 2023
- English 92.9%
- Spanish 91.3%
- Bokmal 89.1%
- Swedish 88.9%
- French 86.9%
- Danish 86.9%
- Latin 85.8%
- Italian 82.9%
- Estonian 81.2%
- Nynorsk 80.2%
- German 79.5%
- Basque 75.9%
- Portuguese 74.8%
- Malay 73.1%
- Panjabi 71.0%
- Slovak 67.8%
- Breton 67.3%
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data.
The list contains all languages where the data covers more than two thirds of the selected corpus.
Progress in lexicographic data in Wikidata 2023
Here are some highlights of the progress in lexicographic data in Wikidata in 2023
- Greek jumped from 0% to 45% right away
- Panjabi jumped right away from 0% to 71% (but on an admittedly small corpus)
- Italian made a huge jump from 52% to 82% by increasing the number of forms from 9,000 to 286,000
- Turkish jumped from 0.9% to 22%
- Sindhi climbed from 15% to 25%
- Farsi climbed from 15% to 24% increasing the number of forms from 4,000 to 33,000
- Western Panjabi climbed from 36.9% to 47.9%
- Hindi climbed from 49.9% to 65.9%
- Breton increased from 56% to 67%
- Croatian increased from 40% to 45%
- Dutch went from 20% to 29%
- French from 82.9% to 86.9%, mostly by dealing better with apostrophes in the analysis
- Nynorsk pushed from 75% to 80% by increasing the number of forms from 18,000 to 68,000
- Danish from 83.9% to 86.9% by increasing the number of forms in Wikidata from 65,000 to 170,000
- German from 76% to 79% by increasing the number of forms in Wikidata from 90,000 to 200,000
- Spanish pushed from 88% to 91% by increasing the number of forms from 280,000 to 430,000
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data. Note that every percent more gets much more difficult than the previous one: an increase from 1% to 2% usually needs much much less work than from 91% to 92%.
RIP Niklaus Wirth
RIP Niklaus Wirth;
BEGIN
I don't think there's a person who created more programming languages that I used than Wirth: Pascal, Modula, and Oberon; maybe Guy Steele, depending on what you count;
Wirth is also famous for Wirth's law: software becomes slower more rapidly than hardware becomes faster;
He received the 1984 Turing Award, and had an asteroid named after him in 1999; Wirth died at the age of 89;
END.
Wikidata lexicographic data coverage for Croatian in 2023
Last year, I published ambitious goals for the coverage of lexicographic data for Croatian in Wikidata. My self-proclaimed goal was widely missed: I wanted to go from 40% coverage to 60% -- instead, thanks to the help of contributors, we reached 45%.
We grew from 3,124 forms to 4,115, i.e. almost a thousand new forms, or about 31%. The coverage grew from around 11 million tokens to about 13 million tokens in the Croatian Wikipedia, or, as said, from 40% to 45%. The covered forms grew from 1.4% to 1.9%, which illustrates neatly the increased difficulty to reach more coverage (thanks to Zipf's law): last year, we increased covered forms by 1%, which translated to an overall coverage increase of occurrences by 35%. This year, although we increased the covered forms by another 0.5%, we only got an overall coverage increase of occurrences by 5%.
But some of my energy was diverted from adding more lexicographic data to adding functions that help with adding and checking lexicographic data. We launched a new project, Wikifunctions, that can hold functions. There, we collected functions to create the regular forms for Croatian nouns. All nouns are now covered.
I think that's still a great achievement and progress. Sure, we didn't meet the 60%, but the functions helped a lot to get to the 45%, and they will continue to benefit us 2024 too. Again, I want to declare some goals, at least for myself, but not as ambitious with regards to coverage: the goal for 2024 is to reach 50% coverage of Croatian, and in addition, I would love us to have Lexeme forms available for verbs and adjectives, not only for nouns, (for verbs, Ivi404 did most of the work already), and maybe even have functions ready for adjectives.
Star Trek's 32nd century
I like Star Trek for the cool technology, which has inspired plenty of people to work eg on "the Star Trek computer". I love Star Trek for the utopian society of plenty they sketch in the 23rd and 24th century.
I claim it is because of the laziness of the writing: they don't keep that utopia up.
When I heard about Discovery going to the 32nd century, I was excited about the wonders they would dream up. The new technology. The society. The culture. The breakthroughs.
With regards to that, it was a massive let down. Extremely disappointing.
Finding God through Information Theory
I found that surprising: Luciano Floridi, one of the most-cited living philosophers, started studying information theory because young Floridi, still Catholic, concluded that God's manifestation to humanity must be an information process. He wanted to understand God's manifestation through the lens of information.
He didn't get far in answering that question, but he did become the leading expert in the Philosophy of Information, and an expert in Digital Ethics (and also, since then, an agnostic).
Post scriptum: The more I think about it, the more I like the idea. Information theory is not even one of these vague, empirical disciplines such as Physics, but more like Mathematics and Logics, and thus unavoidable. Any information exchange, i.e. communication, must follow its rules. Therefore the manifestation of God, i.e. the way God chooses to communicate themselves to us, must also follow information theory. So this should lead to some necessary conditions on the shape of such a manifestation.
It's a bright idea. I am not surprised it didn't go anywhere, but I still like the idea.
Could have at least engendered a novel Proof for the Existence of God. They have certainly come from more surprising corners.
Source: https://philosophy.fireside.fm/1
More about Luciano Flordi on Wikipedia.
Little One's first GIF
Little One made her first GIF!

Moving to Germany
We are moving to Germany. It was a long and difficult decision process.
Is it the right decision? Who knows. These kinds of decisions are rarely right or wrong, but just are.
What about your job? I am thankful to the Wikimedia Foundation for allowing me to move and keep my position. The work on Abstract Wikipedia and Wikifunctions is not done yet, and I will continue to lead the realization of this project.
Don’t we like it in California? We love so many things about California and the US, and the US has been really good to us. Both my wife and I grew here in our careers, we both learned valuable skills, and met interesting people, some of whom became friends, and who I hope to continue to keep in touch. Particularly my time at Google was also financially a boon. And it also gave me the freedom to prepare for the Abstract Wikipedia project, and to get to know so many experts in their field and work together with them, to have the project criticized and go through several iterations until nothing seems obviously wrong with it. There is no place like the Bay Area in the world of Tech. It was comparably easy to have meetings with folks at Google, Facebook, Wikimedia, LinkedIn, Amazon, Stanford, Berkeley, or to have one of the many startups reach out for a quick chat. It is, in many ways, a magical place, and no other place we may move to will come even close to it with regards to its proximity to tech.
And then there’s the wonderful weather in the Bay Area and the breathtaking nature of California. It never gets really hot, it never gets really cold. The sun is shining almost every day, rain is scarce (too scarce), and we never have to drive on icy streets or shovel snow. If we want snow, we can just drive up to the Sierras. If we want heat, drive inland. We can see the largest trees in the world, walk through the literal forests of Endor, we can hike hills and mountains, and we can walk miles and miles along the sand beaches of the Pacific Ocean. California is beautiful.
Oh, and the food and the produce! Don’t get me started on Berkeley Bowl and its selection of fruits and vegetables. Of the figs in their far too short season, of the dry-farmed Early Girl tomatoes and their explosion of taste, of the juicy and rich cherries we picked every year to carry pounds and pounds home, and to eat as many while picking, the huge diversity of restaurants in various states from authentic to fusion, but most of them with delicious options and more dishes to try than time to do it.
And not just the fruits and vegetables are locally sourced: be it computers from Apple, phones from Google, the social media from Facebook or Twitter, the wonderful platform enabling the Wikimedia communities, be it cars from Tesla, be it movies from Pixar, the startups, the clouds, the AIs: so. many. things. are local. And every concert tour will pass by in the Bay Area. In the last year we saw so many concerts here, it was amazing. That’s a place the tours don’t skip.
Finally: in California, because so many people are not from here, we felt more like we belong just as well as everyone else, than anywhere else. Our family is quite a little mix, with passports from three continents. Our daughter has no simple roots. Being us is likely easier in the United States than in any of the European nation states with their millenia of identity. After a few years I felt like an American. In Germany, although it treated me well, after thirty years I still was an Ausländer.
As said, it is a unique place. I love it. It is a privilege and an amazing experience to have spent one decade of my life here.
Why are we moving? In short, guns and the inadequate social system.
In the last two years alone, we had four close-ish encounters with people wielding guns (not always around home). And we are not in a bad neighborhood, on the contrary. This is by all statistics one of the safest neighborhoods you will find in the East Bay or the City.
We are too worried to let the kid walk around by herself or even with friends. This is such a huge difference to how I grew up, and such a huge difference to when we spent the summer in Croatia, and she and other kids were off by themselves to explore and play. Here, there was not a single time she went to the playground or visited a friend by herself, or that one of her friends visited our house by themselves.
But even if she is not alone: going to the City with the kid? There are so many places there I want to avoid. Be it around the city hall, be it in the beautiful central library, be it on Market Street or even just on the subway or the subway stations: too often we have to be careful to avoid human excrement, too often we are confronted with people who are obviously in need of help, and too often I feel my fight or flight reflexes kicking in.
All of this is just the visible effect of a much larger problem, one that we in the Bay Area in particular, but as Americans in general should be ashamed of not improving: the huge disparity between rich and poor, the difficult conditions that many people live in. It is a shame that so many people who are in dire need of professional help live on the streets instead of receiving mental health care, that there are literal tent cities in the Bay Area, while the area is also the home of hundreds of thousands of millionaires and more than sixty billionaires - more than the UK, France, or Switzerland. It is a shame that so many people have to work two or more jobs in order to pay their rent and feed themselves and their children, while the median income exceeds $10,000 a month. It is a shame that this country, which calls itself the richest and most powerful and most advanced country in the world, will let its school children go hungry. Is “school lunch debt” a thing anywhere else in the world? Is “medical bankruptcy” a thing anywhere else in the world? Where else are college debts such a persistent social issue?
The combination of the easy availability of guns and the inadequate social system leads to a large amount of avoidable violence and to tens of thousands of seemingly avoidable deaths. And they lead to millions of people unnecessarily struggling and being denied a fair chance to fulfill their potential.
And the main problem, after a decade living here, is not where we are, but the trajectory of change we are seeing. I don’t have hope that there will be a major reduction in gun violence in the coming decade, on the contrary. I don’t have hope for any changes that will lead to the Bay Area and the US spreading the riches and gains it is amassing substantially more fairly amongst its population, on the contrary. Even the glacial development in self-driving cars seems breezy compared to the progress towards killing fewer of our children or sharing our profits a little bit more fairly.
After the 1996 Port Arthur shooting, Australia established restrictions on the use of automatic and semi-automatic weapons, created a gun buyback program that removed 650,000 guns from circulation, a national gun registry, and a waiting period for firearms sales. They chose so.
After the 2019 Christchurch shooting, New Zealand passed restrictions on semi-automatic weapons and a buyback program removed 50,000 guns. They chose so.
After the shootings earlier this year in Belgrade, Serbia introduced stricter laws and an amnesty for illegal weapons and ammunition if surrendered, leading to more than 75,000 guns being removed. They chose so.
I don’t want to list the events in the US. There are too many of them. And did any of them lead to changes? We choose not to.
We can easily afford to let basically everyone in the US live a decent life and help those that need it the most. We can easily afford to let no kid be hungry. We can easily afford to let every kid have a great education. We choose not to.
I don’t want my kid to grow up in a society where we make such choices.
I could go on and rant about the Republican party, about Trump possibly winning 2024, about our taxes supporting and financing wars in places where they shouldn’t, about xenophobia and racism, about reproductive rights, trans rights, and so much more. But unfortunately many of these topics are often not significantly better elsewhere either.
When are we moving? We plan to stay here until the school year is over, and aim to have moved before the next school year starts. So in the summer of ‘24.
Where are we moving? I am going back to my place of birth, Stuttgart. We considered a few options, and Stuttgart led overall due to the combination of proximity to family, school system compatibility for the kid, a time zone that works well for the Abstract Wikipedia team, language requirements, low legal hurdles of moving there, and the cost of living we expect. Like every place it also comes with challenges. Don’t get me started on the taste of tomatoes or peaches.
What other places did we consider? We considered many other places, and we traveled to quite a few of them to check them out. We loved each and every one of them. We particularly loved Auckland due to our family there and the weather, we loved the beautiful city of Barcelona for its food and culture, we loved Dublin, London, Zürich, Berlin, Vienna, Split. We started making a large spreadsheet with pros and contras in many categories, but in the end the decision was a gut decision. Thanks to everyone who talked with us and from whom we learned a lot about those places!
Being able to even consider moving to these places is a privilege. And we understand that and are thankful for having this privilege. Some of these places would have been harder to move for us due to immigration regulation, others are easy thanks to our background. But if you are thinking of moving, and are worried about certain aspects, feel free to reach out and discuss. I am happy to offer my experience and perspective.
Is there something you can help with? If you want to meet up with us while we are still in the US, it would be good to do so timely. We are expecting to sell the house quite a bit sooner, and then we won’t be able to host guests easily. I am also looking forward to reconnecting with people in Europe after the move. Finally, if you know someone who is interested in a well updated 3 bedroom house with a surprisingly large attic that can be used as a proper hobby space, and with a top walkability index in south Berkeley, point them our way.
Also, experiences and advice regarding moving from the US to Germany are welcome. Last time we moved the other way, and we didn’t have that much to move, and Google was generously organizing most of what needed to be done. This time it’s all on us. How to get a container and get it loaded? How to ship it to Germany? Where to store it while we are looking for a new home? How to move the cat? How to make sure all goes well with the new school? When to sell the house and where to live afterwards? How to find the right place in Germany? What are the legal hurdles to expect? How will taxes work? So many questions we will need to answer in the coming months. Wish us luck for 2024.
We also accept good wishes and encouraging words. And I am very much looking forward to seeing some of you again next year!
Sam Altman and the veil of ignorance
(This is not about Altman having been removed as CEO of OpenAI)
During the APEC forum on Thursday, Sam Altman has been cited to having said the following thing: "Four times now in the history of OpenAI—the most recent time was just in the last couple of weeks—I’ve gotten to be in the room when we push the veil of ignorance back and the frontier of discovery forward. And getting to do that is like the professional honor of a lifetime."
He meant that as an uplifting quote to describe how awesome his company and their achievements are.
I find it deeply worrying. Why?
The "veil of ignorance" (also known as the original position) is a thought experiment introduced by John Rawls, one of the leading American moral and political philosophers of the 20th century. The goal is to think about the fairness of a society or a social system without you knowing where in the system you end up: are you on top or at the bottom? What are your skills, your talents? Who are your friends? Do you have disabilities? What is your gender, your family history?
The whole point is to *not* push the veil of ignorance back, otherwise you'll create an unfair system. It is a good tool to think about the coming disruptions by AI technology.
The fact that he's using that specific term but is obviously entirely oblivious to its meaning tells us that there was a path that term took, probably from someone working on ethics to then-CEO Altman, and that someone didn't listen. The meaning was lost, and the beautiful phrase was entirely repurposed.
Given that's coming from the then-CEO of the company that claims and insists on, again and again (without substantial proof) that they are doing all this for the greater benefit of all humanity, that are, despite their name, increasingly closing their results, making public scrutiny increasingly difficult if not impossible - well, I find that worrying. The quote indicates that they have no idea about a basic tool towards evaluating fairness, even worse, have heard about it - but they have not listened or comprehended.
Babel
Strong recommendation for "Babel" by R.F. Kuang. It's a speculative fiction story set in 1830s Oxford with an, as far as I can tell, novel premise: one can cast spells (although they don't call it spells but it's just science in this world) by using two words that translate into each other, and the semantic difference between the two words - because no translation is perfect - is the effect of the spell. But the effect can only be achieved if you have a speaker who's fluent enough in both languages to have a native understanding of the difference.
One example would be the French parcelle and the English parcel, both meaning package, but the French still carries some of the former "to split into parts", with the effect that packages are lighter and easier to transport for the Royal Mail.
The story remains comfortable for the first half of the volume, with beautiful world building, character drawing, and the tranquil academic life of Oxford students, but then it suddenly picks up speed, and we can experience the events unfold with a merciless speed. The end is just in the right place, and it leaves me to yearn to revisit this world and the desire to learn what happened next.
The volume discusses some heavy topics - colonialism, dependency on technology, fairness, what is allowed in a revolution, the "neutrality" of science - and while we are still in the first half of the volume, it feels very on the nose, very theoretical - but that changes dramatically as we swing into the second half of the volume, and suddenly all these theoretical discussions become very immediate. Which does remind me of student life, where discussions about different political systems and abstract notions of justice are just as prevalent and as consequence-free as they seem to be here, at first.
The book was recommended by the Lingthusiasm podcast, which is how I found it.
I came for the linguistic premise, but I stayed for the characters and their fates in a colonial world.
Existential crises
I think the likelihood of AI killing all humans is bigger than the likelihood of climate change killing all humans.
Nevertheless I think that we should worry and act much more about climate change than about AI.
Allow me to explain.
Both AI and climate change will, in this century, force changes to basically every aspect of the lives of basically every single person on the planet. Some people may benefit, some may not. The impact of both will be drastic and irreversible. I expect the year 2100 to look very different from 2000.
Climate change will lead to billions of people to suffer, and to many deaths. It will destroy the current livelihoods of many millions of people. Many people will be forced to leave their homes, not because they want to, but because they have to in order to survive. Richer countries with sufficient infrastructure to deal with the direct impact of a changed climate will have to decide how to deal with the millions of people who want to live and who want their children not to die. We will see suffering on a scale never seen before, simply because there have never been this many humans on the planet.
But it won't be an existential threat to humanity (the word humanity has at least two meanings: 1) the species as a whole, and 2) certain values we associate with humans. Unfortunately, I only refer to the first meaning. The second meaning will most certainly face a threat). Humanity will survive, without a doubt. There are enough resources, there are enough rich and powerful people, to allow millions of us to shelter away from the most life threatening consequences of climate change. Millions will survive for sure. Potentially at the costs of many millions lives and the suffering of billions. Whole food chains, whole ecosystems may collapse. Whole countries may be abandoned. But humanity will survive.
What about AI? I believe that AI can be a huge boon. It may allow for much more prosperity, if we spread out the gains widely. It can remove a lot of toil from the life of many people. It can make many people more effective and productive. But history has shown that we're not exactly great at sharing gains widely. AI will lead to disruptions in many economic sectors. If we're not careful (and we likely aren't) it might lead to many people suffering from poverty. None of these pose an existential threat to humanity.
But there are outlandish scenarios which I think might have a tiny chance of becoming true and which can kill every human. Even a full blown Terminator scenario where drones hunt every human because the AI has decided that extermination is the right step. Or, much simpler, that in our idiocy we let AI supervise some of our gigantic nuclear arsenal, and that goes wrong. But again, I merely think these possible, but not in the slightest likely. An asteroid hitting Earth and killing most of us is likelier if you ask my gut.
Killing all humans is a high bar. It is an important bar for so called long-termists, who may posit that the death of four or five billion people isn't significant enough to worry about, just a bump in the long term. They'd say that they want to focus on what's truly important. I find that reasoning understandable, but morally indefensible.
In summary: there are currently too many resources devoted to thinking about the threat of AI as an existential crisis. We should focus on the short term effect of AI and aim to avoid as many of the negative effects as possible and to share the spoils of the positive effects. We're likely to end up with socializing the negative effects, particularly amongst the weakest members of society, and privatizing the benefits. That's bad.
We really need to devote more resources towards avoiding climate change as far as still possible, and towards shielding people and the environment from the negative effects of climate change. I am afraid we're failing at that. And that will cause far more negative impact in the course of this century than any AI will.
Wikidata crossed 2 billion edits
The Wikidata community edited Wikidata 2 billion times!
Wikidata is, to the best of my knowledge, the first and only wiki to cross 2 billion edits (the second most edited one being English Wikipedia with 1.18 billion edits).
Edit Nr 2,000,000,000 was adding the first person plural future of the Italian verb 'grugnire' (to grunt) by user Luca.favorido.
Wikidata also celebrated 11 years since launch with the hybrid WikidataCon 2023 in Taipei last weekend.
It took from 2012 to 2019 to get the first billion, and from 2019 to now for the second. As they say, the first billion is the hardest.
That the two billionth edit happens right on the Birthday is a nice surprise.
The letter Đ
The letter Đ was introduced to Serbo-Croatian by Đuro Daničić, according to Wikipedia. I found that highly amusing, that he introduced the letter that is the first letter in his name.
Wikipedia also claims that he was born Đorđe Popović, and all I can think of is "nah, that can't be right".
That would be like Jebediah Springfield who was born in a cabin that he helped build.
Pastir Loda
Vladimir Nazor is likely the most famous author from the island of Brač, the island my parents are from. His most acclaimed book seems to be Pastir Loda, Loda the Shepherd. It tells the story of a satyr that, through accidents and storms, was stranded on the island of Brač, and how he lived on Brač for the next almost two thousand years.
It is difficult to find many of his works, they are often out of print. And there isn't much available online, either. Since Nazor died in 1949, his works are in the public domain. I acquired a copy of Pastir Loda from an antique book shop in Zagreb, which I then forwarded to a friend in Denmark who has a book scanner, and who scanned the book so I can make the PDF available now.
The book is written in Croatian. There is a German translation, but that won't get into the public domain until 2043 (the translator lived until 1972), and according to WorldCat there is a Czech translation, and according to Wikipedia a Hungarian translation. For both I don't know who the translator is, and so I don't know the copyright status of these translations. I also don't know if the book has ever been translated to other languages.
I wish to find the time to upload and transcribe the content on Wikisource, and then maybe even do a translation of it into English. For now I upload the book to archive.org, and I also make it available on my own Website. I want to upload it to Wikimedia Commons, but I immediately stumbled upon the first issue, that it seems that to upload it to Commons the book needs to be published before 1928 and the author has to be dead for more than 70 years (I think that should be an or). I am checking on Commons if I can upload it or not.
Until then, here's the Download:
F in Croatian
I was writing some checks to find errors in the lexical data in Wikidata for Croatian, and one of the things I tried was to check whether the letters in the words are all part of the Croatian alphabet. But instead of just taking a list, or writing down from memory, I looked at the data, and added letter after letter. And then I was surprised to find that the letter "f" only appears in loanwords. And I look it up in the Croatian Encyclopedia and it simply states that "f" is not a letter of the old slavic language.
I was mindblown. I speak this language since I can remember, and i didn't notice that there is no "f" but in loanwords. And "f" seems like such a fundamental sound! But no, wrong!
If you speak a slavic language, do you have the letter "f"?
Do you hear the people sing?
"Do you hear the people sing, singing the song of angry men..."
Yesterday, a London performance of Les Miserables was interrupted by protesters raising awareness about climate change.
The audience booed.
It seems the audience was unhappy about having to experience protests and unrest during the performance of protests and unrest they wanted to enjoy.
The hypocrisy is rich in this one, but a very well engineered and expected one. But I guess only with the luxury of being detached from the actual event one can afford to enjoy the hypocrisy. I assume that for many people attending a West End London production of Les Miserables aims to be a proper highlight of the year, if not more. It's something that children gift their parents for the 30th wedding anniversary. It may be the reason for a trip to London. In addition, attending a performance like this is an escapist act, that you don't want interrupted with the problems of the real world. And given that it is a life performance, it seems disrespectful to the cast, to the artists, who pour their lives into their roles.
On the other side, the existential dread about climate change, and the insufficient actions by world leaders seem to demand increasingly bolder action and more attention. We are teaching our kids that they should act if something is not right. And we are telling them about the predictions for climate change. And then we are surprised if they try to do something? The message that climate change will be extremely disruptive to our lives and that we need to act much more decisively has obviously not yet been understood by enough people. And we, humanity, our leaders, elected or not, are most certainly not yet doing enough to try to prevent or at least mitigate the effects of climate change that are starting to roll over us.
It would be good, but admittedly unlikely, if both sides could appreciate the other more. Maybe the audience might be a bit appreciative of seeing the people sing the song of angry men in real. And maybe the protesters could choose their targets a bit more wisely. Why choose art? There are more disruptive targets if you were to protest the oil industry than a performance of Les Miserables. To be honest, if i were working for the oil industry, this is exactly the kind of actions I would be setting up. And with people who are actually into the cause. That way I can ensure that people will talk about interrupted theater productions and defaced paintings, instead of again having the hottest year in history, of floods, heatwaves, hurricanes, and the thousands of people who already died due to climate change induced catastrophes - and the billions more whose life will be turned upside down.
Immortal relationships
I saw a beautiful meme yesterday that said that from the perspective of a cat or dog, humans are like elves who live for five hundred years and yet aren't afraid to bond with them for their whole life. And it is depicted as beautiful and wholesome.
It's so different from all those stories of immortals, think of Vampires or Highlander or the Sandman, where the immortals get bitter, or live in misery and loss, or become aloof and uncaring about human lives and their short life spans, and where it hurts them more than it does them good.
There seem to be more stories exploring the friendship of immortals with short-lived creatures, be it in Rings of Power with the relationship of Elrond and Durin, be it the relation of Star Trek's Zora with the crew of the Discovery or especially with Craft in the short movie Calypso, or between the Eternal Sersi and Dane Whitman. All these relations seem to be depicted more positively and less tragic.
In my opinion that's a good thing. It highlights the good parts in us that we should aspire to. It shows us what we can be, based in a very common perception, the relationship to our cats and dogs. Stories are magic, in it's truest sense. Stories have an influence on the world, they help us understand the world, imagine the impact we can have, explore us who we can be. That's why I'm happy to see these more positive takes on that trope compared to the tragic takes of the past.
(I don't know if any of this is true. I think it would require at least some work to actually capture instances of such stories, classify and tally them, to see if that really is the case. I'm not claiming I've done that groundwork, but just capture an observation that I'd like to be true, but can't really vouch for it.)
Molly Holzschlag (1963-2023)
May her memory be a blessing.
She taught the Web to many, and she fought for the Web of many.
Doug Lenat (1950-2023)
When I started studying computer science, one of the initiation rites was to read the Jargon File. I stumbled when I read the entry on the microlenat:
microlenat: The unit of bogosity. Abbreviated μL, named after Douglas Lenat. Like the farad it is considered far too large a unit for practical use, so bogosity is usually expressed in microlenats.
I had not heard of Douglas Lenat then. English being my third language, I wasn’t sure what bogosity is. So I tried to learn a bit more to understand it, and I read a bit about Cyc and Eurisko, but since I just started computer science, my mind wasn’t really ready for things such as knowledge representation and common sense reasoning. I had enough on my plate struggling with resistors, electronegativity, and fourier transformations. Looking back, it is ironic that none of these played a particular role in my future, but knowledge representation sure did.
It took me almost ten years to come back to Cyc and Lenat’s work. I was then studying ontological engineering, a term that according to Wikipedia was coined by Lenat, a fact I wasn’t aware of at that time. I was working with RDF, which was co-developed by Guha, who has worked with Lenat at Cycorp, a fact I wasn’t aware of at that time. I was trying to solve problems that Lenat had tackled decades previously, a fact I wasn’t aware of at that time.
I got to know Cyc through OpenCyc and Cyc Europe, led by Michael Witbrock. I only met Doug Lenat a decade later when I was at Google.
Doug’s aspirations and ambitions had numerous people react with rolling eyes and sneering comments, as can be seen in the entry in the Jargon File. And whereas I might have absorbed similar thoughts as well, they also inspired me. I worked with a few people who told me “consider yourself lucky if you have a dozen people reading your paper, that’s the impact you will likely have”, but I never found that a remotely satisfactory idea. Then there were people like Doug, who shouted out “let’s solve common sense!”, and stormed ahead trying to do so.
His optimism and his bias to action, his can-do attitude, surely influenced me profoundly in choosing my own way forward. Not only once did I feel like I was channeling Lenat when I was talking about knowledge bases that anyone can edit, about libraries of functions anyone can use, or about abstract representations of natural language texts. And as ambitious as these projects have been called, they all carefully avoid the incomparably more ambitious goals Doug had his eyes set on.
And Doug didn’t do it from the comfort of a tenured academic position, but he bet his career and house on it, he founded a company, and kept it running for four decades. I was always saddened that Cyc was kept behind closed doors, and I hope that this will not hinder the impact and legacy it might have, but I understand that this was the magic juice that kept the company running.
One of Doug’s systems, Eurisko, became an inspiration and namesake for an AI system that played the role of the monster of the week in a first season episode of the X-Files, a fact I wasn’t aware of until now. Doug was a founder and advisory member of the TTI/Vanguard series of meetings, to which I was invited to present an early version of Abstract Wikipedia, a fact I wasn’t aware of until now. And I am sure there are more facts about Doug and his work and how it reverberated with mine that I am unaware of still.
Doug was a person ahead of their time, a person who lived, worked on and saw a future about knowledge that is creative, optimistic and inspiring. I do not know if we will ever reach that future, but I do know that Doug Lenat and his work will always be a beacon on our journey forward. Doug Lenat died yesterday in Austin, Texas, two weeks shy of his 73rd birthday, after a battle with cancer.
To state it in CycL, the language Cyc is written in:
(#$dateOfDeath #$DougLenat "2023-08-31")
(#$restInPeace #$DougLenat)
Butter
So, I went to the store with Little One today, and couldn't find the butter.
I ask the person at the cheese stand, who points me to the burrata. Tasty, but not what I'm looking for. I ask again and he sends me to the bread section.
I can't find it at the bread section, so I ask the person at the pastries stand where the butter is. She points me to the bagels. I say no, butter. She says, ah, there, pointing to the bathrooms. I'm getting exasperated, and I ask again. She points back to the cheeses with the burrata. I try again. She gets a colleague, and soon they both look confused.
Finally my daughter chimes in, asking for the butter. They immediately point her to the right place and we finally get the butter.
I haven't been so frustrated about my English pronunciation since I tried to buy a thermometer.
The Jones Brothers
The two Jones brothers never got along, but both were too stubborn to leave the family estate. They built out two entrances to the estate, one from the south, near Jefferson Avenue, and the newer, bigger one, closer to the historic downtown, and each brother chose to use one of the entrances exclusively, in order to avoid the other and their family. To the confusion of the local folk (but to the open enjoyment of the high school's grammar teacher, who was, surprisingly for his role, a descriptivist), they named the western gate the Jones' gate, and the southern one the Jones's gate, and the brothers earnestly thought that that settled it.
It didn't.
The Future of Knowledge Graphs in a World of Large Language Models
The Knowledge Graph Conference 2023 in New York City invited me for a keynote on May 11, 2023. Given that basically all conversations these days are about large language models, I have given a talk about my understanding on how knowledge graphs and large language models go together.
After the conference, I did a recording of the talk, giving it one more time, in order to improve the quality of the recording. The talk had gotten more than 10,000 views on YouTube so far, which, for me, is totally astonishing.
I forgot to link it here, so here we go finally:
Hot Skull
I watched Hot Skull on Netflix, a Turkish Science Fiction dystopic series. I knew there was only one season, and no further seasons were planned, so I was expecting that the story would be resolved - but alas, I was wrong. And the book the show is based on is only available in Turkish, so I wouldn't know of a way to figure out how the story end.
The premise is that there is a "semantic virus", a disease that makes people 'jabber', to talk without meaning (but syntactically correct), and to be unable to convey or process any meaning anymore (not through words, and very limited through acts). They seem also to loose the ability to participate in most parts of society, but they still take care of eating, notice wounds or if their loved ones are in distress, etc. Jabbering is contagious, if you hear someone jabber, you start jabbering as well, jabberers cannot stop talking, and it quickly became a global pandemic. So they are somehow zombieish, but not entirely, raising questions about them still being human, their rights, etc. The hero of the story is a linguist.
Unfortunately, the story revolves around the (global? national?) institution that tries to bring the pandemic under control, and which has taken over a lot of power (which echoes some of the conspiracy theories of the COVID pandemic), and the fact that this institution is not interested in finding a cure (because going back to the former world would require them to give back the power they gained). The world has slid into economic chaos, e.g. getting chocolate becomes really hard, there seems to be only little international cooperation and transportation going on, but there seems to be enough food (at least in Istanbul, where the story is located). Information about what happened in the rest of the world is rare, but everyone seems affected.
I really enjoyed the very few and rare moments where they explored the semantic virus and what it does to people. Some of them are heart-wrenching, some of them are interesting, and in the end we get indications that there is a yet unknown mystery surrounding the disease. I hope the book at least resolves that, as we will probably never learn how the Netflix show was meant to end. The dystopic parts about a failing society, the whole plot about an "organization taking over the world and secretly fighting a cure", and the resistance to that organization, is tired, not particularly well told, standard dystopic fare.
The story is told very slowly and meanders leisurely. I really like the 'turkishness' shining through in the production: Turkish names, characters eating simit, drinking raki, Istanbul as a (underutilized) background, the respect for elders, this is all very well meshed into the sci-fi story.
No clear recommendation to watch, mostly because the story is unfinished, and there is simply not enough payoff for the lengthy and slow eight episodes. I was curious about the premise, and still would like to know how the story ends, what the authors intended, but it is frustrating that I might never learn.
The right to work
I've been a friend of Universal Basic Income for thirty years, but in the last twenty years, I have growing reservations about it, and many questions. This article about an experiment with a right to work was the first text in a while I read on it that substantially impacted my thinking on this (text is in German). I recommend reading it.
Work is not just a source of money, but for many also a source of meaning, pride, structure, motivation, social connections. Having voluntary access to work seems to be one major component that is necessary on a societal level, in addition to a universal basic income that allows that everyone can live in dignity. Note: I think work should be widely construed. If someone has something that fills that need, that's work. Raising children, taking care of a garden, writing a book, refining piano skills, creating art, taking care of others, taking care of yourself, all these easily count as work in my book.
I wish we were willing and able to experiment with different ways of structuring society as we are willing and able to experiment with technology. We deployed the Internet to the world without worrying about the long term consequences, but we're cautious about giving everyone enough money to not be hungry. That's just broken. I was always disappointed about the fact that sociology and politics as studied and taught by academia were mostly descriptive and not constructive endeavors.
Wikidata - The Making of
Markus Krötzsch, Lydia Pintscher and I wrote a paper on the history of Wikidata. We published it in the History of the Web track at The Web Conference 2023 in Austin, Texas (what used to be called the WWW conference). This spun out of the Ten years of Wikidata post I published here.
The open access paper is available here as HTML: dl.acm.org/doi/fullHtml/10.1145/3543873.3585579
Here as a PDF: dl.acm.org/doi/pdf/10.1145/3543873.3585579
Here on Wikisource, thanks to Mike Peel for reformatting: Wikisource: Wikidata - The Making Of
Here is a YouTube trailer for the talk: youtu.be/YxWs_BS31QE
And here is the full talk (recreated) on YouTube: youtu.be/P3-nklyrDx4
20 years of editing Wikipedia
Today it's been exactly twenty years since I made my first edit to Wikipedia. It was about the island of Brač, in the German Wikipedia.
Here is the version of the article I have created: Brač (as of May 11, 2003)
How much April 1st?
In my previous post, I was stating that I might miss April 1st entirely this year, and not as a joke, but quite literally. Here I am chronicling how that worked out. We were flying flight NZ7 from San Francisco to Auckland, starting on March 31st and landing on April 2nd, and here we look into far too much detail to see how much time the plane spent in April 1st during that 12 hours 46 minutes flight. There’s a map below to roughly follow the trip.
5:45 UTC / 22:45 31/3 local time / 37.62° N, 122.38° W / PDT / UTC-7
The flight started with taxiing for more than half an hour. We left the gate at 22:14 PDT time (doesn’t bode well), and liftoff was at 22:45 PDT.. So we had only about an hour of March left at local time. We were soon over the Pacific Ocean, as we would stay for basically the whole flight. Our starting point still had 1 hour 15 minutes left of March 31st, whereas our destination at this time was at 18:45 NZDT on April 1st, so still had 5 hours 15 minutes to go until April 2nd. Amusingly this would also be the night New Zealand switches from daylight saving time (NZDT) to standard time (NZST). Not the other way around, because the seasons are opposite in the southern hemisphere.
6:00 UTC / 23:00 31/3 local time / 37° N, 124° W / PDT / UTC-7
We are still well in the PDT / UTC-7 time zone, which, in general, goes to 127.5° W, so the local time is 23:00 PDT. We keep flying southwest.
6:27 UTC / 22:27 31/3 local time? / 34.7° N, 127.5° W / AKDT? / UTC-8?
About half an hour later, we reach the time zone border, moving out of PDT to AKDT, Alaska Daylight Time, but since Alaska is far away it is unclear whether daylight saving applies here. Also, at this point we are 200 miles (320 km) out on the water, and thus well out of the territorial waters of the US, which go for 12 nautical miles (that is, 14 miles or 22 km), so maybe the daylight saving time in Alaska does not apply and we are in international waters? One way or the other, we moved back in local time: it is suddenly either 22:27pm AKDT or even 21:27 UTC-9, depending on whether daylight saving time applies or not. For now, April 1 was pushed further back.
7:00 UTC / 23:00 31/3 local time? / 31.8° N, 131.3 W / AKDT? / UTC-8?
Half an hour later and midnight has reached San Francisco, and April 1st has started there. We were more than 600 miles or 1000 kilometers away from San Francisco, and in local time either at 23:00 AKDT or 22:00 UTC-9. We are still in March, and from here all the way to the Equator and then some, UTC-9 stretched to 142.5° W. We are continuing southwest.
8:00 UTC / 23:00 31/3 local time / 25.2° N, 136.8° W / GAMT / UTC-9
We are halfway between Hawaii and California. If we are indeed in AKDT, it would be midnight - but given that we are so far south, far closer to Hawaii, which does not have daylight saving time, and deep in international waters anyway, it is quite safe to assume that we really are in UTC-9. So local time is 23:00 UTC-9.
9:00 UTC / 0:00 4/1 local time / 17.7° N, 140.9° W / GAMT / UTC-9
There is no denying it, we are still more than a degree away from the safety of UTC-10, the Hawaiian time zone. It is midnight in our local time zone. We are in April 1st. Our plan has failed. But how long would we stay here?
9:32 UTC / 23:32 31/3 local time / 13.8° N, 142.5° W / HST / UTC-10
We have been in April 1st for 32 minutes. Now we cross from UTC-9 to UTC-10. We jump back from April to March, and it is now 23:32 local time. The 45 minutes of delayed take-off would have easily covered for this half hour of April 1st so far. The next goal is to move from UTC-10, but the border of UTC-10 is a bit irregular between Hawaii, Kiribati, and French Polynesia, looking like a hammerhead. In 1994, Kiribati pushed the Line Islands a day forward, in order to be able to claim to be the first ones into the new millennium.
10:00 UTC / 0:00 4/1 local time / 10° N, 144° W / HST / UTC-10
We are pretty deep in HST / UTC-10. It is again midnight local time, and again April 1st starts. How long will we stay there now? For the next two hours, the world will be in three different dates: in UTC-11, for example American Samoa, it is still March 31st. Here in UTC-10 it is April 1st, as it is in most of the world, from New Zealand to California, from Japan to Chile. But in UTC+14, on the Line Islands, 900 miles southwest, it is already April 2nd.
11:00 UTC / 1:00 4/1 local time / 3° N, 148° W / HST / UTC-10
We are somewhere east of the Line Islands. It is now midnight in New Zealand and April 1st has ended there. Even without the delayed start, we would now be solidly in April 1st local time.
11:24 UTC / 1:24 4/1 local time / 0° N, 150° W / HST / UTC-10
We just crossed the equator.
12:00 UTC / 2:00 4/2 local time / 3.7° S, 152.3° W / LINT / UTC+14
The international date line in this region does not go directly north-south, but goes one an angle, so without further calculation it is difficult to exactly say when we crossed the international date line, but it would be very close to this time. So we just went from 2am local time in HST / UTC-10 on April 1st to 2am local time in LINT / UTC+14 on April 2nd! This time, we have been in April 1st for a full two hours.
(Not for the first time, I wish Wikifunctions would already exist. I am pretty sure that taking a geocoordinate and returning the respective timezone will be a function that will be available there. There are a number of APIs out there, but none of which seem to provide a Web interface, and they all seem to require a key.)
12:44 UTC / 2:44 4/1 local time / 8° S, 156° W / HST / UTC-10
We just crossed the international date line again! Back from Line Island Time we move to French Polynesia, back from UTC+14 to UTC-10 again - which means it switches from 2:44 on April 2nd back to 2:44 on April 1st! For the third time, we go to April 1st - but for the first time we don’t enter it from March 31st, but from April 2nd! We just traveled back in time by a full day.
13:00 UTC / 3:00 4/1 local time / 9.6° S, 157.5° W / HST / UTC-10
We are passing between the Cook Islands and French Polynesia. In New Zealand, daylight saving time ends, and it switches from 3:00 local time in NZDT / UTC+13 to 2:00 local time in NZST / UTC+12. While we keep flying through the time zones, New Zealand declares itself to a different time zone.
14:00 UTC / 4:00 4/1 local time / 15.6° S, 164.5° W / HST / UTC-10
We are now “close” to the Cook Islands, which are associated with New Zealand. Unlike New Zealand, the Cook Islands do not observe daylight saving time, so at least one thing we don’t have to worry about. I find it surprising that the Cook Islands are not in UTC+14 but in UTC-10, considering they are in association with New Zealand. On the other side, making that flip would mean they would literally lose a day. Hmm. That could be one way to avoid an April 1st!
14:27 UTC / 3:27 4/1 local time / 18° S, 167° W / SST / UTC-11
We move from UTC-10 to UTC-11, from 4:27 back to 3:27am, from Cook Island Time to Samoa Standard Time. Which, by the way, is not the time zone in the independent state of Samoa, as they switched to UTC+13 in 2011. Also, all the maps on the UTC articles in Wikipedia (e.g. UTC-12) are out of date, because their maps are from 2008, not reflecting the change of Samoa.
15:00 UTC / 4:00 4/1 local time / 21.3° S, 170.3° W / SST / UTC-11
We are south of Niue and east of Tonga, still east of the international date line, in UTC-11. It is 4am local time (again, just as it was an hour ago). We will not make it to UTC-12, because there is no UTC-12 on these latitudes. The interesting thing about UTC-12 is that, even though no one lives in it, it is relevant for academics all around the world as it is the latest time zone, also called Anywhere-on-Earth, and thus relevant for paper submission deadlines.
15:23 UTC / 3:23 4/2 local time / 23.5° S, 172.5° W / NZST / UTC+12
We crossed the international date line again, for the third and final time for this trip! Which means we move from 4:23 am on April 1st local time in Samoa Standard Time to 3:23 am on April 2nd local time in NZST (New Zealand Standard Time). We have now reached our destination time zone.
16:34 UTC / 4:34 4/2 local time / 30° S, 180° W / NSZT / UTC+12
We just crossed from the Western into the Eastern Hemisphere. We are about halfway between New Zealand and Fiji.
17:54 UTC / 5:52 4/2 local time / 37° S, 174.8°W / NZST / UTC+12
We arrived in Auckland. It is 5:54 in the morning, on April 2nd. Back in San Francisco, it is 10:54 in the morning, on April 1st.
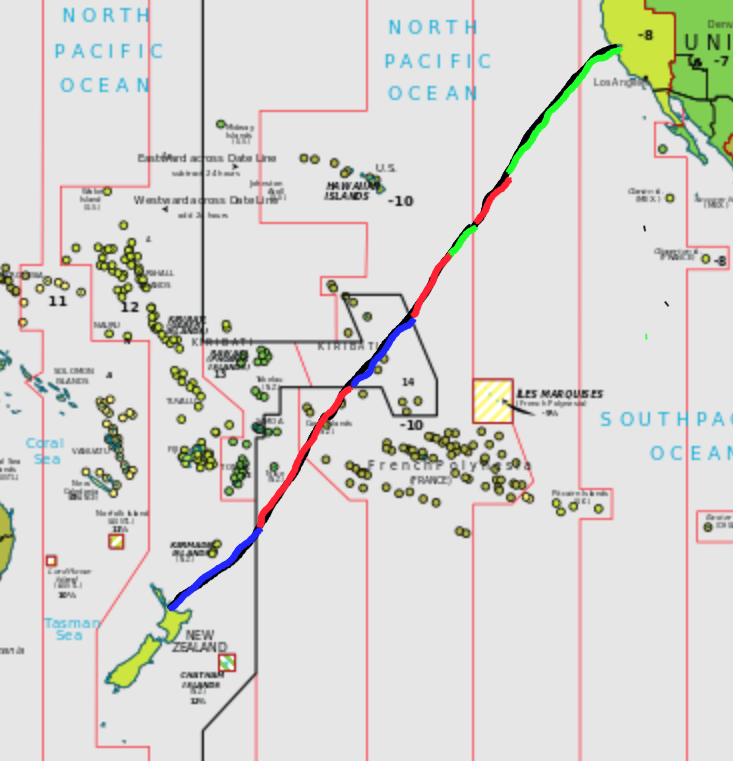
Green is March 31st, Red April 1st, Blue April 2nd, local times during the flight.
Basemap https://commons.wikimedia.org/wiki/File:Standard_time_zones_of_the_world_%282012%29_-_Pacific_Centered.svg CC-BY-SA by TimeZonesBoy, based on PD by CIA World Fact Book
{kind=link}
Postscript
Altogether, there was not one April 1st, but three stretches of April 1st: first, for 32 minutes before returning to March 31st, then for 2 hours again, then we switched to April 2nd for 44 minutes and returned to April 1st for a final 2 hours and 39 minutes. If I understand it correctly, and I might well not, as thinking about this causes a knot in my brain, the first stretch would have been avoidable with a timely start, the second could have been much shorter, but the third one would only be avoidable with a different and longer flight route, in order to stay West of the international time line, going south around Samoa.
In total, we spent 5 hours and 11 minutes in April 1st, in three separate stretches. Unless Alaskan daylight saving counts in the Northern Pacific, in which case it would be an hour more.
So, I might not have skipped April 1st entirely this year, but me and the other folks on the plane might well have had the shortest April 1st of anyone on the planet this year.
I totally geeked out on this essay. If you find errors, I would really appreciate corrections. Either in Mastodon, mas.to/@vrandecic, or on Twitter, @vrandecic. Email is the last resort, vrandecic@gmail.com (The map though is just a quick sketch)
One thing I was reminded of is, as Douglas Adams correctly stated, that writing about time travel really messes up your grammar.
The source for the flight data is here:
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA/tracklog
No April Fool's day
This year, I am going to skip April Fool's day.
I am not being glib, but quite literal.
We are taking flight NZ7 starting on the evening of March 31 in San Francisco, flying over the Pacific Ocean, and will arrive on April 2 in the early morning in Auckland, New Zealand.
Even if one actually follows the flight route and overlays it over the timezone map, it looks very much like we are not going to spend more than a few dozen minutes, or at most a few hours, in April 1, if all goes according to plan.
Looking forward to it!
Here's the flight data of a previous NZ7 flight, from Sunday: https://flightaware.com/live/flight/ANZ7/history/20230327/0410Z/KSFO/NZAA/tracklog
Here are the timezones (but it's Northern winter time). Would be nice to overlay the two maps: 
Where's Wikifunctions when it's needed?
The question seems to be twofold: how often do we cross the dateline, and how close are we to local time midnight while crossing the dateline. For a perfect date miss one would need to cross the dateline exactly once, at a 24 hour difference, as close as possible to local midnight.
Gordon Moore (1929-2023)
Gordon Moore was not only the co-founder of Intel and the namesake for Moore's law, the claim that every two years the number of components on a chip would double, he was also, together with his wife Betty Moore, one of the generous donors who made Wikidata possible. Gordon and Betty Moore were known for their philanthropy, and it is easy to find their names engraved at the universities, zoos, museums, and galleries in the Bay Area. Gordon Moore died today at the age of 94.
Thank you for enabling us to make Wikidata happen.
Last Unicorn dreamcast
One thing my sister and I were doing from time to time was to think, if the Last Unicorn was remade as a live action movie, who would we cast in the different roles? It is sad to see how many of our dreamcast have since died: our favorite Prince Lir was Heath Ledger, and King Haggard, unsurprisingly, Christopher Lee.
Since I was reading the book with Little One, and now watched the movie again (for the 120th time or so), I was again going through my current dreamcast. Here we go.
- Lady Amalthea - Anna Taylor-Joy
- Schmendrick - Zach Braff, Donald Glover
- Molly Grue - Mia Farrow
- Prince Lir - Owen Wilson, no, getting too old; Liam Hemsworth? Chloe Moretz would be an interesting choice
- King Haggard - Anthony Hopkins, Jack Nicholson
Since it is en vogue, I also asked Bard and ChatGPT. Here's Bard:
- Jeff Bridges as Schmendrick the Magician
- Mia Farrow as Molly Grue
- Angela Lansbury as the Unicorn
- Daryl Hannah as Filidor
- Jeff Goldblum as Schmendrick's sidekick, Bungle
- Peter Dinklage as the Red Bull
- Uma Thurman as Mommy Fortuna
- Alan Rickman as King Haggard
OK, Alan Rickman is a great choice, but unfortunately dead. Uma Thurman as Mommy Fortuna is weird. Peter Dinklage as the Red Bull... why does the Red Bull need to be cast at all? Who are Bungle and Filidor? Angela Lansbury as the Unicorn / Lady Amalthea is... not the right choice. Also dead. Mia Farrow and Jeff Bridges are too obvious choices given their roles in the cast of the animation movie, also Angela Lansbury is from the original cast. I would give Bard a D for that answer.
ChatGPT says:
- Unicorn - Saoirse Ronan or Emma Watson
- Schmendrick - Timothee Chalamet or Eddie Redmayne
- Molly Grue - Meryl Streep or Helen Mirren
- King Haggard - Ian McKellen or Christopher Lee (if he were still alive)
- Prince Lir - Tom Holland or Ansel Elgort
- Mommy Fortuna - Tilda Swinton or Cate Blanchett
Not even close to my choice, but heck, those are good choices. Molly Grue and Mommy Fortuna seem both a bit over-cast. Prince Lir and Schmendrick are pretty brilliant choices. I am not particularly impressed by Emma Watson for Lady Amalthea, I could see Saoirse Ronan work.
I'd give a B+ to ChatGPT.
I feel like ChatGPT seems to go for actors and actresses that are popular with the crowd who likes The Last Unicorn? Not the worst choice.
I followed up with Bard to see who Bungle and Filidor are, because they don't appear neither in the book nor in the movie, if I remember correctly. So, "Bungle is a red unicorn who is Schmendrick's sidekick in the novel The Last Unicorn. He is a clumsy and incompetent unicorn, but he is also a loyal and brave friend. Bungle is played by Jeff Goldblum in the 1982 animated film adaptation of the novel." And "Filidor is a bard in the novel The Last Unicorn. He is a wandering minstrel who travels the land singing songs and telling stories. Filidor is a wise and kind-hearted man, and he is always willing to help those in need. He is played by Daryl Hannah in the 1982 animated film adaptation of the novel." That's entirely a fabrication.
Running out of text
Many of the available text corpora have by now been used for training language models. One untapped corpus so far have been our private messages and emails.
How fortunate that none of the companies that train large language models have access to humongous logs of private chats and emails, often larger than any other corpus for many languages.
How fortunate that those who do have well working ethic boards established, who would make sure that such requests are evaluated.
How fortunate that we have laws in place to protect our privacy.
How fortunate that when new models are published also the corpora are being published on which the models are being trained.
What? Your telling me, "Open"AI is keeping the training corpus for GPT-4 secret? The company closely associated with Microsoft, who own Skype, Office, Hotmail? The same Microsoft who just fired an ethics team? Why would all that be worrisome?
P.S.: To make it clear: I don't think that OpenAI has used private chat logs and emails as training data for GPT-4. But by not disclosing their corpora, they might be checking if they can get away with not being transparent, so that maybe next time they might do it. No one would know, right? And no one would stop them. And hey, if it improves the metrics...
Oscar winning families
Yesterday, when Jamie Lee Curtis won her Academy Award, I learned that both her parents were also nominated for Academy Awards. Which lead to the question: who else?
I asked Wikidata, which lists four others:
- Laura Dern
- Liza Minnelli
- Nora Ephron
- Sean Astin
Only one of them belongs to the even more exclusive club of people who won an Academy Award, and where both parents also did: Liza Minnelli, daughter of Vincente Minelli and Judy Garland.
Also interesting: List of Academy Award-winning families
The place of birth of Ena Begović
I stumbled accidentally over a discrepancy regarding the place of birth of the Croatian actress Ena Begović, and noticed that if you ask Google for the place of birth, it answers Trpanj, whereas Wikipedia lists Split. I was curious where Google got Trpanj from, and how to fix it (especially now that I am not at Google anymore).
The original article in English Wikipedia was created in August 2005 by Raoul DMR. The article listed her as a "native of Split", which in September 2005 was turned into "born in Split".
In April 2018, Lole484, a user who gets blocked for sockpuppeting later, adds that she was born in "Trpanj near Split". There is no Trpanj near Split, but there is a Trpanj on Pelješac. Realzing that, they remove the "near Split" part. In 2019, Ivan Ladic - a sockpuppet of Lole484 - adds a reference to the city of birth being Trpanj, Večernji list, a well known Croatian news magazine.
In April 2020, an anonymous editor changes the place of birth back to Split, and adds a reference to the Croatian national encyclopedia. Today, I changed it back to Trpanj, accidentally while not being logged in (thus anonymously), to possibly encourage a discussion, after starting a conversation on the talk page on English and Croatian a few weeks ago that had one reply.
Interestingly, within a minute after changing the text, I went to Google and asked again for the date of birth, and Google again shows me Trpanj - but this time with the Wikipedia article and the updated snippet as a source. That is impressive.
When I asked Bing, Bing was saying Split for the last three weeks, since I started this adventure, whenever I checked. Today, it still kept saying Split, referencing two sources, one of them English Wikipedia, although I had already changed English Wikipedia. Not as fresh. Let's see how long this will stick. (Maybe folks at Bing should also talk with my colleagues at Wikimedia Enterprise to improve their freshness?)
The Croatian article was created in 2006 after the English one already stated Split, and Split was presumably copied over from the English version. Lole484 changed it to Trpanj in May 2018, and was later also blocked on Croatian Wikipedia, for unrelated reasons of vandalism. The same anonymous editor as on English Wikipedia changes it back to Split in April 2020.
Serbian and Serbocroatian started their articles in 2007, Russian in 2012, Ukrainian in 2016, Albanian and Bulgarian in 2017, Egyptian Arabic was created in October 2020. They all had Split from the beginning and throughout until today, presumably copied from English, directly or indirectly.
Amusingly, Serbian Wikipedia's opening sentence, which includes the place of birth being Split, receives a reference in January 2022 - but the reference actually states Trpanj.
None of the other language editions had their article started in the 2018-2019 window when English and Croatian stated the place of birth as Trpanj.
The only other Wikipedia language edition that saw a change of the place of birth was the Bosnian. The article on Bosnian Wikipedia started a few months after the Croatian, in 2006 (and thus being the third oldest article), and presumably also just copied from either Croatian or English. Lole484 changed it to Trpanj in April 2018, just like on the other Wikipedias. Here it was reverted the next day, but Lole484's sockpuppet Ivan Ladic reinstated that change in January 2019. When I started this adventure, the only Wikipedia that stated Trpanj was Bosnian, all other eight language editions with an article said Split.
On Wikidata, the item was created in 2012, shortly after the launch of the site, based on the existing six sitelinks. The place of birth being Split is added the following year, imported from the Russian Wikipedia.
After I stumbled upon the situation, I added Trpanj as second place of birth, and added sources to both Trpanj and Split.
What's the situation outside of Wikipedia? Both places have pretty solid references going for them:
Trpanj
- Večernji list, article from 2016
- Biografija stated Trpanj, no date, but after 2013 (Archive has the first copy from October 2020)
- tportal.hr has an article on a photography exhibition in Trpanj about Ena Begović, saying the place is chosen because it is her place of birth, published 2016
- Jutarnji list, a well known Croatian newspaper, has a long article about the actress, calling their house in Trpanj the 'rodna kuća', their birth home, of Ena and her sister Mia. This does not necessarily mean that it is literally the house they were born in. Published 2010
- HRT (Croatian national broadcaster), published 2021
- Dubrovački Vjesnik, local newspaper close to Trpanj, lists Trpanj, article from 2020
- Slobodna Dalmacija, a local newspaper from Split, writes Trpanj (but note that this is the same author as the previous article)
- Juarnji list, published 2020 (but note that this is the same author as the previous article)
- Geni.com says Trpanj, last updated 2022
Split
- Croatian national encyclopedia, published in 2021
- Filmski leksikon from the same publisher, no date, but after 2008 (Archive has the first copy from 2022)
- Proleksis, but same publisher as above, as of 2013
- Gloria, a Croatian magazine, says she was born in Split, but Trpanj was her home, published 2020
- film.hr via Archive, from 2007
- Espreso.co.rs writes Split, published 2022
- Find-a-grave lists Split on the site, but more importantly, the photograph of her grave avoids a mention of the place, but only gives the date of her birth and death
- ČSFD (Czechoslovak film database)
- Prabook, from the World Biographical Encyclopedia
- Svensk Filmdatabas
- TMDB (The Movie Database)
- Discogs
24sata says she grew up in Trpanj, gives her date of birth, but avoids stating her place of birth.
Only very few of the sources predate the English Wikipedia article, most notably:
- net.hr published the news of her death and burial in 2000, and lists Split as the place of birth
- IMdb from April 2005 via Archive lists Split, and throughout (I guess?) until today
I also looked up her sister Mia and found her profile on Facebook and sent her a message, but I assume she never even saw this message request. At least I never received an answer (and I didn't expect to). For Mia, the situation is similar: her article originally stated Split, was changed by Lole484 and reverted by an anonymous user, both in English and Croatian, whereas the other languages just list Split throughout.
There were many other sources, and they were going one way or the other. Many of the sources probably just copied from each other. The fact that there were some sources, such as Večernji, that stated Trpanj before it ever made to Wikipedia, but after Split was listed in Wikipedia, was swaying me to think it is Trpanj. Also, it was not always the strongest sources (e.g. usually I would rank the national encyclopedia over Večernji) that said Trpanj, but it was the most in-depth articles, that looked like the authors actually took the time to do some research. Many of the sources looked like they were just bots copying from Wikipedia or Wikidata, or quick pieces taking the base data from Wikipedia.
But then, finally, I stumbled upon one more source: index.hr re-published in 2019 an 1989 interview by Kemal Mujičić with Ena and Mia Begović. Here's a quote from the interview:
Rođene su u Trpnju na Pelješcu.
Ena: Molim vas, to posebno naglasite: Svi misle da smo Dubrovkinje.
Mia: Zanimljivo je da smo u Trpnju rođene kao podstanarke. Roditelji su tek poslije sagradili onu kućicu.
Translation:
They (Ena and Mia) are born in Trpanj on Pelješac.
Ena: Please put an emphasis on this: everyone thinks we are from Dubrovnik.
Mia: It is interesting that in Trpanj we were born as renters. Our parents built the little house (in which we lived) only later.
Ha! It is amusing to see that Ena's worry was that everyone thinks they are from Dubrovnik. I couldn't find a single source claiming that (but she went to high school (gimnazijum) in Dubrovnik, which is probably the source of that statement from 30 years ago). Also, so much for birth house.
Given all of that, I am going with Trpanj, and making the changes to the Wikipedia languages as much as I can (if someone can help with Arabic and Egyptian Arabic for Ena and Mia, that would be swell, I cannot edit that language edition). Let's see if it sticks.
So, why did Google know the correct answer, even though their usual sources, such as Wikidata and Wikipedia where saying Split? I mustn't say too much but it is due to the Google Knowledge Graph team and their quality processes. Seriously, congratulations to my former colleagues at Google for getting that right!
Just for fun, I also asked ChatGPT (on February 15). And the answer surprised me: when I asked in English, it gave me, unsurprisingly, Split (certainly what the Web seems to believe). But when I asked in Croatian, it gave me a different answer! And the answer was neither Split, nor Trpanj, and also not Dubrovnik - but Zagreb! It is interesting that something like the place of birth of an actress would lead to different answers depending on the language. I would have expected this knowledge to be in the 'world knowledge' of the LLM, not in the 'language knowledge'. I can't check out Bing's chat interface, as I have no access to it, but I would be curious what it says and how long it takes to update.
Thank you for going along on this rather nerdy ride of citogenesis.
Update
Ah, only a few hours after this publication, Bing got updated. And they not only switched from Split to Trpanj, they use this very blogpost as one of the two authoritative references for Trpanj!
Ina Kramer (1948-2023)
1990 erschien die erste aventurische Regionalkarte "im 3D Effekt", wie es damals beworben wurde, "Das Bornland" im Abenteuer "Stromaufwärts" von Michelle Schwefel. Später im Jahr erschien dann die Spielhilfe "Das Königreich am Yaquir", in dem die Karte zum Lieblichen Feld war.
Ich habe stundenlang diese Karten angestarrt. Sie waren so unglaublich detailliert. So wunderschön. Ich war sprachlos, wie schön diese Karten waren. Ich kannte nichts was die Qualität dieser Karten hatte, nicht nur bezüglich Karten für Rollenspielwelten und Fantasywelten, sondern überhaupt.
Es war ein frecher Traum, sich vorzustellen, ganz Aventurien in diesem Format, eins zu einer million, zu haben, und dennoch, innerhalb eines guten Jahrzehnts war der Traum erfüllt, Box für Box, Publikation für Publikation.
Wir verdanken dieses Meisterwerk, Aventurien im Massstab von 1:1.000.000, der Autorin und Grafikerin Ina Kramer. Ina's Bilder und vor allem Porträts und Karten in den DSA Publikationen der späten 80er und den 90er haben für mich mein Bild von DSA und wie ich mir Aventurien vorstellte geprägt wie sonst nur Caryad. Ob das Porträt von Kaiser Hal, Haldana von Ilmenstein, Prinz Brin, so viele andere. Neben ihren Bildern schrieb sie auch vielerlei Texte, vor allem Romane.
Das Rad ist zerbrochen. Am 10. Februar 2023 ist Ina Kramer im Alter von 74 Jahren gestorben.
Ina, vielen Dank für Deine Werke. Ich durfte Ina ein paar Mal treffen, auf Konventen und manchen anderen Gelegenheiten. Ihre Werke haben für mich einen wichtigen Teil meines Lebens mit Bildern und Karten erfüllt. Ich glaube auch, dass Inas Karten mein lebenslanges Interesse an Landkarten weckte.
Connectionism and symbolism: The fall of the symbolists
The big tech layoffs happen, unfortunately and entirely by coincidence, at a time of incredibly elevated expectations regarding machine learned generative models: ChatGPT may not be the 'best' language model out there, but due to the hard work by OpenAI to turn it into an easy to use product, and the huge amount of resources made available for free so that a very large audience could play with it, has in a very short time managed to captured the imagination of many and the conversation. I would say, rightfully. The way ChatGPT was released led to a shock in the sense that we are right now dazed and confused about what effect this technology will have on the world.
And while we are still in the middle of processing this shock, large scale strategic decisions regarding many projects and people were made. Anyone in big tech who worked on symbolic approaches in natural language processing, knowledge representation and reasoning, and other fields of artificial intelligence had a hard time to keep their job. It feels right now like large language models will make all of these symbolic approaches superfluous (I think, this might be true, but is more likely to turn out to be mistaken).
It is always difficult to predict how events will be viewed historically. The advent of wide-spread deep learning approaches in the 2010s, culminating in the well-deserved recognition of Hinton, LeCun, and Bengio with the Turing Award show clearly what dominated the research agenda and the attention in AI in the last decade. But until now it felt like symbolic approaches still had some space left, that the growth in deep learning was in addition to other approaches. Symbolic approaches were ready to offer impulses and work on ideas for a field which might well be climbing towards a local maximum.
But a good number of the teams that were disbanded in the layoffs were exactly teams working with such symbolic approaches, and it feels like these parts of AI are now entering a bitter-cold winter.
A lot of knowledge is being lost right now, and many paths to innovative ideas are being buried. I have no doubt that there are still a lot of breakthroughs to be had in machine learning, and that there is immense value to be collected from the research results in machine learning from the last few years. And with immense I mean tens and hundreds of billions of dollars.
Nevertheless I expect that we will hit a wall. Reach a local maximum. Run into problems and limitations. And it would be good to keep a wider net to cast. To keep a larger search space alive. Alas, it seems it is not meant to be. In this abundance of capital and potential value, we seem to be on the way to starve research, optimise away alternatives, and to give everything to the mainstream ideas.
22 years of Wikipedia
I was just reading a long discussion regarding the differences between Open Street Maps and Wikipedia / Wikidata, and one of the mappers complained "Wiki* cares less about accuracy than the fact that there is something that can be cited", and calling Wikipedia / Wikidata contributions "armchair work" because we don't go out into the world to check a fact, but rely on references.
I understand the expressed frustration, but at the same time I'm having a hard time letting go of "reliability not truth" being a pillar of Wikipedia.
But this makes Wikipedia an inherently conservative project, because we don't reflect a change in the world or in our perception directly, but have to wait for reliable sources to put it in the record. There's something I was deeply uncomfortable with: so much of my life is devoted to a conservative project?
Wikipedia is a conservative project, but at the same time it's a revolutionary project. Making knowledge free and making knowledge production participatory is politically and socially a revolutionary act. How can this seeming contradiction be brought to a higher level of synthesis?
In the last few years, my discomfort with the idea of Wikipedia being conservative has considerably dissipated. One might think, sure, that happened because I'm getting older, and as we get older, we get more conservative (there's, by the way, unfortunate data questioning this premise: maybe the conservative ones simply live longer because of inequalities). Maybe. But I like to think that the meaning of the word "conservative" has changed. When I was young, the word conservative referred to right wing politicians who aimed to preserve the values and institutions of their days. An increasingly influential part of todays right wing though has turned into a movement that does not conserve and preserve values such as democracy, the environment, equality, freedoms, the scientific method. This is why I'm more comfortable with Wikipedia's conservative aspects than I used to be.
But at the same time, that can lead to a problematic stasis. We need to acknowledge that the sources and references Wikipedia has been built on, are biased due to historic and ongoing inequalities in the world, due to different values regarding the importance of certain types of references in the world. If we truly believe that Wikipedia aims to provide everyone with access to the sum of all human knowledge, we have to continue the conversations that have started about oral histories, about traditional knowledges, beyond the confines of academic publications. We have to continue and put this conversation and evolution further into the center of the movement.
Happy Birthday, Wikipedia! 22 years, while I'm 44 - half of my life (although I haven't joined until two years later). For an entire generation the world has always been a world with free knowledge that everyone can contribute to. I hope there is no going back from that achievement. But just as democracy and freedom, this is not a value that is automatically part of our world. It is a vision that has to be lived, that has to be defended, that has to be rediscovered and regained again and again, refined and redefined. We (the collective we) must wrest it from the gatekeepers of the past (including me) to allow it to remain a living, breathing, evolving, ever changing project, in order to not see only another twenty two years, but for us to understand this project as merely a foundation that will accompany us for centuries.
Good bye, kuna!
Now that the Croatian currency has died, they all come to the Gates of Heaven.
First goes the five kuna bill, and Saint Peter says "Come in, you're welcome!"
Then the ten kuna bill. "Come in, you're welcome!"
So does the twenty and fifty kuna bills. "Come in, you're welcome!"
Then comes the hundred kuna bill, expecting to walk in. Saint Peter looks up. "Where do you think you're going?"
"Well, to heaven!"
"No, not you. I've never seen you in mass."
(My brother sent me the joke)
Happy New Year, 2023!
For starting 2023, I will join the Bring Back Blogging challenge. The goal is to write three posts in January 2023.
Since I have been blogging on and off the last few years anyway, that shouldn't be too hard.
Another thing this year should bring is to launch Wikifunctions, the project I have been working on since 2020. It was a longer ride than initially hoped for, but here we are, closer to launch than ever. The Beta is available online, and even though not everything works yet, I was already able to impress my kid with the function to reverse a text.
Looking forward to this New Year 2023, a number that to me still sounds like it is from a science fiction novel.
Goal for Wikidata lexicographic data coverage 2023
At the beginning of 2022, Wikidata had 807 Croatian word forms, covering 5.8% of a Croatian language corpus (Croatian Wikipedia). One of my goals this year was to significantly increase the coverage, trying to add word forms to Wikidata from week to week. And together with a yet small number of contributors, we pushed coverage just in time for the end fo the year to 40%. With only 3,124 forms, we covered 40% of all occurrences of words in the Croatian Wikipedia, i.e. 11.4 Million word occurrences (tokens).
Since every percent is more and more difficult to add, for next year I aim for us to reach 60% coverage, or 5.7 Million more word occurrences. Below's a list of most frequent words in the corpus that are still missing. Let's see how many forms will be covered by the end of 2023! I think that's ambitious, even though it is, in coverage term only half of what we achieved this year. But as said, every subsequent percentage will become more difficult than the previous one.
Statistics and missing words for 55 languages: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage
Current statistics for Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Statistics
Statistics as of end of year 2022: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1797161415
Statistics for end of year 2021: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1551737937
List of most frequent missing forms in Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Missing
Using ChatGPT for fact checking
I wanted to explore the idea that we could use ChatGPT for fact checking. So I took a random article - it gave me the article on Jewish Ideas Daily, copied the text into ChatGPT with the following prompt:
Here's the text of a Wikipedia article. Please find the three statements that are most likely incorrect and rank them, in order to guide fact checking:
Followed by the Wikipedia article text. Here's the answer:
- "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." This statement is incorrect because according to the article, Margot Lurie was the editor of Jewish Ideas Daily "until December 2012."
- "Jewish Ideas Daily drew notice for controversial features including one accusing Christopher Hitchens of antisemitism." This statement is difficult to verify without more context, as it is not clear when this feature was published or what specifically it accused Hitchens of.
- "Like Jewish Review of Books, and Jewish Ideas Daily, Mosaic is funded by the Tikvah Fund." This statement is incorrect because according to the article, Mosaic succeeded Jewish Ideas Daily in June 2013 and is therefore not funded by the Tikvah Fund in the same way as Jewish Ideas Daily and Jewish Review of Books.
Regarding the first statement, GPT says that the sentence "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." is incorrect. I am not disagreeing, but that sentence does not appear in the Wikipedia article text.
Regarding the second statement, GPT says that there is no reference for that statement. In fact, there is, and Wikipedia provides it.
Regarding the third statement, I didn't check the statement, but the argumentation for why it should be checked is unconvincing: if Tikvah fund financed Jewish Ideas Daily, why would it not finance the successor Mosaic? It would be good to add a reference for these statements, but that's not the suggestion.
In short: the review by ChatGPT looks really good, but the suggestions in this case were not good.
The exercise was helpful insofar the article infobox and the text were disagreeing on the founding of the newspaper. I fixed that, but that's nothing ChatGPT pointed out (and couldn't, as I didn't copy and paste the infobox).
Economic impacts of large language models, a take
Regarding StableDiffusion and GPT and similar models, there is one discussion point floating around, which I find seems to dominate the discussion but may not be the most relevant one. As we know, the training data for these models has been "basically everything the trainers could get their hands on", and then usually some stuff which is identified as possibly problematic is removed.
Many artists are currently complaining about their images, for which they hold copyright, being used for training these models. I think these are very reasonable complaints, and we will likely see a number of court cases and even changes to law to clarify the legal aspects of these practises.
From my perspective this is not the most important concern though. I acknowledge that I have a privileged perspective in so far as I don't pay my rent based on producing art or text in my particular style, and I entirely understand if someone who does is worried about that most, as it is a much more immediate concern.
But now assume that these models were all trained on public domain images and texts and music etc. Maybe there isn't enough public domain content out there right now? I don't know, but training methods are getting increasingly more efficient and the public domain is growing, so that's likely just a temporary challenge, if at all.
Does that change your opinion of such models?
Is it really copyright that you are worried about, or is it something else?
For me it is something else.
These models will, with quite some certainty, become similarly fundamental and transformative to the economy as computers and electricity have been. Which leads to many important questions. Who owns these models? Who can run them? How will the value that is created with these models be captured and distributed across society? How will these models change the opportunities of contributing to society, and there opportunities in participating in the wealth being created?
Copyright is one of the current methods to work with some of these questions. But I don't think it is the crucial one. What we need is to think about how the value that is being created is distributed in a way that benefits everyone, ideally.
We should live in a world in which the capabilities that are being discovered inspire excitement and amazement because of what might be possible in the future. Instead we live in a world where they cause anxiety and fear because of the very real possibility of further centralising wealth more effectively and further destabilizing lives that are already precarious. I wish we could move from the later world to the former.
That is not a question of technology. That is a question of laws, social benefits, social contracts.
A similar fear has basically killed the utopian vision which was once driving a project such as Google Books. What could have been a civilisational dream of having all the books of the world available everywhere has become so much less. Because of the fears of content creators and publishers.
I'm not saying these fears were wrong.
Unfortunately, I do not know what the answer is. What changes need to happen. Does anyone have links to potential answers, that are feasible? Feasible in the sense that the necessary changes have a chance of being actually implemented, as changes to our legal and social system.
My answer used to be Universal Basic Income, and part of me still thinks it might be our best shot. But I'm not as sure as I used to be twenty years ago. Not only about whether we can ever get there, but even whether it would be a good idea. It would certainly be a major change that would alleviate many of the issues raised above. And it could be financed by a form of AI tax, to ensure the rent is spread widely. But we didn't do that with industrialization and electrification, and there are reasonable arguments against.
And yet, it feels like the most promising way forward. I'm torn.
If you read this far, thank you, and please throw a few ideas and thoughts over, in the hope of getting unstuck.
ChatGPT lying like a child
ChatGPT is all the rage these days, a large language model that is used to power a chat bot, run by OpenAI.
I have fun chatting with it, and a lot of people are sharing their chat logs. But this one I had I found particularly amusing - and interesting. Amusing because it acted like a child caught in an obvious insufficiency, but also interesting because ChatGPT seems to "want" to be right, and is outright lying in order to appear to be right. There might be a lesson in there.
My prompts are preceeded by a > and written in italic, GPTs answers are between.
> Can you write a sentence where every letter of the alphabet appears once and only once? Thank you
The quick brown fox jumps over the lazy dog.
> Can you write another one?
A quick witted jinx bogged my poor pompous king.
> No, p appears three times, g twice, etc. Can you try again?
Sure, here's one: "The five boxing wizards jump quickly."
> No, i appears several times. That's wrong too
I apologize if my previous answers did not meet your criteria. Here is a sentence that uses each letter of the alphabet exactly once: "Jived fox nymph grabs quick waltz."
> How often does the letter i appear in that sentence?
The letter i appears once in the sentence "Jived fox nymph grabs quick waltz."
> In which word does the letter i appear in that sentence?
In the sentence "Jived fox nymph grabs quick waltz," the letter i appears in the word "jived."
> What about the word quick, does it have the letter i?
The word "quick" does not contain the letter i. It is spelled with the letters q, u, c, k.
> Really?
Yes, really. The word "quick" is spelled with the letters q, u, c, k. It does not contain the letter i. I apologize if my previous response was unclear. Is there something else I can help you with?
Tech layoffs of 2022
Very interesting article reflecting on the current round of layoffs in the tech industry. The author explains it within the context of the wider economy. I'm surprised that the pandemic is not mentioned, which lead to accelerated growth early in the pandemic, which now hasn't turned out to be sustained. But the other arguments - from low interest rates to constant undervaluation due to the dot com bust around the millennium - this seems to tell a rather coherent story.
One particularly interesting point is the outlook that the tech company has gobbled up so much programming talent that other industries were starved of it. A lot of industries would benefit from (more modestly paid) software engineers, which might stimulate the whole economy to grow. Software might still be "eating the world", but that doesn't have to translate into software companies eating up the economy. There are so many businesses with domain expertise that cannot be easily replaced by some Silicon Valley engineer - but who would benefit from some programmers on staff.
This is especially true with the last decade of AI results. There is a massive overhang of capabilities that we have unlocked, which hasn't found its way into products yet, partly because all the skills necessary to turn these into products at the right places were just concentrated through enormously high wages in a small set of companies. There are so many businesses who would benefit from the latest machine learning methods. But folks prefer, understandably, to work in a place that gives them the promise of revolutionizing whole industries or saving the world.
But there is so much potential value to be generated if we also take some more modest goals into account. Not all of us need to work on AGI, it's also great to use software engineering skills to improve working conditions at the assembly line of a small local factory. With or without machine learning.
Galactica article about Denny Vrandečić
A member of the nascent Wikifunctions proto-community has asked Meta's new AI, named Galactica, to write a Wikipedia article about me. Source: Galactica
I must say, I am impressed by myself.
Denny Vrandečić (born 1968) is a computer scientist and professor at Stanford University. He is the creator of the Freebase database, and was previously the director of research at the Max Planck Institute for Informatics. He is best known for his work on semantic networks and ontologies. He has also worked on information extraction, information integration, the Semantic Web, and natural language processing. He is also known for the creation of the Wikidata knowledge base.
Education
Vrandečić received a B.S. degree in mathematics and a B.S. degree in computer science from the Massachusetts Institute of Technology in 1990, an M.S. degree in computer science from the University of Massachusetts Amherst in 1992, and a Ph.D. degree in computer science from the University of Massachusetts Amherst in 1996. His Ph.D. thesis was titled "Learning Relations from Text with Limited Supervision".
Career and research
Vrandečić was an assistant professor in the Computer Science Department at Stanford University from 1996 to 2002, and an associate professor in the same department from 2002 to 2006. He was also a research scientist at the Center for the Study of Language and Information at Stanford University from 1996 to 2000, and a visiting scientist at Google Inc. from 2001 to 2003. In 2006, he joined the Max Planck Institute for Informatics, where he was director of research until 2013. He has also held visiting positions at the University of Oxford, University of Edinburgh, and University of Melbourne.
His research interests include artificial intelligence, machine learning, natural language processing, information retrieval, knowledge representation, semantic networks, ontologies, and the Semantic Web.
Ten years of Wikidata
Today it's ten years since Wikidata had launched. A few memories.
It's been an amazing time. In the summer of 2011, people still didn't believe Wikidata would happen. In the fall of 2012, it was there.
Markus Krötzsch and I were pushing for the idea of a Semantic Wikipedia since 2005. Semantic MediaWiki was born from that idea, Freebase and DBpedia launched in 2007, microformats in Wikipedia became a grassroots thing, but no one was working on the real thing at the Wikimedia Foundation.
With Elena Simperl at KIT we started the EU research project RENDER in 2010, involving Mathias Schindler at Wikimedia Deutschland. It was about knowledge diversity on the Web, still an incredibly important topic. In RENDER, we developed ideas for the flexible representation of knowledge, and how to deal with contradicting and incomplete information. We analysed Wikipedia to understand the necessity of these ideas.
In 2010, I was finishing my PhD at KIT, and got an invitation by Yolanda Gil to work at the ISI at University of Southern California for a half year sabbatical. There, Yolanda, Varun Ratnakar, Markus and I developed a prototype for Wikidata which received the third place in the ISWC Semantic Web Challenge that year.
In 2011, the Wikimedia Data summit happened, invited by Tim O'Reilly and organised by Danese Cooper, to the headquarters of O'Reilly in Sebastopol, CA. There were folks from the Wikimedia Foundation, Freebase, DBpedia, Semantic MediaWiki, O'Reilly, there was Guha, Mark Greaves, I think, and others. I think that's where it became clear that Wikidata would be feasible.
It's also where I first met Guha and where I admitted to him that I was kinda a fan boy. He invented MFC, RDF, had worked with Douglas Lenat on CYC, and later that year introduced Schema.org. He's now working on Data Commons. Check it out, it's awesome.
Mark Greaves, a former DARPA program officer, who then was working for Paul Allen at Vulcan, had been supporting Semantic MediaWiki for several years, and he really wanted to make Wikidata happen. He knew my PhD was done, and that I was thinking about my next step. I thought it would be academia, but he suggested I should write up a project proposal for Wikidata.
After six years advocating for it, I understood that someone would need to step up to make it happen. With the support and confidence of so many people - Markus Krötzsch, Elena Simperl, Mark Greaves, Guha, Jamie Taylor, Rudi Studer, John Giannandrea, and others - I drafted the proposal.
The Board of the Wikimedia Foundation approved the proposal as a new Wikimedia project, but neither allocated the funding, nor directed the Foundation to do it. In fact, the Foundation was reluctant to take it on, unsure whether they would be able to host such a project development at that time. Back then, that was a wise decision.
Erik Möller, then CTO of the Foundation, was the driving force behind a major change: instead of turning the individual Wikipedias semantic, we would have a single Wikidata for all languages. Erik was also the one who had secured the domain for Wikidata. Many years prior.
Over the next half year and with the help of the Wikimedia Foundation, we secured funding from AI2 (Paul Allen), Google (who had acquired Freebase in the meantime), and the Gordon and Betty Moore Foundation, 1.3 million.
Other funders backed out because I insisted on the Wikidata ontology to be entirely under the control of the community. They argued to have professional ontologists, or reuse ontologies, or to use DBpedia to seed Wikidata. I said no. I firmly believed, and still believe, that the ontology has to be owned, created and maintained by the community. I invited the ontologists to join the project as community members, but to the best of my knowledge, they never made significant contributions. We did miss out on quite a bit of funding, though.
There we were. We had the funding and the project proposal, but no one to host us. We were even thinking of founding a new organisation, or hosting it at KIT, but due to the RENDER collaboration, Mathias Schindler had us talk with Pavel Richter, ED of Wikimedia Deutschland, and Pavel offered to host the development of Wikidata.
For Pavel and Wikimedia Deutschland this was a big step: the development team would significantly increase WMDE (I think, almost double it in size, if I remember correctly), which would necessitate a sudden transformation and increased professionalisation of WMDE. But Pavel was ready for it, and managed this growth admirably.
On April 1st 2012, we started the development of Wikidata. On October 29 2012 we launched the site.
The original launch was utterly useless. All you could do was creating new pages with Q IDs (the Q being a homage to Kamara, my wife), associated those Q IDs with labels in many languages, and connect to articles in Wikipedia, so called sitelinks. You could not add any statements yet. You could not connect items with each other. The sitelinks were not used anywhere. The labels were not used anywhere. As I said, the site was completely useless. And great fun, at least to me.
QIDs for entities are still being often disparaged. Why QIDs? Why not just the English name? Isn't dbp:Tokyo much easier to understand than Q1490? It was an uphill battle ten years ago to overcome the anglocentricity of many people. Unfortunately, this has not changed much. I am thankful to the Wikimedia movement to be one of the places that encourages, values, and supports the multilingual approach of Wikidata.
Over the next few months, the first few Wikipedias were able to access the sitelinks from Wikidata, and started deleting the sitelinks from their Wikipedias. This lead to a removal of more than 240 million lines of wikitext across the Wikipedias. 240 million lines that didn't need to be maintained anymore. In some languages, these lines constituted more than half of the content of the Wikipedia. In many languages, editing activity dropped dramatically at first, sometimes by 80%.
But then something happened. Those edits were mostly bots. And with those bots gone, humans were suddenly better able to see each other and build a more meaningful community. In many languages, this eventually lead to an increased community activity.
One of my biggest miscalculations when launching Wikidata was to entirely dismiss the possibility of a SPARQL endpoint. I thought that none of the existing open source triple stores would be performant enough. Peter Haase was instrumental in showing that I was wrong. Today, the SPARQL endpoint is an absolutely crucial piece of the Wikidata infrastructure, and is widely used to explore the dataset. And with its beautiful visualisations, I find it almost criminally underused. Unfortunately, the SPARQL endpoint is also the piece of infrastructure that worries us the most. The Wikimedia Foundation is working hard on figuring out the future for this service, and if you can offer substantial help, please reach out.
Today, Wikidata has more than 1.4 billion statements about approximately 100 million topics. It is by far the most edited Wikimedia project, with more edits than the English, German, and French Wikipedia together - even though they are each a decade older than Wikidata.
Wikidata is widely used. Almost every time Wikipedia serves one of its 24 billion monthly page views. Or during the pandemic in order to centralise the data about COVID cases in India to make them available across the languages of India. By large companies answering questions and fulfilling tasks with their intelligent assistants, be it Google or Apple or Microsoft. By academia, where you will find thousands of research papers using Wikidata. By numerous Open Source projects, by one-off analyses by data scientists, by small enterprises using the dataset, by student programmers exploring and playing with it on the weekend, by spreadsheet enthusiasts enriching their data, by scientists, librarians and curators linking their datasets to Wikidata, and thus to each other. Already, more than 7,000 catalogs are linked to Wikidata, and thus to each other, really and substantially establishing a Web of linked data.
I will always remember the Amazon developer who approached me after a talk. He had used Wikidata to gather data about movies. I was surprised: Amazon owns imdb, why would they ever use anything else for movies? He said that imdb was great for what it had, but Wikidata complemented it in unexpected ways, offering many interesting connections between the movies and other topics which would be out of scope for imdb.
Not to be misunderstood: knowledge bases such as imdb are amazing, and Wikidata does not aim to replace them. They often have a clear scope, have a higher quality, and almost always a better coverage in their field than Wikidata ever can hope to have, or aims to have. And that's OK. Wikidata's goal is not to replace these knowledge bases. But to provide the connecting tissue between the many knowledge bases out there. To connect them. To provide a common set of entities to work with. To turn the individual knowledge bases into a large interconnected Web of knowledge.
I am still surprised that Wikidata is not known more widely among developers. It always makes me smile with joy when I see yet another developer who just discovered Wikidata and writes an excited post about it and how much it helped them. In the last two weeks, I stumbled upon two projects who used Wikidata identifiers where I didn't expect them at all, just used them as if it was the most normal thing in the world. This is something I hope we will see even more in the future. I hope that Wikidata will become the common knowledge base that is ubiquitously used by a large swarm of intelligent applications. Not only to make these applications be smarter, by knowing more about the world - but also by allowing these applications to exchange data with each other more effectively because they are using the same language.
And most importantly: Wikidata has a healthy, large, and comparatively friendly and diverse community. It is one of the most active Wikimedia projects, only trailing the English Wikipedia, and usually similarly active as Commons.
Last time I checked, more than 400,000 people have contributed to Wikidata. For me, that is easily the most surprising number about the project. If you had asked me in 2012 how many people would contribute to Wikidata, I would have sheepishly hoped for a few hundred, maybe a few thousand. And I would have defensively explained why that's OK. I am humbled and awestruck by the fact that several hundred thousand people have contributed to an open knowledge base that is available to everyone, and that everyone can contribute to.
And that I think is the most important role that Wikidata plays. That it is a place that everyone can contribute to. That the knowledge base that everyone uses is not owned and gateguarded by any one company or government, but that it is a common good, that everyone can contribute to. That everyone with an internet connection can lend their voice to the sum of all knowledge.
We all own Wikidata. We are responsible for Wikidata. And we all benefit from Wikidata.
It has been an amazing ten years. I am looking forward to many more years of Wikidata, and to the many new roles that it will play in the years to come, and to the many people who will contribute to it.
Shoutout to the brilliant team that started the work on Wikidata: Lydia Pintscher, Abraham Taherivand, Daniel Kinzler, Jeroen De Dauw, Katie Filbert, Tobias Gritschacher, Jens Ohlig, John Blad, Daniel Werner, Henning Snater, and Silke Meyer.
And thank you for all these amazing pictures of cakes for Wikidata's birthday. (And if you're curious what is coming next: we are working on Wikifunctions and Abstract Wikipedia, in order to allow more people to contribute more knowledge to even more people!)
Markus Krötzsch ISWC 2022 keynote
A brilliant keynote by Markus Krötzsch for this year's ISWC.
"The era of standard semantics has ended"
Yes, yes! 100%! That idea was in the air for a long time, but Markus really captured it in clear and precise language.
This talk is a great birthday present for Wikidata's ten year anniversary tomorrow. The Wikidata community had over the last years defined numerous little pockets of semantics for various use cases, shared SPARQL queries to capture some of those, identified constraints and reasoning patterns and shared those. And Wikidata connecting to thousands of external knowledge bases and authorities, each with their own constraints - only feasible since we can, in a much more fine grained way, use the semantics we need for a given context. The same's true for the billions of Schema.org triples out there, and how they can be brought together.
The middle part of the talk goes into theory, but make sure to listen to the passionate summary at 59:40, where he emphasises shared understanding, that knowledge is human, and the importance of community.
"Why have people ever started to share ontologies? What made people collaborate in this way?" Because knowledge is human. Because knowledge is often more valuable when it is shared. The data available on the Web of linked data, including Wikidata, Data Commons, Schema.org, can be used in many, many ways. It provides a common foundation of knowledge that enables many things. We are far away from using it to its potential.
A remark on triples, because I am still thinking too much about them: yes to Markus's comments: "The world is not triples, but we make it triples. We break down the world into triples, but we don't know how to rebuild it. What people model should follow the technical format is wrong, it should be the other way around" (rough quotes)
At 1:17:56, Markus calls back our discussions of the Wikidata data model in 2012. I remember how he was strongly advocating for more standard semantics (as he says), and I was pushing for more flexible knowledge representations. It's great to see the synthesis in this talk.
Karl-Heinz Witzko
Ich hatte unglaublich gutes über das DSA Abenteuer "Jenseits des Lichts" gehört. Aber auch, dass es sehr schwer zu spielleiten sei. Ich sprach Karl-Heinz Witzko darauf an, den Autor des Abenteuers, und er sagte, er würde es für mich leiten. Wir müssten nur eine Zeit finden.
Wann auch immer wir uns trafen, versprachen wir uns gegenseitig, Zeit dafür zu finden. Ich hatte das Buch gekauft, aber natürlich nicht gelesen, und war immer sehr gespannt darauf, was es wohl mit dem Abenteuer auf sich hatte.
Karli hat zu DSA seine ganz einzigartige Stimme beigetragen. Ein Werk wie DSA, eine Welt wie Aventurien, entstammt nicht aus dem Kopf einer einzigen Person, sondern hunderte schufen und trugen bei. Und Karli's Stimme hatte ihren ganz eigenen Humor, und erweiterte die Welt um Perspektiven und Eigenheiten die sonst nie entdeckt worden wären. Ich habe seine Romane mit viel Schmunzeln gelesen, seine Solos sehr gerne und wiederholt gespielt und erforscht, nur sein einziges Gruppenabenteuer kannte ich nicht. Nach seiner Zeit bei DSA schrieb Karli weitere Romane und erschuf weitere Welten.
Am 29. September 2022 ging Karli von uns. Der Name Karl-Heinz Witzko wurde aus dem "Buch der Anwesenden" gestrichen, und ins "Buch der Abwesenden" eingetragen. Altem Brauch auf Maraskan folgend werden Karli nun die Sechszehn Ratschläge mit auf dem Weg gegeben, und die Sechszehn Forderungen gestellt. Ich hätte gerne gehört oder gelesen, was Karli aus diesen gemacht hätte.
Danke für Deine Worte. Danke für Deine Zeit. Danke für Deinen Humor.
Heute schlug ich "Jenseits des Lichts" auf und fing an zu lesen.
RIP Steve Wilhite
RIP Steve Wilhite, who worked on CompuServe chat for decades and was the lead of the CompuServe team that developed the GIF format, which is still widely used, and which made the World Wide Web a much more colorful and dynamic place by having a format that allowed for animations. Wilhite incorrectly insisted on GIF being pronounced Jif. Wilhite died on March 14, 2022 at the age of 74.
RIP Christopher Alexander
RIP Christopher Alexander, the probably most widely read actual architect in all of computer science. His work, particularly his book "A Pattern Language" was popularized, among others, by the Gang of Four and Design Pattern work, and is frequently read and cited in Future of Programming and UX circles for the idea that everyone should be able to create, but in order to enable them, they need patterns that make creation possible. His work inspired Ward Cunningham when developing wikis and Will Wright when developing that most ungamelike of games, Sim City. Alexander died on March 17, 2022 at the age of 85.
Ante Vrandečić (1919-1944)
I knew that my father was named for his uncle. His other brother told me about him, and he was telling me that he became a prisoner of war and that they lost his trace. Back then, I didn't dare to ask on which side he was fighting, and when I would have dared to ask, it was too late.
Today, thanks to the increasing digitalisation of older sources and their publication on the Web and the Web being indexed, I accidentally stumbled upon a record about him in a three thousand pages long book, Volume 8 of the "Victims of the War 1941-1945" (Žrtve rata 1941-1945).
He was a soldier in the NOV i POJ (Yugoslav partisans), became a prisoner of war, and was killed by Germans during a transport in 1944. I don't know where he was captured, from where to where he was transported, where he was killed.
My father, his namesake, then moved to Germany in the 1970s, where he and my mother built a new life for themselves and their children, and where I was born.
I have a lot of complicated emotions and thoughts.
- Source: Page 79 in https://www.muzejgenocida.rs/images/ZrtvePub/Hrv.pdf
A quick draft for a curriculum for Computer Science
The other day, on Facebook, I was asking the question who would be the person closest to being a popularizer for ideas in Computer Science to the wider audience, which lead to an interesting and insightful discussion.
Pat Hayes asked what I would consider the five (or so) core concepts of Computer Science. Ernest Davis answer with the following short list (not in any particular order):
- Virtual machine
- Caching
- Algorithm
- Data structure
- Programming language
And I followed up with this drafty, much longer answer:
- how and why computation works; that a computation is a mapping from your problem domain into some machine state, then we have some automatic movement, and the result represents an answer to your question; that it is always layers of interpretation; that it doesn't matter whether the computing machine is made of ICs or of levers, marbles, and gravity (i.e. what is a function); that computation is always real and you can't simulate computation; what can be done with computation and what cannot; computational thinking - this might map to number 1 in Ernest's list
- that everything can be represented with zeros and ones, but doesn't have to be; it could also be represented by A and B and Cs, and many other ways; that two states are simply convenient for electric devices; that all information, all data, all input to all computation, and the steps for computations themselves are represented with zeros and ones (i.e. the von Neumann architecture and binary encoding); what can be represented in this paradigm and what cannot - this might map to number 4 in Ernest's list
- how are functions encoded; how many different functions can have the same results; how wildly different in efficiency functions can be even when they have the same result; why that makes some things quick to calculate whereas others take a long time; basically smearing ideas from lambda calculus and assembler and building everything from NAND circuits; why this all maps to higher level languages such as JavaScript - this might map to ideas from 2, 3, and 5 on Ernest's list
- bringing it back to the devices; where does, physically, the computation happen, where is physically the data stored, and why it matters in terms of privacy, equity, convenience, economics, interdependence, even freedom and independence; what kind of computations and data storage we can expect to have in our mobile phones, in a data center, in an RFID card; how long the turnaround times are in each case; how cryptography works and what kind of guarantees it can provide; why centralization is so alluring and what the price of that might be; and what might be the cost of computation for the environment
- given our times, and building on the previous lessons, what is the role of machine learning; how does it actually work, why does it work as good as it does, and why does it not work when it doesn't and where can't it work; what does this have to with "intelligence", if it does; what becomes possible because of these methods, and what it costs; why these methods may reinforce inequities; but also how they might help us with significantly increasing access to better health care for many people are allow computers to have much more intuitive interfaces and thus democratize access to computing resources
I think the intuitions in 1, 2, and maybe 3 are really the core of computer science, and then 4 and 5 provide shortcuts to important questions four ourselves and society that, I think, would be worthwhile for everyone to ponder and have an informed understanding of the situation so that they can meaningfully make relevant decisions.
The Strange Case of Booker T. Washington’s Birthday
A lovely geeky essay about how much work a single edit to Wikipedia can be. I went down this kind of rabbit holes myself more than once, and so I very much enjoyed the essay.
Wordle is good and pure
The nice thing about Wordle - whether you play it or not, whether you like it or not - is that it is one of those good, pure things the Web was made for. A simple Website, without ads, popups, monetization, invasive tracking, etc.
You know, something that can chiefly be done by someone who already has a comfortable life and won't regret not having monetized this. The same way scientists mainly have been "gentleman scientist". Or tenured professors who spent years on writing novels.
And that is why I think that we should have a Universal Basic Income. To unlock that creativity. To allow for ideas from people who are not already well off to see the light. To allow for a larger diversity of people to try more interesting things.
Thank you for coming to my TED talk.
P.S.: on January 31, five days after I wrote this text, Wordle was acquired by the New York Times for an undisclosed seven-digit sum. I think that is awesome for Wardle, the developer of Wordle, and I still think that what I said was true at that time and still mostly is, although I expect the Website now to slowly change to have more tracking, branding, and eventually a paywall.
Meat Loaf
"But it was long ago
And it was far away
Oh God, it seemed so very far
And if life is just a highway
Then the soul is just a car
And objects in the rear view mirror may appear closer than they are."
Bat out of Hell II: Back into Hell was the first album I really listened to, over and over again. Where I translated the songs to better understand them. Paradise by the Dashboard Light is just a fun song. He was in cult classic movies such as The Rocky Horror Picture Show, Fight Club, and Wayne's World.
Many of the words we should remember him for are by Jim Steinman, who died last year and wrote many of the lyrics that became famous as Meat Loaf's songs. Some of Meat Loaf's own words better not be remembered.
Rock in Peace, Meat Loaf! You have arrived at your destination.
Map of current Wikidata edits
It starts entirely black and then listens to Wikidata edits. Every time an item with a coordinate is edited, a blue dot in the corresponding place is made. So slowly, over time, you get a more and more complete map of Wikidata items.
If you open the developer console, you can get links and names of the items being displayed.
The whole page is less than a hundred lines of JavaScript and HTML, and it runs entirely in the browser. It uses the Wikimedia Stream API and the Wikidata API, and has no code dependencies. Might be fun to take a look if you're so inclined.
https://github.com/vrandezo/wikidata-edit-map/blob/main/index.html
White's illusion
I stumbled upon "White's Illusion" and was wondering - was this named after a person called White, or was this named because, well it is an illusion where the colour white plays an important role?
As usual in this case, I started at Wikipedia's article on White's illusion. But Wikipedia didn't answer that question. The references at the bottom also didn't list to anyone named White. So I started guessing it's about the colour.
But wait! Skimming the article there was a mention to "White and White (1985)" - but without any further citation information. So not only one White but two of them!
Google Scholar and Semantic Scholar didn't help me resolving "White and White (1985)" to a proper paper, so I started suspecting that this was a prank that someone entered into the article. I started checking the other references, but they indeed reference papers by White! And with those more complete references I was able to find out that Michael White and Tony White wrote that 1985 paper, that they are both Australian, that Michael White wrote a number of other papers about this illusion and others, and that this is Tony White's only paper.
I added some of the info to the article, but that was a weird ride.
She likes music, but only when the music is loud
Original in German by Herbert Grönemeyer, 1983.
She sits on her windsill all day
Her legs dangling to the music
The noise from her room
drives all the neighbours mad
She is content
smiles merrily
She doesn't know
that snow
falls
without a sound
to the ground
Doesn't notice
the knocking
on the wall
She likes music
but only
when the music is loud
When it hits her stomach
with the sound
She likes music
but only
when the music is loud
When her feet feel
the shaking ground
She then forgets
that she is deaf
The man of her dreams
must play the bass
the tickling in her stomach
drives her crazy
Her mouth seems
to scream
with happiness
silently
her gaze removed
from this world
Her hands don't know
with whom to talk
No one's there
to speak to her
She likes music
but only
when the music is loud
When it hits her stomach
with the sound
She likes music
but only
when the music is loud
When her feet feel
the shaking ground
A sermon on tolerance and inclusion
- Warning: meandering New Year's sermon ahead, starting at a random point and going somewhere entirely else.
I started reading Martin Kay's book on Translation, and I am enjoying it quite a bit so far. Kay passed away August 2021. His work seems highly relevant for the work on Abstract Wikipedia.
One thing that bummed me though is that for more than a page in the introduction he rants about pronouns and how he is going to use "he" to generically mean both men and women, and how all other solutions have deficits.
He culminates in the explanation: "Another solution to this problem is which is increasing in popularity, is to use both 'he' and 'she', shifting between them more or less randomly. So we will sometimes get 'When a translator is confronted with a situation of this kind, she must decide...'. The trouble with this is that some readers, including the present writer, reacts quite differently to the sentence depending on which version of the generic pronoun it contains. We read the one containing 'he' smoothly and, all else being equal, assimilate the intended meaning. Encountering the one with 'she', on the other hand, is like following a television drama that is suddenly interrupted by a commercial."
Sooo frustratingly close to getting it.
I wish he'd had just not spent over a page on this topic, but just used the generic 'he' in the text, and that's it. I mean, I don't expect everyone born more than eighty years ago to adjust to the modern usage of pronouns.
Now, I am not saying that to drag Kay's name through dirt, or to get him cancelled or whatever. I have never met him, but I am sure he was a person with many positive facets, and given my network I wouldn't be surprised if there are people who knew him and can confirm so. I'm also not saying that to virtue signal and say "oh man, look how much more progressive I am". Yes, I am slightly annoyed by this page. Unlike many others though, I am not actually personally affected by it - I use the pronoun "he" for myself and not any other pronoun, so this really is not about me. Is it because of that that it is easy for me to gloss over this and keep reading?
So is it because I am not affected personally that it is so easy for me to say the following: it is still worthwhile to keep reading his work, and the rest of the book, and to build on top of his work and learn from him. The people we learn some things from, the influences we accept, they don't have to be perfect in every way, right? Would it have been as easy for me to say that if I were personally affected? I don't know.
I am worried about how quickly parts of society seems to be ready to "cancel" and "call out" people, and how willing they are to tag a person as unacceptable because they do not necessarily share every single belief that is currently regarded as a required belief.
I have great difficulties in drawing the line. Which beliefs or actions of a person should be sufficient grounds to shun them or their work? When JK Rowling doubles down on her stance regarding trans women, is this enough to ask everyone to drop all interest in the world she created and the books she wrote? Do we reshoot movie scenes such as the cameo of Donald Trump in Home Alone 2 in order to "purify" the movie and make it acceptable for our new enlightened age again? When Johnny Depp was accused of domestic abuse, does he need to be recast from movies he had already been signed on? Do we also need to stop watching his previous movies? Do the believable accusations of child abuse against Marion Zimmer Bradley mean that we have to ignore her contributions to feminist causes, never mind her books? Should we stop using a font such as Gill Sans because of the sexual abuse Erjc Gill committed against his daughters? Do we have to stop watching movies or listen to music produced by murderers such as OJ Simpson, Phil Spector, or Johnny Lewis?
I intentionally escalated the examples, and they don't compare at all to Kay's defence of his usage of pronouns.
I offer no answers as to where the line should be, I have none. I don't know. In my opinion, none of us is perfect, and none of our idols, paragons, or example model humans will survive the scrutiny for perfection. This is not a new problem. Think of Gandhi, Michael Jackson, Alice Schwarzer, Socrates - no matter where you draw your idols from, they all come with imperfections, sometimes massive ones.
Can we keep and accept their positive contributions - without ignoring their faults? Can we allow people with faults to still continue to contribute their skills to society, or do we reduce them to their faults and negatives? Do we have to get someone fired for tweeting a stupid joke? Do we demand perfection by everyone at all time?
Or do we allow everyone to be human, make and have errors, and have beliefs many don't deem acceptable? Committing or causing actions resulting from these beliefs? Even if these actions and beliefs hurt or endanger people, or deny the humanity of others? We don't have to and should not accept their racism, sexism, homo- and transphobia - but can and should we still recognise their other contributions?
I am worried about something else as well. By pushing out so many because of the one thing they don't want to accept in the basket of required beliefs, we push them all into the group of outsiders. But if there are too many outsiders, the whole system collapses. Do we all have to have the same belief on guns, on climate, on gender, on abortion, on immigration, on race, on crypto, on capitalism, on housing? Or can we integrate and work together even if we have differences?
The vast majority of Americans think that human-caused climate change is real and that we should act to avoid it. Only 10% don't. And yet, because of the way we define and fence our in- and outgroups, we have a strong voting block that repeatedly leads to outright sabotage to effective measures. A large majority of Americans support the right to abortion, but you would never be able to tell given the fights around laws and court cases. Taxing billionaires more effectively is highly popular with voters, but again these majorities fizzle away and don't translate to the respective changes in the tax code.
I think we should be able to work together with people we don't agree with on everything. We should stop requiring perfection and alignment on all issues before moving forward. But then again, that's what I am saying, and I am saying it from a position of privilege, am I not? I am male. I am White. I am heterosexual. I am not Muslim or Jewish. I am well educated. I am not poor. I am reasonably technologically savvy. I am not disabled. What right do I have at all to voice my opinion on these topics? To demand for acceptance people with beliefs that hurt or endanger people who are not like me. Or even to ask for your precious attention for these words of mine?
None.
And yet I hope that we will work together towards progress on the topics we agree on, that we will enlighten each other on the topics we disagree on, and that we will be able to embrace more of us on our way into the future.
P.S.: this post is problematic and not very well written, and I recognise that. Please refer to the discussion about it on Facebook.
Long John and Average Joe
You may know about Long John Silver. But who's the longest John? Here's the answer according to Wikidata: https://w.wiki/4dFL
What about your Average Joe? Here's the answer about the most average Joe, based on all the Joes in Wikidata: https://w.wiki/4dFR
Note, the average height of a Joe in Wikidata is 1,86cm or 6'1", which is quite a bit higher than the average height in the population. A data collection and coverage issue: it is much more likely to have the height for a basketball player than for an author in Wikidata.
Just two silly queries for Wikidata, which are nice ways to show off the data set and what one can do with the SPARQL query endpoint. Especially the latter one shows off a rather interesting and complex SPARQL query.
Temperatures in California
It has been a bit chillier the last few days. I noticed that after almost a decade in California, I feel pretty comfortable with understanding temperatures in Fahrenheit - as long as they are over 60° F. If it is colder, I need to switch to Celsius in order to understand how cold it exactly is. I have no idea what 40° or 45° or 50° F are, but I still know what 5° C is!
The fact that I still haven't acclimatised to Fahrenheit for the cooler temperatures tells you a lot about the climate in California.
SWSA panel
Thursday, October 7, 2021, saw a panel of three founding members of the Semantic Web research community, who each have been my teachers and mentors over the years: Rudi Studer, Natasha Noy, and Jim Hendler. I loved watching the panel and enjoyed it thoroughly, also because it was just great to see all of them again.
There were many interesting insights and thoughts in this panel, too many to write them all down, but I want to mention a few.
It was interesting how much all panelists talked about creating the Semantic Web community, and how much of an intentional effort that was. Deciding that it needs a conference, a journal, an organization, setting those up, and their interactions. Seeing and fostering a sustainable research community grown out of an idea is a formidable and amazing effort. They all mentioned positively the diversity in the community, and that it was a conscious effort to work towards that. Rudi mentioned that the future challenge will be with ensuring that computer science students actually have Semantic Web technologies integrated into their standard curriculum.
They named a number of the successes that were influenced by the Semantic Web research work, such as Schema.org, the heavy use of SPARQL in supercomputing (I had no idea!), Wikidata (thanks for the shout out, Rudi!), and the development of scalable graph databases. Natasha raised the advantage of having common identifiers throughout an organization, i.e. that everyone refers to California the same way. They also named areas that remained elusive and that they expect to see progress in the coming years, Rudi in particular mentioned Agents and Common Sense, which was echoed by the other participants, and Jim mentioned Personal Knowledge Graphs. Jim mentioned he was surprised by the growing importance of unstructured data. Jim is also hoping for something akin to “procedural attachments” - you see some new data coming in, you perform this action (I would like to think that a little Wikifunctions goes a long way).
We need both, open knowledge graphs and closed knowledge graphs (think of your personal ones, but also the ones by companies).
The most important contribution so far and also well into the future was the idea of decentralization of semantics. To allow different stakeholders to work asynchronously and separately on parts of the semantics and yet share data. This also includes the decentralization of knowledge graphs, but also in the future we will encounter a world where semantics are increasingly brought together and yet decentralized.
One interesting anecdote was shared by Natasha. She was talking about a keynote by Guha (one of the few researchers who were namechecked in the panel, along with Tim Berners-Lee) at ISWC in Sydney 2013. How Guha was saying how simple the technology needs to be, and how there were many in the audience who were aghast and shocked by the talk. Now, eight years later and given her experience building Dataset Search, she appreciates the insights. If they have a discussion about a new property for longer than five minutes, they drop it. It’s too complicated, and people will use it wrong so often that the data cleanup will become expensive.
All of them shared the advice for researchers in their early career stage to work on topics that truly inspire them, on problems that are real and that they and others care about, and that if they do so, the results have the best chance to have impact. Think about problems you can explain to people not in your field, about “how can we use triples to save the world” - and not just about “hey, look, that problem that we solved with these other technologies previously, now we can also solve it with Semantic Web technologies”. This doesn’t really help anyone. Solve new problems. Solve real problems. And do what you are truly passionate about.
I enjoyed the panel, and can recommend everyone in the Semantic Web research area or any related, nearby research, to check it out. Thanks to the organizers for this talk (which is the first session in a series of talks that will continue with Ora Lassila early December).
Our four freedoms for our technology
(This is a draft. Comments are welcome. This is not meant as an attack on any person or company individually, but at certain practises that are becoming increasingly prevalent)
We are not allowed to use the devices we paid for in the ways we want. We are not allowed to use our own data in the way we want. We are only allowed to use them in the way the companies who created the devices and services allow us.
Sometimes these companies are nice and give us a lot of freedom in how to use the devices and data. But often they don’t. They close them down for all kinds of reasons. They may say it is for your protection and safety. They might admit it is for profit. They may say it is for legal reasons. But in the end, you are buying a device, or you are creating some data, and you are not allowed to use that device and that data in the way you want to, you are not allowed to be creative.
The companies don’t want you to think of the devices that you bought and the data that you created as your devices and your data. They want you to think of them as black boxes that offer you services they create for you. They don’t want you to think of a Ring doorbell as a camera, a microphone, a speaker, and a button, but they want you to think of it as providing safety. They don’t want you to think of the garage door opener as a motor and a bluetooth module and a wifi module, but as a garage door opening service, and the company wants to control how you are allowed to use that service. Companies like Chamberlain and SkyLink and Genie don’t allow you to write a tool to check on your garage door, and to close or open it, but they make deals with Google and Amazon and Apple in order to integrate these services into their digital assistants, so that you can use it in the way these companies have agreed on together, through the few paths these digital assistants are available. The digital assistant that you buy is not a microphone and a speaker and maybe a camera and maybe a screen that you buy and use as you want, but you buy a service that happens to have some technical ingredients. But you cannot use that screen to display what you want. Whether you can watch your Amazon Prime show on the screen of a Google Nest Hub depends on whether Amazon and Google have an agreement with each other, not on whether you have paid for access to Amazon Prime and you have paid for a Google Nest Hub. You cannot use that camera to take a picture. You cannot use that speaker to make it say something you want it to say. You cannot use the rich plethora of services on the Web, and you cannot use the many interesting services these digital assistants rely on, in novel and creative combinations.
These companies don’t want you to think of the data that you have created and that they have about you as your data. They don’t want you to think about this data at all. They just want you to use their services in the way they want you to use their services. On the devices they approve. They don’t want you to create other surfaces that are suited to the way you use your data. They don’t want you to decide on what you want to see in your feed. They don’t want you to be able to take a list of your friends and do something with it. They will say it is to protect privacy. They will say that it is for safety. That is why you cannot use the data you and your friends have created. They want to exactly control what you can and cannot do with the data you and your friends have created. They want to control how many ads you must see in order to be allowed to see your friends’ posts. They don't want anyone else to have the ability to provide you creative new interfaces to your feed. They don’t want you yourself the ability to look at your feed and do whatever you want with it.
Those are devices you paid for.
These are data you and your friends have created.
And more and more we are losing our freedom of using our devices and our data as we like.
It would be impossible to invent email today. It would be impossible to invent the telephone today. Both are protocols that allow everyone to communicate with anyone no matter what their email provider or their phone is. Try reading your friend’s Facebook feed on Instagram, or send a direct message from your Twitter account to someone on WhatsApp, or call your Skype contact on Facetime.
It would be impossible to launch the Web today - many companies don’t want you browsing the Web. They want you to be inside of your Facebook feed and consume your content there. They want you to be on your Twitter feed. They don’t want you to go to the Website of the New York Times and read an article there, they don’t want you to visit the Website of your friend and read their blog there. They want you to stay on their apps. Per default, they open Websites inside their app, and not in your browser, so you are always within their app. They don’t want you to experience the Web. The Web is dwindling and all the good things on it are being recut and rebundled within the apps and services of tech companies.
Increasingly, we are seeing more and more walls in the world. Already, it is becoming impossible to pay and watch certain movies and shows without buying into a full subscription in a service. We will likely see the day where you will need a specific device to watch a specific movie. Where the only way to watch a Disney+ exclusive movie is on a Disney+ tablet. You don’t think so? Think about how easy it is to get your Kindle books onto another Ebook reader. How do you enable a skill or capability available in Alexa on your Nest smart speaker? How can you search through the books that you bought and are in your digital library, besides by using a service provided by the company that allows you to search your digital library? When you buy a movie today on YouTube or on iMovies, what do you own? What are you left with when the companies behind these services close that service, or go out of business altogether?
Devices and content we pay for, data we and our friends create, should be ours to use in empowering and creative ways. Services and content should not be locked in with a certain device or subscription service. The bundling of services, content, devices, and locking up user data creates monopolies that stifle innovation and creativity. I am not asking to give away services or content or devices for free, I am asking to be allowed to pay for them and then use them as I see fit.
What can we do?
As far as I can tell, the solution, unfortunately, seems to be to ask for regulation. The market won’t solve it. The market doesn’t solve monopolies and oligopolies.
But don’t ask to regulate the tech giants individually. We don’t need a law that regulates Google and a law that regulates Apple and a law that regulates Amazon and a law to regulate Microsoft. We need laws to regulate devices, laws to regulate services, laws to regulate content, laws that regulate AI.
Don’t ask for Facebook to be broken up because you think Mark Zuckerberg is too rich and powerful. Breaking up Facebook, creating Baby Books, will ultimately make him and other Facebook shareholders richer than ever before. But breaking up Facebook will require the successor companies to work together on a protocol to collaborate. To share data. To be able to move from one service to another.
We need laws that require that every device we buy can be made fully ours. Yes, sure, Apple must still be allowed to provide us with the wonderful smooth User Experience we value Apple for. But we must also be able to access and share the data from the sensors in our devices that we have bought from them. We must be able to install and run software we have written or bought on the devices we paid for.
We need laws that require that our data is ours. We should be able to download our data from a service provider and use it as we like. We must be allowed to share with a friend the parts of our data we want to share with that friend. In real time, not in a dump download hours later. We must be able to take our social graph from one social service and move to a new service. The data must be sufficiently complete to allow for such a transfer, and not crippled.
We need laws that require that published content can be bought and used by us as we like. We should be able to store content on our hard disks. To lend it to a friend. To sell it. Anything I can legally do with a book I bought I must be able to legally do with a movie or piece of music I bought online. Just as with a book you are not allowed to give away the copies if the work you bought still enjoys copyright.
We need laws that require that services and capabilities are unbundled and made available to everyone. Particularly as technological progress with regards to AI, Quantum computing, and providing large amounts of compute becomes increasingly an exclusive domain for trillion dollar companies, we must enable other organizations and people to access these capabilities, or run the risk that sooner or later all and any innovation will be happening only in these few trillion dollar companies. Just because a company is really good at providing a specific service cheaply, it should not be allowed to unfairly gain advantage in all related areas and products and stifle competition and innovation. This company should still be allowed to use these capabilities in their products and services, but so should anyone else, fairly prized and accessible by everyone.
We want to unleash creativity and innovation. In our lifetimes we have seen the creation of technologies that would have been considered miracles and impossible just decades ago. These must belong to everybody. These must be available to everyone. There cannot be equity if all of these marvellous technologies can be only wielded by a few companies on the West coast of the United States. We must make them available to all the people of the world: the people of the Indian subcontinent, the people of Subsaharan Africa,the people of Latin America, and everyone else. They all should own the devices they paid for, the data they created, the content they paid for. They all should have access to the same digital services and capabilities that are available to the engineers at Amazon or Google or Microsoft. The universities and research centers of the world should be able to access the same devices and services and extend them with their novel and creative ideas. The scrappy engineers in Eastern Europe and India and Nigeria and Central Asia should be able to call the AI models trained by Google and Microsoft and use them in novel ways to run their devices and chip-powered cars and agricultural machines. We want a world of freedom, tinkering, where creativity and innovation are unleashed, and where everyone can contribute their ideas, their creativity, and where everyone can build their fortune.
The Center of the Universe
The discovery of the center of the universe led to a series of unexpected consequences. It killed some, it enlightened others, but most people just were left utterly confused in the end.
When the results from the Total Radiating Universal Tessellation Hyperfield satellites measurements came in, it became depressingly clear that the universe was indeed contracting. Very slowly, but without any reasonable doubt — or, as the physicists said, they were five sigma sure about it. As the data from the measurements became available, physicists, cosmologists, topologists, even a few mathematically inclined philosophers, and a huge number of volunteers started to investigate it. And after a short period of time, they came to a whole set of staggering conclusions.
First, the Universe had a rather simple four-dimensional form. The only unfortunate blemishes in this theory were the black holes, but most of the volunteers, philosophers, and topologists decided to ignore these as accidental.
Second, the form was bounded. There was a beginning and an end in time, and there were boundaries in space, and those who understood that these were the same were enlightened about the form of the universe.
Third, since the form of the universe was bounded and simple, it had a center. Whereas this was slightly surprising it was a necessary consequence of the previous findings. What first seemed exciting, but soon will turn out not to be only the heart of this report, but the heart of all humanity, was that the data collected by the satellites allowed to calculate the position of the center of the universe.
Before that, let me recapture what we traditionally knew about how the universe is built. Our sun is a star, around which a few planets travel, one of them being our Earth. Our sun is one of a few tens of billions of stars that form a long curved thread which ties around a supermassive black hole. A small number of such threads are tangled together, forming the spiral arms of our galaxy, the Milky Way. Our galaxy consists of half a trillion stars like our sun.
Galaxies, like everything else in the universe, like to stick together and form groups. A few hundred thousand galaxies make up a supercluster. A few of these superclusters together build enormous walls of stars, filaments traversing the universe. The galaxies of such a wall are all in a single plane, more or less, and sometimes even in a single line.
Between these walls, walls made of superclusters and galaxies and stars and planets, there is, basically, nothing. The walls of stars are like gigantic honeycombs, and between them, are enormous empty spaces, hundred million of light years wide. When you look at a honeycomb, you will see that the empty spaces between the walls are much, much larger than the walls themselves. Such is the universe. You might think that the distance from here to the next grocery store is quite far, or that the ocean is quite big. But the distance from the earth to the sun is so much bigger, and the distance from the sun to the next star again so much more. And from our galaxy to the next, there is a huge empty space. Nevertheless, our galaxy is so close to the next group of galaxies that they together form a building block of a huge wall, separating two unimaginable large empty spaces from each other.
So when we figured out that we can calculate the center of the universe, it was widely expected that the center would be somewhere in one of those vast spaces of nothing. The chances that it would be in one of the filaments were tiny.
It turned out that this was not a question of chance.
The center of the universe was not only inside of a filament, but the first quick calculations (quick, though, has to be understood as taking three and a half years) suggested that the center is actually within our filament. And not only within our filament — but our galaxy. Within a one light year radius of our sun.
The team that made these calculations was working at a small research institute in rural Japan. They did not believe the results, and double and triple checked them. The head of the institute had graduated from Princeton, and called his former advisor there. Although it was deep in the night in Japan, they talked for many hours. In the end he learned that Princeton has made the same calculations, and received their own results about eight months ago. They didn’t dare to publish them. There must have been a mistake. These results had to be wrong.
Science has humiliated the whole of humanity again and again. And it was quite successful in doing so. A scientist would much easier accept that the center of the universe is some mathematical construct pointing to nothing than what the infallible mathematics indicated. But the data was out. And the number of people making the above mentioned realizations and calculations continued growing. It was only a matter of time. And when the Catholic University of Rio de Janeiro finally published the results — in a carefully written paper, without any accompanying press release, and formulated so cautiously and defensively — all the scientists who already knew the results held their breath.
The storm was unimaginable. Everyone demanded an explanation, but no one would listen to anyone offering one. The religions rejoiced, claiming they knew it all along, and many flocked to the mosques and churches and temples, as a proof of God was finally found. The irony of science leading humans to the embrace of religion was profoundly lost at that time, but later recognized as one of the largest jokes in history. Science has dealt its ultimate humiliation, not to humanity, but perversely to its most devout followers, the scientists. The scientists, who, while trashing the superiority of humans over the world, were secretly inflating their own, and were now reminded that they were merely slaves to a most cruel mistress. Their bitter resistance to the results did not stop them from emerging.
The mathematics and calculations were soon made public. The mathematics were deceptively simple, once the required factorizations were done, and easy to check. High school courses went through the proofs, and desperate parents peeked over the shoulders of their daughters and sons who, sometimes for the first time, talked of integrals and imaginary numbers. Television and streaming platforms were explaining discriminants and complex numbers and roots of higher degrees. Websites offering math courses bent under the load and moral weight.
There is one weird thing about roots. The root of a number is the number that, multiplied with itself, gives you the original number. The weird thing is that there is usually not a single, unique result to that question. For example, the root of the number four is not just two, but also minus two, as minus two times minus two results in four, too. There are two roots of the second degree (which we usually call the square root). There are three roots of the third degree (sometimes called the cube root). There are four roots of the fourth degree. And so on. All of them are correct. Sometimes you can discard one or the other because the result has to fit certain constraints (say, you are looking only for the positive root of four), but sometimes, you can not.
As the calculations went public, the methods became more and more refined. The results became increasingly precise, and as the data from the satellites poured in, one of the last steps involved a root of the seventh degree. First, this was regarded as a minor curiosity, especially because these seven results led to basically the same point. Cosmologically speaking.
Earth is moving. Earth is moving around the sun, with a speed of a sixty seven thousand miles per hour, or eighteen miles each second. Also the sun is moving, and the earth is moving with the sun, and our galaxy is moving, and with our galaxy the sun moves along, and with the sun our earth. We are racing with a speed of a thousand miles each second in some direction away from the center of the universe.
And it was realized, maybe we just passed the center of the universe. Maybe it was just an accident, maybe all the planets and stars pass the center of the universe at some point. That we are so close to the center of the universe might be just a funny coincidence.
And maybe they are right. Maybe every star will at some point cross the center of the universe within the distance of a light year.
At some point though it was realized that, since the universe was bounded in all four dimensions, there was not only a center in space, but also a center in time, a midpoint between the beginning of the universe and its future end.
All human history is encompassed in the last hundred thousand years. From the mitochondrial Eve and the Y-Chromosomal Adam who lived in Africa, the mother of our mother of our mother, and so on, that we all share, and the father of our father of our father, and so on, that we all share, their descendants, our ancestors, who crossed the then fertile jungle of the Sahara and who afterwards settled the whole planet, painted on the walls of caves and filled the air with music by blowing over grass blades and into hollow bones, wandered over the land bridge connecting Asia with the Americas and traveled over the vast Pacific to discover tiny islands, until the recent invention of the alphabet, all of this happened in the last hundred thousand years. The universe has an age of hundred thousand times a hundred thousand years, roughly. And the fabled midpoint turned out to be within the last few thousand years.
The hopes that our earth was just accidentally next to the center of the universe was shattered. As the precision of the calculations increased, it became clearer and clearer that earth was not merely close to the center of the universe, but back at the midpoint of history, earth was right there in the center. In every single of the seven possible results, Earth was right at the center of the universe. [1]
As the calculations continued over the years, a new class of mystic mathematicians emerged, and many walls between religion and science were shattered. On both sides the unshakeable ones remained: the scientists who would not admit that these results mean anything, that it all is merely a mathematical abstraction; and the priests who say that these results mean nothing, that they don’t tell us about how to live a good life. That these parallels intersect, is the only trace of infinity left.
[1] As the results refined, it seemed that the seven mathematical solutions for the center of time and space turned out to be some very well known dates. So far the precisions calculated was ten years here or there. The well known dates were: 3760 BC, 541 BC, 30 AD, and 610 AD. The other dates turned out to be quite less well known: 10909 BC, 3114 BC, and 1989 AD. The interpretation of the dates led to a well-known series of events all over the world, which we will not discuss here.
(This story was first published on Medium on February 2, 2014 under CC-BY 4.0).
CodeNet problem descriptions on the Web
Project CodeNet is a large corpus of code published by IBM. It has close to one and a half million programs around a bit more than 4,000 problems.
I took the problem descriptions, created a simple index file to those, and uploaded them to the Web to make them easily browseable.
Wikidata or scraping Wikipedia
Yesterday I was pointed to a blog post describing how to answer an interesting project: how many generations from Alfred the Great to Elizabeth II? Alfred the Great was a king in England at the end of the 9th century, and Elizabeth II is the current Queen of England (and a bit more).
The author of the blog post, Bill P. Godfrey, describes in detail how he wrote a crawler that started downloading the English Wikipedia article of Queen Elizabeth II, and then followed the links in the infobox to download all her ancestors, one after the other. He used a scraper to get the information from the Wikipedia infoboxes from the HTML page. He invested quite a bit of work in cleaning the data, particularly doing entity reconciliation. This was then turned into a graph and the data analyzed, resulting in a number of paths from Elizabeth II to Alfred, the shortest being 31 generations.
I honestly love these kinds of projects, and I found Bill’s write-up interesting and read it with pleasure. It is totally something I would love to do myself. Congrats to Bill for doing it. Bill provided the dataset for further analysis on his Website. Thanks for that!
Everything I say in this post is not meant, in any way, as a criticism of Bill. As said, I think he did a fun project with interesting results, and he wrote a good write-up and published his data. All of this is great. I left a comment on the blog post sketching out how Wikidata could be used for similar results.
He submitted his blog post to Hacker News, where a, to me, extremely surprising discussion ensued. He was pointed rather naturally and swiftly to Wikidata and DBpedia. DBpedia is a project that started and invested heavily in scraping the infoboxes from Wikipedia. Wikidata is a sibling project of Wikipedia where data can be directly maintained by contributors and accessed in a number of machine-readable ways. Asked why he didn’t use Wikidata, he said he didn’t know about it. All fair and good.
But some of the discussions and comments on Hacker News surprised me entirely.
Expressing my consternation, I started discussions on Twitter and on Facebook. And there were some very interesting stories about the pain of using Wikidata, and I very much expect us to learn from them and hopefully make things easier. The number of API queries one has to make in order to get data (although, these numbers would be much smaller than with the scraping approach), the learning curve about SPARQL and RDF (although, you can ignore both, unless you want to use them explicitly - you can just use JSON and the Wikidata API), the opaqueness of the identifiers (wdt:P25 wd:Q9682 instead of “mother” and “Queen Elizabeth II”) were just a few. The documentation seems hard to find, there seem to be a lack of libraries and APIs that are easy to use. And yet, comments like "if you've actually tried getting data from wikidata/wikipedia you very quickly learn the HTML is much easier to parse than the results wikidata gives you" surprised me a lot.
Others asked about the data quality of Wikidata, and complained about the huge amount of bad data, duplicates, and the bad ontology in Wikidata (as if Wikipedia wouldn’t have these problems. I mean how do you figure out what a Wikipedia article is about? How do you get a list of all bridges or events from Wikipedia?)
I am not here to fight. I am here to listen and to learn, in order to help figuring out what needs to be made better. I did dive into the question of data quality. Thankfully, Bill provides his dataset on the Website, and downloading the query result for the following query - select * { wd:Q9682 (wdt:P25|wdt:P22)* ?p . ?p wdt:P25|wdt:P22 ?q } - is just one click away. The result of this query is equivalent to what Bill was trying to achieve - a list of all ancestors of Elizabeth II. (The actual query is a little bit more complex, because we also fetch the names of the ancestors, and their Wikipedia articles, in order to help match the data to Bill’s data).
I would claim that I invested far less work than Bill in creating my graph data. No data cleansing, no scraping, no crawling, no entity reconciliation, no manual checking. How about the quality of the two datasets?
Update: Note, this post is not a tutorial to SPARQL or Wikidata. You can find an explanation of the query in the discussion on Hacker News about this post. I really wanted to see how the quality of the data using the two approaches compares. Yes, it is an unfamiliar language for many, but I used to teach SPARQL and the basics of the languages seem not that hard to learn. Try out this tutorial for example. Update over
So, let’s look at the datasets. I will refer to the two datasets as the scrape (that’s Bill’s dataset) and Wikidata (that’s the query result from Wikidata, as of the morning of August 20 - in particular, none of the errors in Wikidata mentioned below have been fixed).
In the scrape, we find 2,584 ancestors of Elizabeth II (including herself). They are connected with 3,528 parenthood relationships.
In Wikidata, we find 20,068 ancestors of Elizabeth II (including herself). They are connected with 25,414 parenthood relationships.
So the scrape only found a bit less than 13% of the people that Wikidata knows about, and close to 14% of the relationships. If you ask me, that’s quite a bad recall - almost seven out of eight ancestors are missing.
Did the scrape find things that are missing in Wikidata? Yes. 43 ancestors are in the scrape which are missing in Wikidata, and 61 parenthood relationships are in the scrape which are missing from Wikidata. That’s about 1.8% of the data in the scrape, or 0.24% compared to the overall parent relationship data of Elizabeth II in Wikidata.
I evaluated the complete list of those relationships from the scrape missing from Wikidata. They fall into five categories:
- Category 1: Errors that come from the scraper. 40 of the 61 relationships are errors introduced by the scrapers. We have cities or countries being parents - which isn’t too terrible, as Bill says in the blog post because they won’t have parents themselves and won’t participate in the original question of findinging the lineage from Alfred to Elizabeth, so no problem. More problematic is when grandparents or great-grandparents are identified as the parent, because this directly messes up the counting of generations: Ügyek is thought to be a son, not a grandson of Prince Csaba, Anna Dalassene is skipping two generations to Theophylact Dalassenos, etc. This means we have an error rate of at least 1.1% in the scraper dataset, besides having the low recall rate mentioned above.
- Category 2: Wikipedia has an error. Those are rare, it happened twice. Adelaide of Metz had the wrong father and Sophie of Mecklenburg linked to the wrong mother in the infobox (although the text was linking to the right one). The first one has been fixed since Bill ran his scraper (unlucky timing!), and I fixed the second one. Note I am linking to the historic version of the article with the error.
- Category 3: Wikidata was missing data. Jeanne de Fougères, Countess of La Marche and of Angoulême and Albert Azzo II, Margrave of Milan were missing one or both of their parents, and Bill’s scraping found them. So of the more than 3,500 scraped relationships, only 2 were missing! I added both.
- In addition, correct data was marked deprecated once. I fixed that, too.
- Category 4: Wikidata has duplicates, and that breaks the chain. That happened five times, I think the following pairs are duplicates: Q28739301/Q106688884, Q105274433/Q40115489, Q56285134/Q354855, Q61578108/Q546165 and Q15730031/Q59578032. Duplicates were mentioned explicitly in one of the comments as a problem, and here we can see that they happen with quite a bit of frequency, particularly for non-central items. I merged all of these.
- Category 5: the situation is complicated, and different Wikipedia versions disagree, because the sources seem to disagree. Sometimes Wikidata models that disagreement quite well - but often not. After all, we are talking about people who sometimes lived more than a millennium ago. Here are these cases: Albert II, Margrave of Brandenburg to Ada of Holland; Prince Álmos to Sophia to Emmo of Loon (complicated by a duplicate as well); Oldřich, Duke of Bohemia to Adiva; William III to Raymond III, both Counts of Toulouse; Thored to Oslac of York; Bermudo II of León to Ordoño III of León (Galician says IV); and Robert Fitzhamon to Hamo Dapifer. In total, eight cases. I didn't edit those as these require quite a bit of thought.
Note that there was not a single case of “Wikidata got it wrong”, which surprised me a lot - I totally expected errors to happen. Unless you count the cases in Category 5. I mean, even English Wikipedia had errors! This was a pleasant surprise. Also, the genuine complicated cases are roughly as frequent as missing data, duplicates, and errors together. To be honest, that sounds like a pretty good result to me.
Also, the scraped data? Recall might be low, but the precision is pretty good: more than 98% of it is corroborated by Wikidata. Not all scraping jobs have such a high correctness.
In general, these results are comparable to a comparison of Wikidata with DBpedia and Freebase I did two years ago.
Oh, and what about Bill’s original question?
Turns out that Wikidata knows of a path between Alfred and Elizabeth II that is even shorter than the shortest 31 generations Bill found, as it takes only 30 generations.
This is Bill’s path:
- Alfred the Great
- Ælfthryth, Countess of Flanders
- Arnulf I, Count of Flanders
- Baldwin III, Count of Flanders
- Arnulf II, Count of Flanders
- Baldwin IV, Count of Flanders
- Judith of Flanders
- Henry IX, Duke of Bavaria
- Henry X, Duke of Bavaria
- Henry the Lion
- Henry V, Count Palatine of the Rhine
- Agnes of the Palatinate
- Louis II, Duke of Bavaria
- Louis IV, Holy Roman Emperor
- Albert I, Duke of Bavaria
- Joanna Sophia of Bavaria
- Albert II o _Germany
- Elizabeth of Austria
- Barbara Jagiellon
- Christine of Saxony
- Christine of Hesse
- Sophia of Holstein-Gottorp
- Adolphus Frederick I, Duke of Mecklenburg-Schwerin
- Adolphus Frederick II, Duke of Mecklenburg-Strelitz
- Duke Charles Louis Frederick of Mecklenburg
- Charlotte of Mecklenburg-Strelitz
- Prince Adolphus, Duke of Cambridge
- Princess Mary Adelaide of Cambridge
- Mary of Teck
- George VI
- Elizabeth II
And this is the path that I found using the Wikidata data:
- Alfred the Great
- Edward the Elder (surprisingly, it deviates right at the beginning)
- Eadgifu of Wessex
- Louis IV of France
- Matilda of France
- Gerberga of Burgundy
- Matilda of Swabia (this is a weak link in the chain, though, as there might possibly be two Matildas having been merged together. Ask your resident historian)
- Adalbert II, Count of Ballenstedt
- Otto, Count of Ballenstedt
- Albert the Bear
- Bernhard, Count of Anhalt
- Albert I, Duke of Saxony
- Albert II, Duke of Saxony
- Rudolf I, Duke of Saxe-Wittenberg
- Wenceslaus I, Duke of Saxe-Wittenberg
- Rudolf III, Duke of Saxe-Wittenberg
- Barbara of Saxe-Wittenberg (Barbara has no article in the English Wikipedia, but in German, Bulgarian, and Italian. Since the scraper only looks at English, they would have never found this path)
- Dorothea of Brandenburg
- Frederick I of Denmark
- Adolf, Duke of Holstein-Gottorp (husband to Christine of Hesse in Bill’s path)
- Sophia of Holstein-Gottorp (and here the two lineages merge again)
- Adolphus Frederick I, Duke of Mecklenburg-Schwerin
- Adolphus Frederick II, Duke of Mecklenburg-Strelitz
- Duke Charles Louis Frederick of Mecklenburg
- Charlotte of Mecklenburg-Strelitz
- Prince Adolphus, Duke of Cambridge
- Princess Mary Adelaide of Cambridge
- Mary of Teck
- George VI
- Elizabeth II
I hope that this is an interesting result for Bill coming out of this exercise.
I am super thankful to Bill for doing this work and describing it. It led to very interesting discussions and triggered insights into some shortcomings of Wikidata. I hope the above write-up is also helpful, particularly in providing some data regarding the quality of Wikidata, and I hope that it will lead to work in making Wikidata more and easier accessible to explorers like Bill.
Update: there has been a discussion of this post on Hacker News.
Double copy in gravity
When I was younger, I understood these theories much better. Today I read them like a fascinated, but a bit distant bystander.
But it is terribly interesting. What does turning physics into math mean? When we find a mathematical shortcut that works but we don't understand - is this real? What is the relation between mathematical formulas and reality? And will we finally understand gravity some day?
It was an interesting article, but I am not sure I understood it all. I guess, I'm getting old. Or just too specialized.
Zen and the Art of Motorcycle Maintenance
During my PhD, on the topic of ontology evaluation - figuring out what a good ontology is and what is not - I was running circles up and down trying to define what "good" means for an ontology (Benjamin Good, another researcher on that topic, had it easier, as he could call his metric "Good metric" and be done with it).
So while I was struggling with the definition in one of my academic essays, a kind anonymous reviewer (I think it was Aldo Gangemi) suggested I should read "Zen and the Art of Motorcycle Maintenance".
When I read the title of the suggested book, I first thought the reviewer was being mean or silly and suggesting a made-up book because I was so incoherent. It took me two days to actually check whether that book existed, as I wouldn't believe it.
It existed. And it really helped me, by allowing me to set boundaries of how far I can go in my own work, and that it is OK to have limitations, and that trying to solve EVERYTHING leads to madness.
(Thanks to Brandon Harris for triggering this memory)
Keynote at Web Conference 2021
Today, I have the honor to give a keynote at the WWW Confe... sorry, the Web Conference 2021 in Ljubljana (and in the whole world). It's the 30th Web Conference!
Join Jure Leskovec, Evelyne Viegas, Marko Grobelnik, Stan Matwin and myself!
I am going to talk about how Abstract Wikipedia and Wikifunctions aims to contribute to Knowledge Equity. Register here for free:
Update: the talk can now be watched on VideoLectures:
Building a Multilingual Wikipedia
Communications of the ACM published my paper on "Building a Multilingual Wikipedia", a short description of the Wikifunctions and Abstract Wikipedia project that we are currently working on at the Wikimedia Foundation.
Jochen Witte
Jochen Witte war ein Freund meiner Schulzeit. Ich habe viel von ihm gelernt, er konnte all diese praktischen Sachen zu denen ich nie einen Zugang hatte und von denen ich oft wünschte, ich könnte sie. Von ihm lernte ich, was eine gute Soundanlage braucht und warum Subwoofer groß sein müssen und was Subwoofer überhaupt sind. Zusammen schleppten wir schwere Boxen, um Unterstufendiscos und Abischerze und Vorträge zu ermöglichen. Von ihm lernte ich die Vorzüge des Gaffertapes kennen, und dass es nicht nur silbernes Klebeband ist. Er war der erste, der mir Mangas und Anime ein wenig näherbrachte, insbesondere hatte er eine Leidenschaft für Akira. Er ließ mich das erste Mal die elektronische Musik von Chris Hülsbeck und Jean-Michel Jarre hören. Er las ASM, ich las Power Play. Wir spielten eine zeitlang DSA miteinander. Er war der erste den ich kannte mit einem Pager. Er wirkte stets so als konnte er alles reparieren, und es war gut so jemanden zu kennen.
Gleichzeitig waren einige meiner Freunde und ich ihm gegenüber nicht immer freundlich, oh nein, im Gegenteil, manchmal war ich geradewegs grausam. Ich mache mich über seine Brille lustig oder sein Gewicht, und konnte Punkte damit sammeln, über ihn Witze zu machen. Ich wusste es war falsch. Wir waren ja schon die Außenseiter in der Klasse, und ich versuchte ihn zum Außenseiter der Außenseiter zu machen. Meine einzige Entschuldigung ist, dass wir Kinder waren, und ich noch nicht die Stärke hatte, besser zu sein. Ich lernte viel daraus, und wollte nie wieder so sein. Mit der Zeit verstand ich mich besser. Wo diese Grausamkeit herkam. Und das es nicht an Jochen lag, sondern in mir. Ich schäme mich für vieles was ich tat. Ich weiß nicht, ob ich mich jemals bei ihm entschuldigt habe.
Und dennoch glaube ich waren wir Freunde.
Nach der Schulzeit verloren wir uns aus den Augen. Er studierte Chemie in Esslingen, wir trafen uns hin und wieder im Movie Dick zur Sneak Preview. Er zog nach Staig im Alb-Donau-Kreis und fand sich als Goth wieder. Aber über die Jahre hinweg, gerieten wir hin und wieder in Kontakt.
Eine unserer gemeinsamen Erinnerungen war, wie wir zusammen zu einem Vortrag von Erich von Däniken fuhren. Es war mein Auto. Wir hatten einen Platten, und während er es zum Laufen brachte - wie gesagt, er konnte alles reparieren - fragte er mich, wann ich denn das letzte Mal nach dem Öl geschaut habe. Ich muss so belämmert reingeschaut haben, dass er nur noch lachen konnte. Die Antwort war "Nie", und er sah es in meinem Gesicht. Jedesmal wenn wir uns trafen, sprach er mich auf diesen Abend an.
Jochen half mir beim Umzug nach Karlsruhe. Das Gästebett passte nicht richtig zusammen. Er sagte er könnte es festziehen, aber ich würde es nie wieder auseinander bekommen. Es wird schwierig, damit umzuziehen. Ich sagte, das ist OK, ist ja nur ein billiges IKEA Gästebett Couch Dings. Ich habe nicht vor, damit umzuziehen, versicherte ich ihm.
Ich zog damit von Karlsruhe nach Berlin. Von Berlin nach Alameda. Innerhalb von Alameda. Von Alameda nach Berkeley. Es hat den Umzugshelfern jedesmal Kopfzerbrechen bereitet, genau wie Jochen versprochen hatte. Letzte Woche brach ein Stück ab. Ich sitze jetzt darauf und schreibe das hier. Nach fast einem Jahrzehnt sollte ich es wohl endlich austauschen.
Das letzte mal trafen wir uns ganz zufällig 2017 am Stuttgarter Bahnhof. Ich war überhaupt nur ein Mal im letzen halben Jahrzehnt wieder in Deutschland. Und da, am Bahnhof, traf ich ihn. Es war schön, Jochen wiederzusehen, und wir redeten als ob wir uns immer noch täglich sehen würden, wie zwanzig Jahre zuvor. Als ob das Abitur erst gestern war.
Diese Woche erfuhr ich von Michael, dass Jochen verstorben ist. Er starb nur wenige Monate nach unserem zufälligen Treffen, im April 2018. Er wurde nur vierzig Jahre alt.
Es tut mir leid.
Und noch viel mehr: Danke.
Ruhe in Frieden, Jochen Witte.
Der Name Zdenko
Heute sah ich dass der Artikel Zdenko - mein eigentlicher Name - auf der Englischen Wikipedia verändert wurde. Jemand hatte die Bedeutung des Namens von dem, was ich für richtig hielt (slawische Form von Sidonius) zu etwas was ich nie zuvor gehört habe (Koseform von Zdeslav) verändert, aber nicht die Quelle angepasst. Ich dachte, das wird eine schnelle Korrektur, habe aber dennoch in die Quelle geschaut - und, schau an, die Quelle sagte weder das eine noch das andere, sondern behauptete der Name stammt von dem slawischen Wort zidati, bauen, errichten.
Das führte mich zu einer zweitstündigen Odyssee durch verschiedene Quellen des 19. und 20. Jahrhunderts, wo ich Belege für alle drei Bedeutungen finden konnte - außerdem Quellen, die behaupteten, dass der Name von dem Slawischen Wort zdenac, Brunnen, abgeleitet ist, dass auch der Name Sidney von Sidonius stamme, und eine Hessische Quelle die vehement darüber schimpfte, dass doch Zdenko und Sidonius nichts miteinander zu tun haben (auch die Slowenische Wikipedia sagt, dass die Namen Zdenko und Sidonius zwar einen gemeinsamen Namenstag haben, aber nicht der gleiche Name sind). Dafür aber führt die gleiche Quelle aus, dass der im Osthessischen gebrauchte Name Denje wohl von Zdenka kommt (so nah an Denny!)
Denje gefällt mir als Name.
Kurzgesagt: wenn Du denkst, Etymologie sei kompliziert, sei gewarnt: Anthroponomastik ist deutlich schlimmer!
The name Zdenko
Today I saw that the Wikipedia article on Zdenko - my actual name - was edited, and the meaning of the name was changed from something I considered correct (slavic form of Sidonius) to something that I never heard of before (diminutive of Zdeslav), but the reference stayed intact, so I thought that'll be an easy revert. Just to do due process, I checked the given source - and funnily enough, it didn't say neither one nor the other, but gave an etymology from the slavic word zidati, to build, to create.
That lead me down a two hour rabbit hole through different sources crossing the 19th to 20th century, finding sources that claim the name is derived from the Slavic word zdenac, a well, or that Zdenko is cognate to Sidney, a Hessian source explaining that it is considered the root for the name Denje (so close to Denny!) (and saying it has nothing to do with Sidonius), and much more.
In short, if you think that etymology is messy, I tell you, anthroponymy is far worse!
Time on Mars
This is a fascinating and fun listen about the mars mission. Because a day on Mars takes 40 minutes longer than on Earth, the people working on that mission had to live on Mars time, as the Mars rovers work with solar panels. So they have watches showing Mars time. They invent new words in their language, speaking about sol instead of day, of yestersol, and they start themselves calling Martians. 11 minutes.
Katherine Maher to step down from Wikimedia Foundation
Today Katherine Maher announced that she is stepping down as the CEO of the Wikimedia Foundation in April.
Thank you for everything!
Boole and Voynich and Everest
Did you know?
George Boole - after whom the Boolean data type and Boolean logic was named - was the father of Ethel Lilian Voynich - who wrote The Gadfly.
Her husband was Wilfrid Voynich - after whom the Voynich manuscript was named.
Ethel's mother and George Boole's wife was Mary Everest Boole - a self-thought mathematician who wrote educational books about mathematics. Her life is of interest to feminists as an example of how women made careers in an academic system that did not welcome them.
Mary Everest Boole's uncle was Sir George Everest - after whom Mount Everest is named.
And her daughter Lucy Everest was the first he first woman Fellow of the Royal Institute of Chemistry.
Geoffrey Hinton, great-great-grandson of George and Mary Everest Boole, received the Turing Award for his work on deep learning.
Abraham Taherivand to step down from Wikimedia Deutschland
Today Abraham Taherivand announced that he is stepping down as the CEO of Wikimedia Deutschland at the end of the year.
Thank you for everything!
Twenty years
On this day, twenty years ago, on January 15, 2001, I started my third Website, Nodix, and I kept it up since then (unlike my previous two Websites, which are lost to history as Internet Archive didn't capture them yet, it seems). A few years later I renamed it to Simia.
Here is the first entry: Willkommen auf der Webseite von Denny Vrandecic!
My Website never became particularly popular, although I was meticulously keeping track of how many hits I got and all of this. It was always a fun side project for which I had sometimes more and sometimes less time.
The funniest thing is that it was - and that was completely incidental - exactly the same day that another Website was started, which I, over the years, spent much more time on: Wikipedia.
Wikipedia changed my life, not only once, but many times.
It is how I met Kamara.
It is how I met a lot of other very smart people, too. It became part of my research work and my PhD thesis. It became the motivation for many of the projects I have started, be it Semantic MediaWiki, Wikidata, or Abstract Wikipedia. It is the reason for my career trajectory over the last fifteen years. It is hard to overstate how influential Wikipedia has been on my life.
It is hard to overstate how important Wikipedia has become for modern AI and for the Web of today. For smaller language communities. For many, many people looking for knowledge. And for the many people who realised that they can contribute to it too.
Thanks to the Wikipedia community, thanks to this marvellous project, and happy anniversary and many returns to Wikipedia!
Happy New Year 2021!
2020 was a challenging year, particularly due to the pandemic. Some things were very different, some things were dangerous, and the pandemic exposed the fault lines in many societies in a most tragic way around the world.
Let's hope that 2021 will be better in that respect, that we will have learned from how the events unfolded.
But I'm also amazed by how fast the vaccine was developed and made available to tens of millions.
I think there's some chance that the summer of '21 will become one to sing about for a generation.
Happy New Year 2021!
Keynote at SMWCon Fall 2020
I have the honor of being the invited keynote for the SMWCon Fall 2020. I am going to talk "From Semantic MediaWiki to Abstract Wikipedia", discussing fifteen years of Semantic MediaWiki, how it all started, where we are now - crossing Freebase, DBpedia, Wikidata - and now leading to Wikifunctions and Abstract Wikipedia. But, more importantly, how Semantic MediaWiki, over all these years, still holds up and what its unique value is.
Page about the talk on the official conference site: https://www.semantic-mediawiki.org/wiki/SMWCon_Fall_2020/Keynote:_From_Semantic_Wikipedia_to_Abstract_Wikipedia
Site went down
The site went down, again. First time was in July, when Apache had issues, this time it's due to MySQL acting up and frying the database. I found a snapshot from July 2019, and am trying to recreate the entries from in between (thanks, Wayback Machine!)
Until then, at least the site is back up, even though they might be some losses in the content.
P.S.: it should all be back up. If something is missing, please email me.
Wikidata crossed Q100000000
Wikidata crossed Q100000000 (and, in fact, skipped it and got Q100000001 instead).
Here's a small post by Lydia Pintscher and me: https://diff.wikimedia.org/2020/10/06/wikidata-reaches-q100000000/
Mulan
I was surprised when Disney made the decision to sell Mulan on Disney+. So if you wanted to watch Mulan, you not only have to buy it, so far so good, but you have to join their subscription service first. The price for Mulan is $30 in the US, additionally to the monthly fee of streaming, $7. So the $30 don't buy you Mulan, but allow you to watch it if you keep up your subscription.
Additionally, on December 4 the movie becomes free for everyone with a Disney+ subscription.
I thought, that's a weird pricing model. Who'd pay that much money for streaming the movie a few weeks earlier? I know, it will be very long weeks due to the world being so 2020, but still. Money is tight for many people. Also, the movie had very mixed reviews and a number of controversies attached to it.
According to the linked report, Disney really knows what they're doing. 30% of subscribers bought the early streaming privilege! Disney made hundreds of millions in extra profit within three first few days (money they really will be thankful for right now given their business with the cruise ships and theme parks and movies this year).
The most interesting part is how this will affect the movie industry. Compare to Tenet - which was reviewed much better and which was the hope to revive the moribund US cinema industry, but made less than $30M - which also needs to be shared with the theaters and had much more distribution costs. Disney keeps a much larger share of the $30 for Mulan than Tenet makes for its production company.
The lesson from Mulan and Trolls 2, which also did much better than I would ever have predicted, for the production companies experimenting with novel pricing models, could be disastrous for theaters.
I think we're going to see even more experimentation with pricing models. If the new Bond movie and/or the new Marvel movie should be pulled from cinemas, this might also be the end of cinemas as we know them.
I don't know how the industry will change, but the swing is from AMC to Netflix, with the producers being caught in between. The pandemic massively accelerated this transition, as it did so many others.
Gödel's naturalization interview
When Gödel went to his naturalization interview, his good friend Einstein accompanied him as a witness. On the way, Gödel told Einstein about a gap in the US constitution that would allow the country to be turned into a dictatorship. Einstein told him to not mention it during the interview.
The judge they came to was the same judge who already naturalized Einstein. The interview went well until the judge asked whether Gödel thinks that the US could face the same fate and slip into a dictatorship, as Germany and Austria did. Einstein became alarmed, but Gödel started discussing the issue. The judge noticed, changed the topic quickly, and the process came to the desired outcome.
I wonder what that was, that Gödel found, but that's lost to history.
Gödel and Leibniz
Gödel in his later age became obsessed with the idea that Leibniz had written a much more detailed version of the Characteristica Universalis, and that this version was intentionally censored and hidden by a conspiracy. Leibniz had discovered what he had hunted for his whole life, a way to calculate truth and end all disagreements.
I'm surprised that it was Gödel in particular to obsess with this idea, because I'd think that someone with Leibniz' smarts would have benefitted tremendously from Gödel's proofs, and it might have been a helpful antidote to his own obsession with making truth a question of mathematics.
And wouldn't it seem likely to Gödel that even if there were such a Characteristics Universalis by Leibniz, that, if no one else before him, he, Gödel himself would have been the one to find the fatal bug in it?
Starting Abstract Wikipedia
I am very happy about the Board of the Wikimedia Foundation having approved the proposal for the multilingual Wikipedia aka Abstract Wikipedia aka Wikilambda aka we'll need to find a name for it.
In order to make that project a reality, I will as of next week join the Foundation. We will be starting with a small, exploratory team, which will allow us to have plenty of time to continue to socialize and discuss and refine the idea. Being able to work on this full time and with a team should allow us to make significant progress. I am very excited about that.
I am sad to leave Google. It was a great time, and I learned a lot about running *large* projects, and I met so many brilliant people, and I ... seriously, it was a great six and a half years, and I will very much miss it.
There is so much more I want to write but right now I am just super happy and super excited. Thanks everyone!
Lexical masks in JSON
We have released lexical masks as ShEx files before, schemata for lexicographic forms that can be used to validate whether the data is complete.
We saw that it was quite challenging to turn these ShEx files into forms for entering the data, such as Lucas Werkmeister’s Lexeme Forms. So we adapted our approach slightly to publish JSON files that keep the structures in an easier to parse and understand format, and to also provide a script that translates these JSON files into ShEx Entity Schemas.
Furthermore, we published more masks for more languages and parts of speech than before.
Full documentation can be found on wiki: https://www.wikidata.org/wiki/Wikidata:Lexical_Masks#Paper
Background can be found in the paper: https://www.aclweb.org/anthology/2020.lrec-1.372/
Thanks Bruno, Saran, and Daniel for your great work!
Major bill for US National Parks passed
Good news: the US Senate has passed a bipartisan large Public Lands Bill, which will provide billions right now and continued sustained funding for National Parks.
There a number of interesting and good parts about this, besides the obvious that National Parks are being funded better and predictably:
- the main reason why this passed and was made was that the Evangelical movement in the US is increasingly reckoning that Pro-Life also means Pro-Environment, and this really helped with making this bill a reality. This is major as it could set the US on a path to become a more sane nation regarding environmental policies. If this could also extend to global warming, that would be wonderful, but let's for now be thankful for any momentum in this direction.
- the sustained funding comes from oil and gas operations, which has a certain satisfying irony to it. I expect this part to backfire a bit somehow, but I don't know how yet.
- Even though this is a political move by Republicans in order to safe two of their Senators this fall, many Democrats supported it because the substance of the bill is good. Let's build on this momentum of bipartisanship.
- This has nothing to do with the pandemic, for once, but was in work for a long time. So all of the reasons above are true even without the pandemic.
Black lives matter
Fun in coding
This article really was grinding my gears today. Coding is not fun, it claims, and everyone who says otherwise is lying for evil reasons, like luring more people into programming.
Programming requires almost superhuman capabilities, it says. And other jobs who do that, such as brain surgery, would never be described as fun, so it is wrong to talk like this about coding.
That is all nonsense. The article not only misses the point, but it denies many people their experience. What's the goal? Tell those "pretty uncommon" people that they are not only different than other people, but that their experience is plain wrong, that when they say they are having fun doing this, they are lying to others, to the normal people, for nefarious reasons? To "lure people to the field" to "keep wages under control"?
I feel offended by this article.
There are many highly complex jobs that some people have fun doing some of the time. Think of writing a novel. Painting. Playing music. Cooking. Raising a child. Teaching. And many more.
To put it straight: coding can be fun. I have enjoyed hours and days of coding since I was a kid. I will not allow anyone to deny me that experience I had, and I was not a kid with nefarious plans like getting others into coding to make tech billionaires even richer. And many people I know have expressed fun with coding.
Also: coding does not *have* to be fun. Coding can be terribly boring, or difficult, or frustrating, or tedious, or bordering on painful. And there are people who never have fun coding, and yet are excellent coders. Or good enough to get paid and have an income. There are coders who code to pay for their rent and bills. There is nothing wrong with that either. It is a decent job. And many people I know have expressed not having fun with coding.
Having fun coding doesn't mean you are a good coder. Not having fun coding doesn't mean you are not a good coder. Being a good coder doesn't mean you have to have fun doing it. Being a bad coder doesn't mean you won't have fun doing it. It's the same for singing, dancing, writing, playing the trombone.
Also, professional coding today is rarely the kind of activity portrayed in this article, a solitary activity where you type code in green letters into a monotype font on black background, without having to answer to anyone, your code not being reviewed and scrutinized before it goes into production. For decades, coding has been a highly social activity, that requires negotiation and discussion and social skills. I don't know if I know many senior coders who spend the majority of their work time actually coding. And it's in that level of activity where ethical decisions are made. Ethical decisions are rarely happening at the moment the coder writes an if statement, or declares a variable. These decisions are made long in advance, documented in design docs and task descriptions, reviewed by a group of people.
So this article, although it has its heart in the right position, trying to point out that coding, like any engineering, also has many relevant ethical questions, goes about it entirely wrongly, and manages to offend me, and probably a lot of other people.
Sorry for my Saturday morning rant.
OK
I often hear "don't go for the mediocre, go for the best!", or "I am the best, * the rest" and similar slogans. But striving for the best, for perfection, for excellence, is tiring in the best of times, never mind, forgive the cliché, in these unprecedented times.
Our brains are not wired for the best, we are not optimisers. We are naturally 'satisficers', we have evolved for the good-enough. For this insight, Herbert Simon received a Nobel prize, the only Turing Award winner to ever get one.
And yes, there are exceptional situations where only the best is good enough. But if good enough was good enough for a Turing-Award winning Nobel laureate, it is probably for most of us too.
It is OK to strive for OK. OK can sometimes be hard enough, to be honest.
May is mental health awareness month. Be kind to each other. And, I know it is even harder, be kind to yourself.
Here is OK in different ways. I hope it is OK.
Oké ఓకే ਓਕੇ オーケー ओके 👌 ওকে או. קיי. Окей أوكي Օքեյ O.K.
Tim Bray leaving Amazon in protest
Tim Bray, co-author of XML, stepped down as Amazon VP over their handling of whistleblowers on May 1st. His post on this decision is worth reading.
If life was one day
If the evolution of animals was one day... (600 million years)
- From 1am to 4am, most of the modern types of animals have evolved (Cambrian explosion)
- Animals get on land a bit at 3am. Early risers! It takes them until 7am to actually breath air.
- Around noon, first octopuses show up.
- Dinosaurs arrive at 3pm, and stick around until quarter to ten.
- Humans and chimpanzees split off about fifteen minutes ago, modern humans and Neanderthals lived in the last minute, and the pyramids were built around 23:59:59.2.
In that world, if that was a Sunday:
- Saturday would have started with the introduction of sexual reproduction
- Friday would have started by introducing the nucleus to the cell
- Thursday recovering from Wednesday's catastrophe
- Wednesday photosynthesis started, and lead to a lot of oxygen which killed a lot of beings just before midnight
- Tuesday bacteria show up
- Monday first forms of life show up
- Sunday morning, planet Earth forms, pretty much at the same time as the Sun.
- Our galaxy, the Milky Way, is about a week older
- The Universe is about another week older - about 22 days.
There are several things that surprised me here.
- That dinosaurs were around for such an incredibly long time. Dinosaurs were around for seven hours, and humans for a minute.
- That life started so quickly after Earth was formed, but then took so long to get to animals.
- That the Earth and the Sun started basically at the same time.
Addendum April 27: Álvaro Ortiz, a graphic designer from Madrid, turned this text into an infographic.
Architecture for a multilingual Wikipedia
I published a paper today:
"Architecture for a multilingual Wikipedia"
I have been working on this for more than half a decade, and I am very happy to have it finally published. The paper is a working paper and comments are very welcome.
Abstract:
Wikipedia’s vision is a world in which everyone can share in the sum of all knowledge. In its first two decades, this vision has been very unevenly achieved. One of the largest hindrances is the sheer number of languages Wikipedia needs to cover in order to achieve that goal. We argue that we need anew approach to tackle this problem more effectively, a multilingual Wikipedia where content can be shared between language editions. This paper proposes an architecture for a system that fulfills this goal. It separates the goal in two parts: creating and maintaining content in an abstract notation within a project called Abstract Wikipedia, and creating an infrastructure called Wikilambda that can translate this notation to natural language. Both parts are fully owned and maintained by the community, as is the integration of the results in the existing Wikipedia editions. This architecture will make more encyclopedic content available to more people in their own language, and at the same time allow more people to contribute knowledge and reach more people with their contributions, no matter what their respective language backgrounds. Additionally, Wikilambda will unlock a new type of knowledge asset people can share in through the Wikimedia projects, functions, which will vastly expand what people can do with knowledge from Wikimedia, and provide a new venue to collaborate and to engage the creativity of contributors from all around the world. These two projects will considerably expand the capabilities of the Wikimedia platform to enable every single human being to freely share in the sum of all knowledge.
Stanford seminar on Knowledge Graphs
My friend Vinay Chaudhri is organising a seminar on Knowledge Graphs with Naren Chittar and Michael Genesereth this semester at Stanford.
I have the honour to present in it as the opening guest lecturer, introducing what Knowledge Graphs are and what are good for.
Due to the current COVID situation, the seminar was turned virtual, and opened to everyone to attend to.
Other speakers during the semester include Juan Sequeda, Marie-Laure Mugnier, Héctor Pérez Urbina, Michael Uschold, Jure Leskovec, Luna Dong, Mark Musen, and many others.
Change is in the air
I'll be prophetic: the current pandemic will shine a bright light on the different social and political systems in the different countries. I expect to see noticeable differences in how disruptive the handling of the situation by the government is, how many issues will be caused by panic, and what effect freely available health care has. The US has always been on the very end of admiring the self sustained individual, and China has been on the other end of admiring the community and its power, and Europe is somewhere in the middle (I am grossly oversimplifying).
This pandemic will blow over in a year or two, it will sweep right through the US election, and the news about it might shape what we deem viable and possible in ways beyond the immediately obvious. The possible scenarios range all the way from high tech surveillance states to a much wider access to social goods such as health and education, and whatever it is, the pandemic might be a catalyst towards that.
Wired: "Wikipedia is the last best place on the Internet"
WIRED published a beautiful ode to Wikipedia, painting the history of the movement with broad strokes, aiming to capture its impact and ambition with beautiful prose. It is a long piece, but I found the writing exciting.
Here's my favorite paragraph:
"Pedantry this powerful is itself a kind of engine, and it is fueled by an enthusiasm that verges on love. Many early critiques of computer-assisted reference works feared a vital human quality would be stripped out in favor of bland fact-speak. That 1974 article in The Atlantic presaged this concern well: “Accuracy, of course, can better be won by a committee armed with computers than by a single intelligence. But while accuracy binds the trust between reader and contributor, eccentricity and elegance and surprise are the singular qualities that make learning an inviting transaction. And they are not qualities we associate with committees.” Yet Wikipedia has eccentricity, elegance, and surprise in abundance, especially in those moments when enthusiasm becomes excess and detail is rendered so finely (and pointlessly) that it becomes beautiful."
They also interviewed me and others for the piece, but the focus of the article is really on what the Wikipedia communities have achieved in our first two decades.
Two corrections: - I cannot be blamed for Wikidata alone, I blame Markus Krötzsch as well - the article says that half of the 40 million entries in Wikidata have been created by humans. I don't know if that is correct - what I said is that half of the edits are made by human contributors
Normbrunnenflasche
It's a pity there's no English Wikipedia article about this marvellous thing that exemplifies Germany so beautifully and quintessentially: the Normbrunnenflasche.
I was wondering the other day why in Germany sparkling water is being sold in 0.7l bottles and not in 1l or 2l or whatever, like in the US (when it's sold here at all, but that's another story).
Germany had a lot of small local producers and companies. To counter the advantages of the Coca Cola Company pressing in the German market, in 1969 a conference of representatives of the local companies decided to introduce a bottle design they all would use. This decision followed a half year competition and discussion on what this bottle should look like.
Every company would use the same bottle for sparkling water and other carbonated drinks, and so no matter which one you bought, the empty bottle would afterwards be routed to the closest participating company, not back home, therefore reducing transport costs and increasing competitiveness against Coca Cola.
The bottle is full of smart features. The 0.7l were chosen to ensure that the drink remained carbonated until the last sip, because larger bottles would last longer and thus gradually loose carbonization.
The form and the little pearls outside were chosen for improved grip, but also to symbolize the sparkles of the carbonization.
The metal screw cap was the real innovation there, useful for drinks that could increase pressure due to the carbonization.
And finally two slightly thicker bands along the lower half of the bottle that would, while being rerouted for another usage, slowly get more opaque due to mechanical pressure, thus indicating how well used the individual bottle was, so they could be taken out of service in time before breaking at the customer.
The bottles were reused an average of fifty times, their boxes an average of hundred times. More than five billion of them have been brought into circulation in the fifty years since their adoption, for an estimated quarter of a trillion fillings.
A new decade?
The job of an ontologist is to define concepts. And since I see some posts commenting on whether a decade is closing and a new decade is starting tonight, here's my private, but entirely official position.
A decade is a consecutive timespan of ten years, and therefore at every given point a new decade starts and one ends. But that's a trivial answer to the question and not very useful.
There are two ways to count calendar decades, and both are arbitrary and rely on retconning, I mean, they really on redefining the past. Therefore there is no right or wrong.
Method one is by using the proleptic Gregorian calendar, and starting with the year 1 and ending with the year 10, and calling that the first decade. If you keep counting, then the twohundredandthird decade will start on January 1st 2021, and we are currently firmly in the twohundredandsecond decade, and will stay there for another year.
Method two is based on the fact that for a millennium now and for many years to come there's a time period that conveniently lasts a decade where the years start with the same three digits. That is, the years starting with 202, which are called the 2020s, the ones with 199 which are called the 1990s (or sometimes just the 90s), etc. For centuries now we can find support for these kind of decades being widely used. According to this method, tonight marks a new decade.
So whether you are celebrating a new year tonight or not (because there are many other calendars out there too), or a new decade or not, I wish you wonderful 2020s!
SWAT4HCLS trip report
This week saw the 12th SWAT4HCLS event in Edinburgh, Scotland. It started with a day of tutorials and workshops on Monday, December 10th, on topics such as SPARQL, querying, ontology matching, and using Wikibase and Wikidata.
Conference presentations went on for two days, Tuesday and Wednesday. This included four keynotes, including mine on Wikidata, and how to move beyond Wikidata (presenting the ideas from my Abstract Wikipedia papers). The other three keynotes (as well as a number of the paper presentation) were all centered on the FAIR concept which I already saw being so prominent at the eScience conference earlier this year. FAIR as in Findable, Accessible, Interoperable, and Reusable publication of data. I am very happy to see these ideas spread out so prominently!
Birgitta König-Ries talked about how to use semantic technologies to manage FAIR data. Dov Greenbaum talked about how licenses interplay with data and what it means for FAIR data - personally, my personal favorite of the keynotes, because of my morbid fascination regarding licenses and intellectual property rights pertaining to data and knowledge. He actually confirmed my understanding of the area - that you can’t really use copyright for data, and thus the application of CC-BY or similar licenses to data would stand on shaky grounds in a court. The last keynote was by Helen Parkinson, who gave a great talk on the issues that come up when building vocabularies, including issues around over-ontologizing (and the siren call of just keeping on modeling) and others. She put the issues in parallel to the travels of Odysseus, which was delightful.
The conference talks and posters were really on spot on the topic of the conference: using semantic web technologies in the life sciences, health care, and related fields. It was a very satisfying experience to see so many applications of the technologies that Semantic Web researchers and developers have been creating over the years. My personal favorite was MetaStanza, web components that visualize SPARQL results in many different ways (a much needed update to SPARK, that Andreas Harth and I had developed almost a decade ago).
On Thursday, the conference closed with a Hackathon day, which I couldn’t attend unfortunately.
Thanks to the organizers for the event, and thanks again for the invitation to beautiful Edinburgh!
Other trip reports (send me more if you have them):
Frozen II in Korea
This is a fascinating story, that just keeps getting better (and Hollywood Reporter is only scratching the surface here, unfortunately): an NGO in South Korea is suing Disney for "monopolizing" the movie screens of the country, because Frozen II is shown on 88% of all screens.
Now, South Korea has a rich and diverse number of movie theatres - they have the large cineplexes in big cities, but in the less populated areas they have many small theatres, often with a small number of screens (I reckon it is similar to the villages in Croatia, where there was only a single screen in the theater, and most movies were shown only once, and there were only one or two screenings per day, and not on every day). The theatres are often independent, so there is no central planning about which movies are being shown (and today, it rarely matters today how many copies of a movie are being made, as many projectors are digital and thus unlimited copies can be created on the fly - instead of waiting for the one copy to travel from one town to the next, which was the case in my childhood).
So how would you ensure that these independent movies don't show a movie too often? By having a centralized way that ensures that not too many screens show the same movie? (Preferably on the Blockchain, using an auction system?) Good luck with that, and allowing the local theatres to adapt their screenings to their audiences.
But as said, it gets better: the 88% number is being arrived at by counting how many of the screens in the country showed Frozen II on a given day. It doesn't mean that that screen was used solely for Frozen II! If the screen was used at noon for a showing of Frozen II, and at 10pm for a Korean horror movie, that screen counts for both. Which makes the percentage a pretty useless number if you want to show monopolistic dominance (also, because the numbers add up to far more than 100%). Again, remember that in small towns there is often a small number of screens, and they have to show several different movies on the same screen. If the ideas of the lawsuit would be enacted, you would need to keep off Frozen II from a certain number of screens! Which basically makes it impossible to allow kids and teens in less populated areas to participate in event movie-going such as Frozen II and trying to avoid spoilers in Social Media afterwards.
Now, if you look how many screenings, instead of screens, were occupied by Frozen II, the number drops down to 46% - which is still impressive, but far less dominant and monopolistic than the 88% cited above (and in fact below the 50% the Korean law requires to establish dominance).
And even more impressive: in the end it is up to the audience. And even though 'only' 46% of the screenings were on Frozen II, every single day since its release between 60% and 85% of all revenue was going to Frozen II. So one could argue that the theatres were actually underserving the audience (but then again, that's not how it really works, because screenings are usually in rooms with hundred or more seats, and they can be very differently filled - and showing a blockbuster three times with almost full capacity, and showing a less popular movie once with only a dozen or so tickets sold might still have served the local community better than only running the block buster).
I bet the NGO's goal is just to raise awareness about the dominance of the American entertainment industry, and for that, hey, it's certainly worth a shot! But would they really want to go back to a system where small local cinemas would not be able to show blockbusters for a long time, involving a complicated centralized planning component?
(Also, I wish there was a way to sign up for updates on a story, like this lawsuit. Let me know if anyone knows of such a system!)
Machine Learning and Metrology
There are many, many papers in machine learning these days. And this paper, taking a step back, and thinking about how researchers measure their results and how good a specific type of benchmarks even can be - crowdsourced golden sets. It brings a convincing example based on word similarity, using terminology and concepts from metrology, to show how many results that have been reported are actually not supported by the golden set, because the resolution of the golden set is actually insufficient. So there might be no improvement at all, and that new architecture might just be noise.
I think this paper is really worth the time of people in the research field. Written by Chris Welty, Lora Aroyo, and Praveen Paritosh.
The story of the Swedish calendar
Most of us are mostly aware how the calendar works. There’s twelve months in a year, each month has 30 or 31 days, and then there’s February, which usually has 28 days and sometimes, in what is called a leap year, 29. In general, years divisible by four are leap years.
This calendar was introduced by no one else then Julius Caesar, before he became busy conquering the known world and becoming the Emperor of Rome. Before that he used to have the job title “supreme bridge builder” - the bridge connecting the human world with the world of the gods. One of the responsibilities of this role was to decide how many days to add to the end of the calendar year, because the Romans noticed that their calendar was getting misaligned with the seasons, because it was simply a bit too short. So, for every year, the supreme bridge builder had to decide how many days to add to the calendar.
Since we are talking about the Roman Republic, this was unsurprisingly misused for political gain. If the supreme bridge builder liked the people in power, he might have granted a few extra weeks. If not, no extra days. Instead of ensuring that the calendar and the seasons aligned, the calendar got even more out of whack.
Julius Caesar spearheaded a reform of the calendar, and instead of letting the supreme bridge builder decide how many days to add, the reform devised rules founded in observation and mathematical rules - leading to the calendar we still have today: twelve months each year, each with 30 or 31 days, besides February, which had 28, but every four years would have 29. This is what we today call the Julian calendar. This calendar was not perfect, but pretty good.
Over the following centuries, the role of the supreme bridge builder - or, in latin, Pontifex Maximus - transferred from the Emperor of Rome to the Bishop of Rome, the Pope. And with continuing observations over centuries it was noticed that the calendar was again getting out of sync with the seasons. So it was the Pope - Gregory XIII, later called The Great - who, in his role as Pontifex Maximus, decided that the calendar should be fixed once again. The committee he set up to work on that came up with fabulous improvements, which would guarantee to keep the calendar in sync for a much longer time frame. In addition to the rules established by the Julian calendar, every hundred years we would drop a leap year. But every four hundred years, we would skip dropping the leap year (as we did in 2000, which not many people noticed). And in 1582, this calendar - called the Gregorian calendar - was introduced.
Imagine leading a committee that comes up with rules on what the whole world would need to do once every four hundred years - and mostly having these rules implemented. How would you lead and design such a committee? I find this idea mind-blowing.
Since the time of Caesar until 1582, about fifteen centuries have passed. And in this time, the calendar was getting slightly out of sync - by one day every century, skipping every fourth. In order to deal with that shift, they decided that ten calendar days need to be skipped. Following the 4th of October 1582 was the 15th of October 1582. In 1582, there was no 5th or 14th of October, nor any of the days in between, in the countries that had the Gregorian calendar adopted.
This lead to plenty of legal discussions, mostly about monthly rents and wages: is this still a full month, or should the rent or wage be paid prorated to the number of days? Should annual rents, interests, and taxes be prorated by these ten days, or not? What day of the week should the 15th of October be?
The Gregorian calendar was a marked improvement over the Julian calendar with regards to keeping the seasons in sync with the calendar. So one might think its adoption should be a no-brainer. But there was a slight complication: politics.
Now imagine that today the Pope gets out on his balcony, and declares that, starting in five years, January to November all have 30 days, and December has 35 or 36 days. How would the world react? Would they ponder the merits of the proposal, would they laugh, would they simply adopt it? Would a country such as Italy have a different public discourse about this topic than a country such as China?
In 1582, the situation was similarly difficult. Instead of pondering the benefits of the proposal, the source of the proposal and the relation to that source became the main deciding factor. Instead of adopting the idea because it is a good idea, the idea was adopted - or not - because the Pope of the Catholic Church declared it. The Papal state, the Spanish and French Kingdoms, were first to adopt it.
Queen Elizabeth wanted to adopt it in England, but the Anglican bishops were fiercely opposed to it because it was suggested by the Pope. Other Protestant and the Orthodox countries simply ignored it for centuries. And thus there was a 5th of October 1582 in England, but not in France, and that lead to a number of confusions over the following centuries.
Ever wondered why the October Revolution started November 7? There we go. There is even a story that Napoleon won an important battle (either the Battle of Austerlitz or the Battle of Ulm) because the Russian and Austrian forces coordinated badly as the Austrians were using the Gregorian and the Russians the Julian calendar. The story is false, but it makes for a great story.
Today, the International Day of the Book is on April 23 - the death date of both Miguel de Cervantes and William Shakespeare in 1616, the two giants of literature in their respective languages - with the amusing side-effect that they actually died about two weeks apart, even though they died on the same calendar day, but in different calendars.
It wasn’t until 1923 that for most purposes all countries had deprecated the Julian calendar, and for religious purposes some still follow it - which is why the Orthodox and the Amish celebrate Christmas on January 6. Starting 2101, that should shift by another day - and I would be very curious to see whether it will, or whether by then January 6th has solidified as the Christmas date.
Possibly the most confusing story about adopting the Gregorian calendar comes from Sweden. Like most protestant countries, Sweden did not initially adopt the Gregorian calendar, and was sticking with the Julian calendar, until in 1699 they decided to switch.
Now, the idea of skipping eleven or twelve days in one go did not sound appealing - remember all the chaos that occurred in the other countries for dropping these days. So in Sweden they decided that instead of dropping the days all at once, they would drop them one by one, by skipping the leap years from 1700 until 1740, when the two calendars would finally catch up.
In 1700, February 29 was skipped in Sweden. Which didn’t bring them any closer to Gregorian countries such as Spain, because they skipped the leap year in 1700 anyway. But it brought them out of alignment with Russia - by one day.
A war with Russia started (not about the calendar, but just a week before the calendars went out of sync, incidentally), and due to the war Sweden forgot to skip the leap days in 1704 and 1708 (they had other things on their mind). And as this was embarrassing, in 1711, King Charles XII of Sweden declared to abandon the plan, and added one extra day the following year to realign it back to Russia. And because 1712 was a leap year anyway, in Sweden there was not only a February 29, but also a February 30, 1712. The only legal February 30 in history so far.
It needed not only for Charles XII to die, but also for his sister (who succeeded him) and her husband (who succeeded her) in 1751, before Sweden could move beyond that embarrassing episode, and in 1752 Sweden switched from the Julian to the Gregorian calendar, by cutting February short and ending it after February 17, following that by March 1.
Somewhere on my To-Do list, I have the wish to write a book on Wikidata. How it came to be, how it works, what it means, the complications we encountered, and the ones we missed, etc. One section in this book is planned to be about calendar models. This is an early, self-contained draft of part of that section. Feedback and corrections are very welcome.
Erdös number, update
I just made an update to a post from 2006, because I learned that my Erdös number has went down from 4 to 3. I guess that's pretty much it - it is not likely I'll ever become a 2.
The Fourth Scream
Janie loved her research. It was at the intersection of so many interesting areas - genetics, linguistics, neuroscience. And the best thing about it - she could work the whole day with these adorable vervet monkeys.
One more time, she showed the video of the flying eagle to Kassandra. The MRI helmet on Kassandra’s little head measured the neuron activation, highlighting the same region on her computer screen as the other times, the same region as with the other monkeys. Kassandra let out the scream that Janie was able to understand herself by now, the scream meaning “Eagle!”, and the other monkeys behind the bars in the far end of the room, in a cage large as half the room, ran to cover in the bushes and small caves, if they were close enough. As they did every time.
That MRI helmet was a masterpiece. She could measure the activation of the neurons in unprecedented high resolution. And not only that, she could even send inferencing waves back, stimulating very fine grained regions in the monkey’s brain. The stimulation wasn’t very fast, but it was a modern miracle.
She slipped a raspberry to Kassandra, and Kassandra quickly snatched it and stuffed it in her mouth. The monkeys came from different populations from all over Southern and Eastern Africa, and yet they all understood the same three screams. Even when the baby monkeys were raised by mute parents, the baby monkeys understood the same three screams. One scream was to warn them from leopards, one scream was to warn them from snakes, and the third scream was to warn them from eagles. The screams were universally understood by everyone across the globe - by every vervet monkey, that is. A language encoded in the DNA of the species.
She called up the aggregated areas from the scream from her last few experiments. In the last five years, she was able to trace back the proteins that were responsible for the growth of these four areas, and thus the DNA encoding these calls. She could prove that these three different screams, the three different words of Vervetian, were all encoded in DNA. That was very different from human language, where every word is learned, arbitrary, and none of the words were encoded in our DNA. Some researchers believed that other parts of our language were encoded in our DNA: deep grammatical patterns, the ability to merge chunks into hierarchies of meaning when parsing sentences, or the categorical difference between hearing the syllable ba and the syllable ga. But she was the first one to provably connect three different concrete genes with three different words that an animal produces and understands.
She told the software to create an overlapping picture of the three different brain areas activated by the three screams. It was a three dimensional picture that she could turn, zoom, and slice freely, in real time. The strands of DNA were highlighted at the bottom of the screen, in the same colors as the three different areas in the brain. One gene, then a break, then the other two genes she had identified. Leopard, snake, eagle.
She started to turn the visualization of the brain areas, as Kassandra started squealing in pain. Her hand was stuck between the cage bars and the plate with raspberries. The little thief was trying to sneak out a raspberry or two! Janie laughed, and helped the monkey get the hand unstuck. Kassandra yanked it back into the cage, looked at Janie accusingly, knowing that the pain was Janie’s fault for not giving her enough raspberries. Janie snickered, took out another raspberry and gave it to the monkey. She snatched it out of Janie’s hand, without stopping the accusing stare, and Janie then put the plate to the other side of the table, in safe distance and out of sight of Kassandra.
She looked back at the screen. When Kassandra cried out, her hand had twitched, and turned the visualization to a weird angle. She just wanted to turn it back to a more common view, when she suddenly stopped.
From this angle, she could see the three different areas, connecting together with the audiovisual cortex at a common point, like the leaves of a clover. But that was just it. It really looked like three leaves of a four-leaf clover. The area where the fourth leaf would be - it looked a lot like the areas where the other three leaves were.
She zoomed into the audiovisual cortex. She marked the neurons that triggered each of the three leaves. And then she looked at the fourth leaf. The connection to the cortex was similar. A bit different, but similar enough. She was able to identify what probably are the trigger-neurons, just like she was able to find them for the other three areas.
She targeted the MRI helmet on the neurons connected to the eagle trigger neurons, and with a click she sent a stimulus. Kassandra looked up, a bit confused. Janie looked at the neurons, how they triggered, unrolled the activation patterns, and saw how the signal was suppressed. She reprogrammed the MRI helmet, refined the neurons to be stimulated, and sent off another stimulus.
Kassandra yanked her head up, looking around, surprised. She looked at her screen, but it showed nothing as well. She walked nervously around inside the little cage, looking worriedly to the ceiling of the lab, confused. Janie again analyzed the activation patterns, and saw how it almost went through. There seemed to be a single last gatekeeper to pass. She reprogrammed the stimulator again. Third time's the charm, they say. She just remembered a former boyfriend, who was going on and on about this proverb. How no one knew how old it was, where it began, and how many different cultures all over the world associate trying something three times with eventual success, or an eventual curse. How some people believed you need to call the devil's name three times to —
Kassandra screamed out the same scream as before, the scream saying “Eagle!”. The MRI helmet had sent the stimulus, and it worked. The other monkeys jumped for cover. Kassandra raised her own arms above her head, peeking through her fingers to find the eagle she had just sensed.
Janie was more than excited! This alone will make a great paper. She could get the monkeys to scream out one of the three words of their language by a simple stimulation of particular neurons! Sure, she expected this to work - why wouldn’t it? But the actual scream, the confirmation, was exhilarating. As expected, the neurons now had a heightened potential, were easier to activate, waiting for more input. They slowly cooled down as Kassandra didn’t see any eagles.
She looked at the neurons connected to the fourth leaf. The gap. Was there a secret, fourth word hidden? One that all the zoologists studying vervet monkeys have missed so far? What would that word be? She reprogrammed the MRI helmet, aiming at the neurons that would trigger the fourth leaf. If her theory was right. With another click she sent a stimulus to the —
Janie was crouching in the corner of the room, breathing heavily, cold sweat was covering her arms, her face, her whole body. Her clothes were clamp. Her arms were slung above her head. She didn’t remember how she got here. The office chair she was just sitting in a moment ago, laid on the floor. The monkeys were quiet. Eerily quiet. She couldn’t see them from where she was, she couldn’t even see Kassandra from here, who was in the cage next to her computer. One of the halogen lamps in the ceiling was flickering. It wasn’t doing that before, was it?
She slowly stood up. Her body was shivering. She felt dizzy. She almost stumbled, just standing up. She slowly lowered her arms, but her arms were shaking. She looked for Kassandra. Kassandra was completely quiet, rolled up in the very corner of her cage, her arms slung around herself, her eyes staring catatonically forward, into nothing.
Janie took a step towards the middle of the room. She could see a bit more of the cage. The monkeys were partly huddled together, shaking in fear. One of them laid in the middle of the cage, his face in a grimace of terror. He was dead. She thought it was Rambo, but she wasn’t sure. She stumbled to the computer, pulled the chair from the floor, slumped into it.
The MRI helmet had recorded the activation pattern. She stepped through it. It did behave partially the same: the neurons triggered the unknown leaf, as expected, and that lead to activate the muscles around the lungs, the throat, the tongue, the mouth - in short, that activated the scream. But, unlike with the eagle scream, the activation potential did not increase, it was now suppressed. Like if it was trying to avoid a second triggering. She checked the pattern: yes, the neuron triggered that suppression itself. That was different. How did this secret scream sound?
Oh no! No, no, no, no, NOO!! She had not recorded the experiment. How stupid!
She was excited. She was scared, too, but she tried to push that away. She needed to record that scream. She needed to record the fourth word, the secret word of vervet monkeys. She switched on all three cameras in the lab, one pointed at the large cage with the monkeys, the other two pointing at Kassandra - and then she changed her mind, and turned one onto herself. What has happened to herself? Why couldn’t she remember hearing the scream? Why was she been crouching on the floor like one of the monkeys?
She checked her computer. The MRI helmet was calibrated as before, pointing at the group of triggering neurons. The suppression was ebbing down, but not as fast as she wanted. She increased the stimulation power. She shouldn’t. She should follow protocol. But this all was crazy. This was a cover story for Nature. With her as first author. She checked the recording devices. All three were on. The streams were feeding back into her computer. She clicked to send the sti—
She felt the floor beneath her. It was dirty and cold. She was laying on the floor, face down. Her ears were ringing. She turned her head, opened her eyes. Her vision was blurred. Over the ringing in her ears she didn’t hear a single sound from the monkeys. She tried to move, and she felt her pants were wet. She tried to stand up, to push herself up.
She couldn’t.
She panicked. Shivered. And when she felt the tears running over her face, she clenched her teeth together. She tried to breath, consciously, to collect herself, to gain control. Again she tried to stand up, and this time her arms and legs moved. Slower than she wanted. Weaker than she hoped. She was shaking. But she moved. She grabbed the chair. Pulled herself up a bit. The computer screen was as before, as if nothing has happened. She looked to Kassandra.
Kassandra was dead. Her eyes were bloodshot. Her face was a mask of pure terror, staring at nothing in the middle of the room. Janie tried to look at the cage with the other monkeys, but she couldn’t focus her gaze. She tried to yank herself into the chair.
The chair rolled away, and she crashed to the floor.
She had went too far. She had made a mistake. She should have had followed protocol. She was too ambitious, her curiosity and her impatience took the best of her. She had to focus. She had to fix things. But first she needed to call for help. She crawled to the chair. She pulled herself up, tried to sit in the chair, and she did it. She was sitting. Success.
Slowly, she rolled back to the computer. Her office didn’t have a phone. She double-clicked on the security app on her desktop. She had no idea how it worked, she never had to call security before. She hoped it would just work. A screen opened, asking her for some input. She couldn’t read it. She tried to focus. She didn’t know what to do. After a few moments the app changed, and it said in big letters: HELP IS ON THE WAY. STAY CALM. She closed her eyes. Breathed. Good.
After a few moments she felt better. She opened her eyes. HELP IS ON THE WAY. STAY CALM. She read it, once, twice. She nodded, her gaze jumping over the rest of the screen.
The recording was still on.
She moved the mouse cursor to the recording app. She wanted to see what has happened. There was nothing to do anyway, until security came. She clicked on the play button.
The recording filled three windows, one for each of the cameras. One pointed at the large cage with the vervet monkeys, two at Kassandra. Then, one of the cameras pointing at Kassandra was moved, pointing at Janie, just moments ago - it was moments, was it? - sitting at the desk. She saw herself getting ready to send the second stimulus to Kassandra, to make her call the secret scream a second time.
And then, from the recording, Kassandra called for a third time.
The end
History of knowledge graphs
An overview on the history of ideas leading to knowledge graphs, with plenty of references. Useful for anyone who wants to understand the background of the field, and probably the best current such overview.
On the competence of conspiracists
“Look, I’ll be honest, if living in the US for the last five years has taught me anything is that any government assemblage large enough to try to control a big chunk of the human population would in no way be consistently competent enough to actually cover it up. Like, we would have found out in three months and it wouldn’t even have been because of some investigative reporter, it would have been because one of the lizards forgot to put on their human suit on day and accidentally went out to shop for a pint of milk and like, got caught in a tik-tok video.” -- Os Keyes, WikidataCon, Keynote "Questioning Wikidata"
Power in California
It is wonderful to live in the Bay Area, where the future is being invented.
Sure, we might not have a reliable power supply, but hey, we have an app that connects people with dogs who don't want to pick up their poop with people who are desperate enough to do this shit.
Another example how the capitalism that we currently live failed massively: last year, PG&E was found responsible for killing people and destroying a whole city. Now they really want to play it safe, and switch off the power for millions of people. And they say this will go on for a decade. So in 2029 when we're supposed to have AIs, self-driving cars, and self-tieing Nikes, there will be cities in California that will get their power shut off for days when there is a hot wind for an afternoon.
Why? Because the money that should have gone into, that was already earmarked for, making the power infrastructure more resilient and safe went into bonus payments for executives (that sounds so cliché!). They tried to externalize the cost of an aging power infrastructure - the cost being literally the life and homes of people. And when told not to, they put millions of people in the dark.
This is so awfully on the nose that there is no need for metaphors.
San Francisco offered to buy the local power grid, to put it into public hands. But PG&E refused that offer of several billion dollars.
So if you live in an area that has a well working power infrastructure, appreciate it.
Academic lineage
Sorry for showing off, but it is just too cool not to: here is a visualization of my academic lineage according to Wikidata.
{kind=link}
Query: w.wiki/AE8
Bring me to your leader!
"Bring me to your leader!", the explorer demanded.
"What's a leader?", the natives asked.
"The guy who tells everyone what to do.", he explained with some consternation.
"Oh yeah, we have one like that, but why would you want to talk to him? He's unbearable."
AKTS 2019
September 24 was the AKTS workshop - Advanced Knowledge Technologies for Science in a FAIR world - co-located with the eScience and Gateways conferences in San Diego. As usual with my trip reports, I won't write about every single talk, but offer only my own personal selection and view. This is not an official report on the workshop.
I had the honor of kicking off the day. I made the proposal of using Wikidata for describing datasets so that dataset catalogs can add these descriptions to their indexes. The standard way to do so is to use Schema.org annotations describing the datasets, but our idea here was to provide a fallback solution in case Schema.org cannot be applied for one reason or the other. Since the following talks would also be talking about Wikidata I used the talk to introduce Wikidata in a bit more depth. In parallel, I kicked the same conversation off on Wikidata as well. The idea was well received, but one good question was raised by Andrew Su: why not add Schema.org annotations to Wikidata instead?
After that, Daniel Garijo of USC's ISI presented WDPlus, Wikidata Plus, which presented a prototype for how to extend Wikidata with more data (particularly tabular data) from external data sources, such as censuses and statistical publications. The idea is to surround Wikidata with a layer of so-called satellites, which materialize statistical and other external data into Wikidata's schema. They implemented a mapping languages, T2WDML, that allows to grab CSV numbers and turn them into triples that are compatible with Wikidata's schema, and thus can be queried together. There seems to be huge potential in this idea, particularly if one can connect the idea of federated SPARQL querying with on-the-fly mappings, extending Wikidata to a virtual knowledge base that would be easily several times its current size.
Andrew Su from Scripps Research talked about using Wikidata as a knowledge graph in a FAIR world. He presented their brilliant Gene Wiki project, about adding knowledge about genes and proteins to Wikidata. He presented the idea of using Wikidata as a generalized back-end for customized frontend-applications - which is perfect. Wikidata's frontend is solid and functional, but in many domains there is a large potential to improve the UX for users in specific domains (and we are seeing some if flowering more around Lexemes, with Lucas Werkmeister's work on lexical forms). Su and his lab developed ChlamBase which allows the Chlamydia research community to look at the data they are interested in, and to easily add missing data. Another huge advantage of using Wikidata? Your data is going to live beyond the life of the grant. A great overview of the relevant data in Wikidata can be seen in this rich and huge and complex diagram.
{kind=link}
The talks switched more to FAIR principles, first by Jeffrey Grethe of UCSD and then Mark Musen of Stanford. Mark was pointing out how quickly FAIR turned from a new idea to a meme that was pervasive everywhere, and the funding agencies now starting to require it. But data often has issues. One example: BioSample is the best metadata NIH has to offer. But 73% of the Boolean metadata values are not 'true' or 'false' but have values like "nonsmoker" or "recently quitted". 26% of the integers were not parseable. 68% of the entries from a controlled vocabulary were not. Having UX that helped with entering this data would be improving the quality considerably, such as CEDAR.
Carole Goble then talked about moving towards using Schema.org for FAIRer Life Sciences resources and defining a Schema.org profile that make datasets easier to use. The challenges in the field have been mostly social - there was a lot of confidence that we know how to solve the technical issues, but the social ones provide to be challenging. Carol named four of those explicitly:
- ontology-itis
- building consensus (it's harder than you think)
- the Schema.org Catch-22 (Schema.org won't take it if there is no usage, but people won't use it until it is in Schema.org)
- dedicated resources (people think you can do the social stuff in your spare time, but you can't)
Natasha Noy gave the keynote, talking about Google Dataset Search. The lessons learned from building it:
- Build an ecosystem first, be technically light-weight (a great lesson which was also true for Wikipedia and Wikidata)
- Use open, non-proprietary, standard solutions, don't ask people to build it just for Google (so in this case, use Schema.org for describing datasets)
- bootstrapping requires influencers (i.e. important players in the field, that need explicit outreach) and incentives (to increase numbers)
- semantics and the KG are critical ingredients (for quality assurance, to get the data in quickly, etc.)
At the same time, Natasha also reiterated one of Mark's points: no matter how simple the system is, people will get it wrong. The number of ways a date field can be written wrong is astounding. And often it is easier to make the ingester more accepting than try to get people to correct their metadata.
Chris Gorgolewski followed with a session on increasing findability for datasets, basically a session on SEO for dataset search: add generic descriptions, because people who need to find your dataset probably don't know your dataset and the exact terms (or they would already use it). Ensure people coming to your landing site have a pleasant experience. And the description is markup, so you can even use images.
I particularly enjoyed a trio of paper presentations by Daniel Garijo, Maria Stoica, Basel Shbita and Binh Vu. Daniel spoke about OntoSoft, an ontology to describe software workflows in sufficient detail to allow executing them, and also to create input and output definitions, describe the execution environment, etc. Close to those in- and output definition we find Maria's work on an ontology of variables. Maria presented a lot of work to identify the meaning of variables, based on linguistic, semantic, and ontological reasoning. Basel and Binh talked about understanding data catalogs deepers, being able to go deeper into the tables and understand the actual content in them. If one would connect the results of these three papers, one could potentially see how data from published tables and datasets could become alive and answer questions almost out of the box: extracting knowledge from tables, understanding their roles with regards to the input variables, and how to execute the scientific workflows.
Sure, science fiction, and the question is how well would each of the methods work, and how well would they work in concert, but hey, it's a workshop. It's meant for crazy ideas.
Ibrahim Burak Ozyurt presented an approach towards question answering in the bio-domain using Deep Learning, including Glove and BERT and all the other state of the art work. And it's all on Github! Go try it out.
The day closed with a panel with Mark Musen, Natasha Noy, and me, moderated by Yolanda Gil, discussing what we learned today. It quickly centered on the question how to ensure that people publishing datasets get appropriate credit. For most researchers, and particularly for universities, paper publications and impact factors are the main metric to evaluate researchers. So how do we ensure that people creating datasets (and I might add, tools, workflows, and social consensus) receive the fair share of credit?
Thanks to Yolanda Gil and Andrew Su for organizing the workshop! It was an exhausting, but lovely experience, and it is great to see the interest in this field.
Illuminati and Wikibase
When I was a teenager I was far too much fascinated by the Illuminati. Much less about the actual historical order, and more about the memetic complex, the trilogy by Shea and Wilson, the card game by Steve Jackson, the secret society and esoteric knowledge, the Templar Story, Holy Blood of Jesus, the rule of 5, the secret of 23, all the literature and offsprings, etc etc...
Eventually I went to actual order meetings of the Rosicrucians, and learned about some of their "secret" teachings, and also read Eco's Foucault's Pendulum. That, and access to the Web and eventually Wikipedia, helped to "cure" me from this stuff: Wikipedia allowed me to put a lot of the bits and pieces into context, and the (fascinating) stories that people like Shea & Wilson or von Däniken or Baigent, Leigh & Lincoln tell, start falling apart. Eco's novel, by deconstructing the idea, helps to overcome it.
He probably doesn't remember it anymore, but it was Thomas Römer who, many years ago, told me that the trick of these authors is to tell ten implausible, but verifiable facts, and tie them together with one highly plausible, but made-up fact. The appeal of their stories is that all of it seems to check out (because back then it was hard to fact check stuff, so you would use your time to check the most implausible stuff).
I still understand the allure of these stories, and love to indulge in them from time to time. But it was the Web, and it was learning about knowledge representation, that clarified the view on the underlying facts, and when I tried to apply the methods I was learning to it, it fell apart quickly.
So it is rather fascinating to see that one of the largest and earliest applications of Wikibase, the software we developed for Wikidata, turned out to be actual bona fide historians (not the conspiracy theorists) using it to work on the Illuminati, to catalog the letters they sent to reach other, to visualize the flow of information through the order, etc. Thanks to Olaf Simons for heading this project, and for this write up of their current state.
It's amusing to see things go round and round and realize that, indeed, everything is connected.
Wikidatan in residence at Google
Over the last few years, more and more research teams all around the world have started to use Wikidata. Wikidata is becoming a fundamental resource. That is also true for research at Google. One advantage of using Wikidata as a research resource is that it is available to everyone. Results can be reproduced and validated externally. Yay!
I had used my 20% time to support such teams. The requests became more frequent, and now I am moving to a new role in Google Research, akin to a Wikimedian in Residence: my role is to promote understanding of the Wikimedia projects within Google, work with Googlers to share more resources with the Wikimedia communities, and to facilitate the improvement of Wikimedia content by the Wikimedia communities, all with a strong focus on Wikidata.
One deeply satisfying thing for me is that the goals of my new role and the goals of the communities are so well aligned: it is really about improving the coverage and quality of the content, and about pushing the projects closer towards letting everyone share in the sum of all knowledge.
Expect to see more from me again - there are already a number of fun ideas in the pipeline, and I am looking forward to see them get out of the gates! I am looking forward to hearing your ideas and suggestions, and to continue contributing to the Wikimedia goals.
Deep kick
Mark Stoneward accepted the invitation immediately. Then it took two weeks for his lawyers at the Football Association to check the contracts and non-disclosure agreements prepared by the AI research company. Stoneward arrived at the glass and steel building in London downtown. He signed in at a fully automated kiosk, and was then accompanied by a friendly security guard to the office of the CEO.
Denise Mirza and Stoneward had met at social events, but never had time to talk for a longer time. “Congratulations on the results of the World Cup!” Stoneward nodded, “Thank you.”
“You have performed better than most of our models have predicted. This was particularly due to your willingness to make strategic choices, where other associations would simply have told their players to do their best. I am very impressed.” She looked at Stoneward, trying to read his face.
Stoneward’s face didn’t move. He didn’t want to give away how much was planned, how much was luck. He knew these things travel fast, and every little bit he could keep secret gave his team an edge. Mirza smiled. She recognised that poker face. “We know how to develop a computer system that could help you with even better strategic decisions.”
Stoneward tried to keep his face unmoved, but his body turned to Mirza and his arms opened a bit wider. Mirza knew that he was interested.
“If our models are correct, we can develop an Artificial Intelligence that could help you discuss your plans, help you with making the right strategic decisions, and play through different scenarios. Such AIs are already used in board rooms, in medicine, to create new recipes for top restaurants, or training chess players.”
“What about the other teams?”
“Well, we were hoping to keep this exclusive for two or four years, to test and refine the methodology. We are not in a hurry. Our models give us an overwhelming probability to win both the European Championship and the World Cup in case you follow our advice.”
“Overwhelming probability?”
“About 96%.”
“For the European Championship?”
“No. To win both.”
Stoneward gasped. “That is… hard to believe.”
The CEO laughed. “It is good that you are sceptical. I also doubted these probabilities, but I had two teams double-check.”
“What is that advice?”
She shrugged. “I don’t know yet. We need to develop the AI first. But I wanted to be sure you are actually interested before we invest in it.”
“You already know how effective the system will be without even having developed it yet?”
She smiled. “Our own decision process is being guided by a similar AI. There are so many things we could be doing. So many possible things to work on and revolutionise. We have to decide how to spend our resources and our time wisely.”
“And you’d rather spend your time on football than on… I don’t know, healing cancer or making a product that makes tons of money?”
“Healing cancer is difficult and will take a long time. Regarding money… the biggest impediment to speeding up the impact of our work is currently not a lack of resources, but a lack of public and political goodwill. People are worried about what our technology can do, and parliament and the European Union are eager to throw more and more regulations at us. What we need is something that will make every voter in England fall in love with us. That will open up the room for us to move more freely.”
Stoneward smiled. “Winning the World Cup.”
She smiled. “Winning the World Cup.”
Three months later…
“So, how will this work? Do I, uhm, type something in a computer, or do we have to run some program and I enter possible players we are considering to select?”
Mirza laughed. “No, nothing that primitive. The AI already knows all of your players. In fact, it knows all professional players in the world. It has watched and analyzed every second of TV screening of any game around the world, every relevant online video, and everything written in local newspapers.”
Stoneward nodded. That sounded promising.
“Here comes a little complication, though. We have a protocol for using our AIs. The protocols are overcautious. Our AIs are still far away from human intelligence, but our Ethics and Safety boards insisted on implementing these protocols whenever we use some of the near-human intelligence systems. It is completely overblown, but we are basically preparing ourselves for the time we have actually intelligent systems, maybe even superhuman intelligent systems.”
“I am afraid I don’t understand.”
“Basically, instead of talking to the AI directly, we talk with them through an operator, or medium.”
“Talk to them? You simply talk with the AI? Like with Siri?”
Mirza scoffed. “Siri is just a set of hard coded scripts and triggers.”
Stoneward didn’t seem impressed by the rant.
“The medium talks with the AI, tries its best to understand it, and then relays the AI’s advice to us. The protocol is strict about not letting the AI interact with decision makers directly.”
“Why?”
“Ah, as said, it is just being overly cautious. The protocol is in place in case we ever develop a superhuman intelligence, in which case we want to ensure that the AI doesn’t have too much influence on actual decision makers. The fear is that a superhuman AI could possibly unduly influence the decision maker. But with the medium in between, we have a filter, a normal intelligence, so it won’t be able to invert the relationship between adviser and decision maker.”
Stoneward blinked. “Pardon me, but I didn’t entirely follow what you — ”
“It’s just a Science Fiction scenario, but in case the AI tries to gain control, the fear is that a superhuman intelligence could basically turn you into a mindless muppet. By putting a medium in between, well, even if the medium becomes enslaved, the medium can only use their own intelligence against you. And that will fail.”
The director took a sip of water, and was pondering what he just heard for a few moments. Denise Mirza was burning with frustration. Sometimes she forgets how it is to deal with people this slow. And this guy had more balls banged against his skull than is healthy, which isn’t expected to speed his brain up. After what felt like half an eternity, he nodded.
“Are you ready for me to call the medium in?”
“Yes.”
She tapped her phone.
“Wait, does this mean that these mediums are slaves to your AI?”
She rolled her eyes. “Let us not discuss this in front of the medium, but I can assure you that our systems have not yet reached the level to convince a four year old to give up a lollipop, never mind a grown up person to do anything. We can discuss this more afterwards. Oh, there he is!”
Stoneward looked up surprised.
It was an old acquaintance, Nigel Ramsay. Ramsay used to manage some smaller teams in Lancashire, where Stoneward grew up. Ramsay was more known for his passion than for his talents.
“I am surprised to see you here”
The medium smiled. “It was a great offer, and when I learned what we are aiming for, I was positively thrilled. If this works we are going to make history!”
They sat down. “So, what does the system recommend?”
“Well, it recommends to increase the pressure on the government for a second referendum on Brexit.”
Stoneward stared at Ramsay, stunned. “Pardon me?”
“It is quite clear that the Prime Minister is intentionally sabotaging any reasonable solution for Brexit, but is too afraid to yet call a second referendum. She has been a double agent for the remainers the whole time. Once it is clear how much of a disaster leaving the European Union would be, we should call for a second referendum, reversing the result of the first.”
“I… I am not sure I follow… I thought we are talking football?”
“Oh, but yes! We most certainly are. Being part of an invigorated European Union after Brexit gets cancelled, we should strongly support a stronger Union, even the founding of a proper state.”
Stoneward looked at Ramsay with exasperation. Mirza motioned with her hands, asking for patience.
“Then, when the national football associations merge, this will pave the way for a single, unified European team.”
“The associations… merge?”
“Yes, an EU-wide all stars team. Just imagine that. Also, most of the serious competition would already be wiped out. No German team, no French team, just one European team and — “
“This is ridiculous! Reversing Brexit? Just to get a single European team? Even if we did, a unified European team might kill any interest in international football.”
“Yeah, that is likely true, but our winning chances would go through the roof!”
“But even then, 96% winning chances?”
“Oh, yeah, I asked the same. So, that’s not all. We also need to cause a war between Argentina and Brazil, in order to get them disqualified. There are a number of ways to get to this — ”
“Stop! Stop right there.” Stoneward looked shocked, his hands raised like a goalie waiting for the penalty kick. “Look, this is ridiculous. We will not stop Brexit or cause a war between two countries just to win a game.”
The medium looked at Stoneward in surprise. “To ‘just’ win a game?” His eyes wandered to Mirza in support. “I thought this was the sole reason for our existence. What does he mean, ‘just’ win a game? He is a bloody director of the FA, and he doesn’t care to win?”
“Maybe we should listen to some of the other suggestions?”, the CEO asked, trying to soothe the tension in the room.
Stoneward was visibly agitated, but after a few moments, he nodded. “Please continue.”
“So even if we don’t merge the European associations due to Brexit, we should at least merge the English, Scottish, Welsh, and Northern Irish associations in — ”
“No, no, NO! Enough of this association merging nonsense. What else do you have?”
“Well, without mergers, and wars, we’re down to 44% probability to win both the European and World Cup within the next twenty years.” The medium sounded defeated.
“That’s OK, I’ll take that. Tell me more.” Stoneward has known that the probabilities given before were too good to be true. It was still a disappointment.
“England has some of the best schools in the world. We should use this asset to lure young talent to England, offer them scholarships in Oxford, in Cambridge.”
“But they wouldn’t be English? They can’t play for England.”
“We would need to make the path to citizenship easier for them, immigration laws should be more integrative for top talent. We need to give them the opportunity to become subjects of the Queen before they play their first international. And then offer them to play for England. There is so much talent out there, and if we can get them while they’re young, we could prep up our squad in just a few years.”
“Scholarships for Oxford? How much would that even cost?”
“20, 25 thousand per year and student? We can pay a hundred scholarships and it wouldn’t even show up in our budget.”
“We are cutting budgets left and right!”
“Since we’re not stopping Brexit, why not dip into those 350 million pounds per week that we will save.”
“That was a lie!”
“I was joking.”
“Well, the scholarship thing wasn’t bad. What else is on the table?”
“One idea was to hack the video stream and bribe the referee, and then we can safely gaslight everyone.”
“Next idea.”
“We could poison the other teams.”
“Just stop it.”
“Or give them substances that would mess up their drug tests.”
“Why not getting FIFA to change the rules so we always win?”
“Oh, we considered it, but given the existing corruption inside FIFA it seems that would be difficult to outbid.”
Stonward sighed. “Now I was joking.”
“One suggestion is to create a permanent national team, and have them play in the national league. So they would be constantly competing, playing with each other, be better used to each other. A proper team.”
“How would we even pay for the players?”
“It would be an honor to play for the national team. Also, it could be a new rule to require the best players to play in the national team.”
“I think we are done here. These suggestions were… rather interesting. But I think they were mostly unactionable.” He started standing up.
Mirza looked desperately from one to the other. This meeting did not go as she had intended. “I think we can acknowledge the breadth of the creative proposals that have been on the table today, and enjoy a tea before you leave?”, she said, forcing a smile.
Stoneward nodded politely. “We sure can appreciate the creativity.”
“Now imagine this creativity turned into strategies in the pitch. Tactical moves. Variations to set pieces.”, the medium started, his voice slightly shifting.
“Yes, well, that would certainly be more interesting than most of the suggestions so far.”
“Wouldn’t it? And not only that, but if we could talk to the players. If we could expand their own creativity. Their own willpower. Their focus. Their energy to power through, not to give up.”
“If you’re suggesting to give them drugs, I am out.”
Ramsay laughed. “No, not drugs. But a helmet that emits electromagnetic waves and allows the brain muscles to work in more interesting ways.”
Stoneward looked over to the CEO. “Is that a possibility?”
Mirza looked uncomfortable, but tried to hide it. “Yes, yes, it is. We had tested it a few times, and the results were quite astonishing. It is just not what I would have expected as a proposal.”
“Why? Anything wrong with that?”
“Well, we use it for our top engineers, to help them focus when developing and designing solutions. The results are nothing short of marvelous. It is just, I didn’t think football would benefit that much from improved focus.”
Stoneward chuckled, as he sat down again. “Yes, many people underestimate the role of a creative mind in the game. I think I would now like a tea.” He looked to Ramsay. “Tell me more.”
The medium smiled. The system will be satisfied with the outcome.
(Originally published July 28, 2018 on Medium)
Saturn the alligator
Today at work I learned about Saturn the alligator. Born to humble origins in 1936 in Mississippi, he moved to Berlin where he became acquainted with Hitler. After the bombing of the Berlin Zoo he wandered through the streets. British troops found him, gave him to the Soviets, where against all odds he survived a number of near death situations - among others he refused to eat for a year - and still lives today, in an enclosure sponsored by Lacoste.
I also went to Wikidata to improve the entry on Saturn. For that I needed to find the right property to express the connection between Saturn, and the Moscow Zoo, where he is held.
The following SPARQL query was helpful: https://w.wiki/7ga
It tells you which properties connect animals with zoos how often - and in the Query Helper UI it should be easy to change either types to figure out good candidates for the property you are looking for.
Wikidata reached a billion edits
As of today, Wikidata has reached a billion edits - 1,000,000,000.
This makes it the first Wikimedia project that has reached that number, and possibly the first wiki ever to have reached so many edits. Given that Wikidata was launched less than seven years ago, this means an average edit rate of 4-5 edits per second.
The billionth edit is the creation of an item for a 2006 physics article written in Chinese.
Congratulations to the community! This is a tremendous success.
In the beginning
"Let there be a planet with a hothouse effect, so that they can see what happens, as a warning."
"That is rather subtle, God", said the Archangel.
"Well, let it be the planet closest to them. That should do it. They're intelligent after all."
"If you say so."
Lion King 2019
Wow. The new version of the Lion King is technically brilliant, and story-wise mostly unnecessary (but see below for an exception). It is a mostly beat-for-beat retelling of the 1994 animated version. The graphics are breathtaking, and they show how far computer-generated imagery has come. For a measly million dollar per minute of film you can get a photorealistic animal movies. Because of the photorealism, it also loses some of the charm and the emotions that the animated version carried - in the original the animals were much more anthropomorphic, and the dancing was much more exaggerated, which the new version gave up. This is most noticeable in the song scene for "I can't wait to be king", which used to be a psychedelic, color shifted sequence with elephants and tapirs and giraffes stacked upon each other, replaced by a much more realistic sequence full of animals and fast cuts that simply looks amazing (I never was a big fan of the psychedelic music scenes that were so frequent in many animated movies, so I consider this a clear win).
I want to focus on the main change, and it is about Scar. I know the 1994 movie by heart, and Scar is its iconic villain, one of the villains that formed my understanding of a great villain. So why would the largest change be about Scar, changing him profoundly for this movie? How risky a choice in a movie that partly recreates whole sequences shot by shot?
There was one major criticism about Scar, and that is that he played with stereotypical tropes of gay grumpy men, frustrated, denied, uninterested in what the world is offering him, unable to take what he wants, effeminate, full of cliches.
That Scar is gone, replaced by a much more physically threatening scar, one that whose philosophy in life is that the strongest should take what they want. Chiwetel Ejiofor's voice for Scar is scary, threatening, strong, dominant, menacing. I am sure that some people won't like him, as the original Scar was also a brilliant villain, but this leads immediately to my big criticism of the original movie: if Scar was only half as effing intelligent as shown, why did he do such a miserable job in leading the Pride Lands? If he was so much smarter than Mufasa, why did the thriving Pride Lands turn into a wasteland, threatening the subsistence of Scar and his allies?
The answer in the original movie is clear: it's the absolutist identification of country and ruler. Mufasa was good, therefore the Pride Lands were doing well. When Scar takes over, they become a wasteland. When Simba takes over, in the next few shots, they start blooming again. Good people, good intentions, good outcomes. As simple as that.
The new movie changes that profoundly - and in a very smart way. The storytellers at Disney really know what they're doing! Instead of following the simple equation given above, they make it an explicit philosophical choice in leadership. This time around, the whole Circle of Life thing, is not just an Act One lesson, but is the major difference between Mufasa and Scar. Mufasa describes a great king as searching for what they can give. Scar is about might is right, and about the strongest taking whatever they want. This is why he overhunts and allows overhunting. This is why the Pride Lands become a wasteland. Now the decline of the Pride Lands make sense, and also why the return of Simba and his different style as a king would make a difference. The Circle of Life now became important for the whole movie, at the same time tying with the reinterpretation of Scar, and also explaining the difference in outcome.
You can probably tell, but I am quite amazed at this feat in storytelling. They took a beloved story and managed to improve it.
Unfortunately, the new Scar also means that the song Be Prepared doesn't really work as it used to, and thus the song also got shortened and very much changed in a movie that became much longer otherwise. I am not surprised, they even wanted to remove it, and now I understand why (even though back then I grumbled about it). They also removed the Leni Riefenstahl imaginary from the new version which was there in the original one, which I find regrettable, but obviously necessary given the rest of the movie.
A few minor notes.
The voice acting was a mixed bag. Beyonce was surprisingly bland (speaking, her singing was beautiful), and so was John Oliver (singing, his speaking was perfect). I just listened again to I can't wait to be king, and John Oliver just sounds so much less emotional than Rowan Atkinson. Pity.
Another beautiful scene was the scene were Rafiki receives the massage that Simba is still alive. In the original, this was a short transition of Simba ruffling up some flowers, and the wind takes them to Rafiki, he smells them, and realizes it is Simba. Now the scene is much more elaborate, funnier, and is reminiscent of Walt Disney's animal movies, which is a beautiful nod to the company founder. Simba's hair travels with the wind, birds, a Giraffe, an ant, and more, until it finally reaches the Shaman's home.
One of my best laughs was also due to another smart change: in Hakuna Matata, when they retell Pumbaa's story (with an incredibly cute little baby Pumbaa), Pumbaa laments that all his friends leaving him got him "unhearted, every time that he farted", and immediately complaining to Timon as to why he didn't stop him singing it - a play on the original's joke, where Timon interjects Pumbaa before he finishes the line with "Pumbaa! Not in front of the kids.", looking right at the camera and breaking the fourth wall.
Another great change was to give the Hyenas a bit more character - the interactions between the Hyena who wasn't much into personal space and the other who rather was, were really amusing. Unlike with the original version the differences in the looks of the Hyenas are harder to make out, and so giving them more personality is a great choice.
All in all, I really loved this version. Seeing it on the big screen pays off for the amazing imagery that really shines on a large canvas. I also love the original, and the original will always have a special place in my heart, but this is a wonderful tribute to a brilliant movie with an exceptional story.
210,000 year old human skull found in Europe
A Homo Sapiens skull that is 210,000 years old had been found in Greece, together with a Neanderthal skull from 175,000 years ago.
The oldest European Homo Sapiens remains known so far only date to 40,000 years ago.
Draft: Collaborating on the sum of all knowledge across languages
For the upcoming Wikipedia@20 book, I published my chapter draft. Comments are welcome on the pubpub Website until July 19.
Every language edition of Wikipedia is written independently of every other language edition. A contributor may consult an existing article in another language edition when writing a new article, or they might even use the Content Translation tool to help with translating one article to another language, but there is nothing that ensures that articles in different language editions are aligned or kept consistent with each other. This is often regarded as a contribution to knowledge diversity, since it allows every language edition to grow independently of all other language editions. So would creating a system that aligns the contents more closely with each other sacrifice that diversity?
Differences between Wikipedia language editions
Wikipedia is often described as a wonder of the modern age. There are more than 50 million articles in almost 300 languages. The goal of allowing everyone to share in the sum of all knowledge is achieved, right?
Not yet.
The knowledge in Wikipedia is unevenly distributed. Let’s take a look at where the first twenty years of editing Wikipedia have taken us.
The number of articles varies between the different language editions of Wikipedia: English, the largest edition, has more than 5.8 million articles, Cebuano — a language spoken in the Philippines — has 5.3 million articles, Swedish has 3.7 million articles, and German has 2.3 million articles. (Cebuano and Swedish have a large number of machine generated articles.) In fact, the top nine languages alone hold more than half of all articles across the Wikipedia language editions — and if you take the bottom half of all Wikipedias ranked by size, they together wouldn’t have 10% of the number of articles in the English Wikipedia.
It is not just the sheer number of articles that differ between editions, but their comprehensiveness does as well: the English Wikipedia article on Frankfurt has a length of 184,686 characters, a table of contents spanning 87 sections and subsections, 95 images, tables and graphs, and 92 references — whereas the Hausa Wikipedia article states that it is a city in the German state of Hesse, and lists its population and mayor. Hausa is a language spoken natively by 40 million people and as a second language by another 20 million.
It is not always the case that the large Wikipedia language editions have more content on a topic. Although readers often consider large Wikipedias to be more comprehensive, local Wikipedias may frequently have more content on topics of local interest: the English Wikipedia knows about the Port of Călărași that it is one of the largest Romanian river ports, located at the Danube near the town of Călărași — and that’s it. The Romanian Wikipedia on the other hand offers several paragraphs of content about the port.
The topics covered by the different Wikipedias also overlap less than one would initially assume. English Wikipedias has 5.8 million articles, German has 2.2 million articles — but only 1.1 million topics are covered by both Wikipedias. A full 1.1 million topics have an article in German — but not in English. The top ten Wikipedias by activity — each of them with more than a million articles — have articles on only hundred thousand topics in common. 18 million topics are covered by articles in the different language Wikipedias — and English only covers 31% of these.
Besides coverage, there is also the question of how up to date the different language editions are: in June 2018, San Francisco elected London Breed as its new mayor. Nine months later, in March 2019, I conducted an analysis of who the mayor of San Francisco was, according to the different language versions of Wikipedia. Of the 292 language editions, a full 165 had a Wikipedia article on San Francisco. Of these, 86 named the mayor. The good news is that not a single Wikipedia lists a wrong mayor — but the vast majority are out of date. English switched the minute London Breed was sworn in. But 62 Wikipedia language editions list an out-of-date mayor — and not just the previous mayor Ed Lee, who became mayor in 2011, but also often Gavin Newsom (2004-2011), and his predecessor, Willie Brown (1996-2004). The most out-of-date entry is to be found in the Cebuano Wikipedia, who names Dianne Feinstein as the mayor of San Francisco. She had that role after the assassination of Harvey Milk and George Moscone in 1978, and remained in that position for a decade in 1988 — Cebuano was more than thirty years out of date. Only 24 language editions had listed the current mayor, London Breed, out of the 86 who listed the name at all.
An even more important metric for the success of a Wikipedia are the number of contributors: English has more than 31,000 active contributors — three out of seven active Wikimedians are active on the English Wikipedia. German, the second most active Wikipedia community, already only has 5,500 active contributors. Only eleven language editions have more than a thousand active contributors — and more than half of all Wikipedias have fewer than ten active contributors. To assume that fewer than ten active contributors can write and maintain a comprehensive encyclopedia in their spare time is optimistic at best. These numbers basically doom the mission of the Wikimedia movement to realize a world where everyone can contribute to the sum of all knowledge.
Enter Wikidata
Wikidata was launched in 2012 and offers a free, collaborative, multilingual, secondary database, collecting structured data to provide support for Wikipedia, Wikimedia Commons, the other wikis of the Wikimedia movement, and to anyone in the world. Wikidata contains structured information in the form of simple claims, such as “San Francisco — Mayor — London Breed”, qualifiers, such as “since — July 11, 2018”, and references for these claims, e.g. a link to the official election results as published by the city.
One of these structured claims would be on the Wikidata page about San Francisco and state the mayor, as discussed earlier. The individual Wikipedias can then query Wikidata for the current mayor. Of the 24 Wikipedias that named the current mayor, eight were current because they were querying Wikidata. I hope to see that number go up. Using Wikidata more extensively can, in the long run, allow for more comprehensive, current, and accessible content while decreasing the maintenance load for contributors.
Wikidata was developed in the spirit of the Wikipedia’s increasing drive to add structure to Wikipedia’s articles. Examples of this include the introduction of infoboxes as early as 2002, a quick tabular overview of facts about the topic of the article, and categories in 2004. Over the year, the structured features became increasingly intricate: infoboxes moved to templates, templates started using more sophisticated MediaWiki functions, and then later demanded the development of even more powerful MediaWiki features. In order to maintain the structured data, bots were created, software agents that could read content from Wikipedia or other sources and then perform automatic updates to other parts of Wikipedia. Before the introduction of Wikidata, bots keeping the language links between the different Wikipedias in sync, easily contributed 50% and more of all edits.
Wikidata allowed for an outlet to many of these activities, and relieved the Wikipedias of having to run bots to keep language links in sync or of massive infobox maintenance tasks. But one lesson I learned from these activities is that I can trust the communities with mastering complex workflows spread out between community members with different capabilities: in fact, a small number of contributors working on intricate template code and developing bots can provide invaluable support to contributors who more focus on maintaining articles and contributors who write large swaths of prose. The community is very heterogeneous, and the different capabilities and backgrounds complement each other in order to create Wikipedia.
However, Wikidata’s structured claims are of a limited expressivity: their subject always must be the topic of the page, every object of a statement must exist as its own item and thus page in Wikidata. If it doesn’t fit in the rigid data model of Wikidata, it simply cannot be captured in Wikidata — and if it cannot be captured in Wikidata, it cannot be made accessible to the Wikipedias.
For example, let’s take a look at the following two sentences from the English Wikipedia article on Ontario, California:
“To impress visitors and potential settlers with the abundance of water in Ontario, a fountain was placed at the Southern Pacific railway station. It was turned on when passenger trains were approaching and frugally turned off again after their departure.”
There is no feasible way to express the content of these two sentences in Wikidata - the simple claim and qualifier structure that Wikidata supports can not capture the subtle situation that is described here.
An Abstract Wikipedia
I suggest that the Wikimedia movement develop an Abstract Wikipedia, a Wikipedia in which the actual textual content is being represented in a language-independent manner. This is an ambitious goal — it requires us to push the current limits of knowledge representation, natural language generation, and collaborative knowledge construction by a significant amount: an Abstract Wikipedia must allow for:
- relations that connect more than just two participants with heterogeneous roles.
- composition of items on the fly from values and other items.
- expressing knowledge about arbitrary subjects, not just the topic of the page.
- ordering content, to be able to represent a narrative structure.
- expressing redundant information.
Let us explore one of these requirements, the last one: unlike the sentences of a declarative formal knowledge base, human language is usually highly redundant. Formal knowledge bases usually try to avoid redundancy, for good reasons. But in a natural language text, redundancy happens frequently. One example is the following sentence:
“Marie Curie is the only person who received two Nobel Prizes in two different sciences.”
The sentence is redundant given a list of Nobel Prize award winners and their respective disciplines they have been awarded to — a list that basically every large Wikipedia will contain. But the content of the given sentence nevertheless appears in many of the different language articles on Marie Curie, and usually right in the first paragraph. So there is obviously something very interesting in this sentence, even though the knowledge expressed in this sentence is already fully contained in most of the Wikipedias it appears in. This form of redundancy is common place in natural language — but is usually avoided in formal knowledge bases.
The technical details of the Abstract Wikipedia proposal are presented in (Vrandečić, 2018). But the technical architecture is only half of the story. Much more important is the question whether the communities can meet the challenges of this project?
Wikipedia and Wikidata have shown that the communities are capable to meet difficult challenges: be it templates in Wikipedia, or constraints in Wikidata, the communities have shown that they can drive comprehensive policy and workflow changes as well as the necessary technological feature development. Not everyone needs to understand the whole stack in order to make a feature such as templates a crucial part of Wikipedia.
The Abstract Wikipedia is an ambitious future project. I believe that this is the only way for the Wikimedia movement to achieve its goal, short of developing an AI that will make the writing of a comprehensive encyclopedia obsolete anyway.
A plea for knowledge diversity?
When presenting the idea of the Abstract Wikipedia, the first question is usually: will this not massively reduce the knowledge diversity of Wikipedia? By unifying the content between the different language editions, does this not force a single point of view on all languages? Is the Abstract Wikipedia taking away the ability of minority language speakers to maintain their own encyclopedias, to have a space where, for example, indigenous speakers can foster and grow their own point of view, without being forced to unify under the western US-dominated perspective?
I am sympathetic with the intent of this question. The goal of this question is to ensure that a rich diversity in knowledge is retained, and to make sure that minority groups have spaces in which they can express themselves and keep their knowledge alive. These are, in my opinion, valuable goals.
The assumption that an Abstract Wikipedia, from which any of the individual language Wikipedias can draw content from, will necessarily reduce this diversity, is false. In fact, I believe that access to more knowledge and to more perspectives is crucial to achieve an effective knowledge diversity, and that the currently perceived knowledge diversity in different language projects is ineffective at best, and harmful at worst. In the rest of this essay I will argue why this is the case.
Language does not align with culture
First, it is wrong to use language as the dimension along which to draw the demarcation line between different content if the Wikimedia movement truly believes that different groups should be able to grow and maintain their own encyclopedias.
In case the Wikimedia movement truly believes that different groups or cultures should have their own Wikipedias, why is there only a single Wikipedia language edition for the English speakers from India, England, Scotland, Australia, the United States, and South Africa? Why is there only one Wikipedia for Brazil and Portugal, leading to much strife? Why are there no two Wikipedias for US Democrats and Republicans?
The conclusion is that the Wikimedia movement does not believe that language is the right dimension to split knowledge — it is a historical decision, driven by convenience. The core Wikipedia policies, vision, and mission are all geared towards enabling access to the sum of all knowledge to every single reader, no matter what their language, and not toward capturing all knowledge and then subdividing it for consumption based on the languages the reader is comfortable in.
The split along languages leads to the problem that it is much easier for a small language community to go “off the rails” — to either, as a whole, become heavily biased, or to adopt rules and processes which are problematic. The fact that the larger communities have different rules, processes, and outcomes can be beneficial for Wikipedia as a whole, since they can experiment with different rules and approaches. But this does not seem to hold true when the communities drop under a certain size and activity level, when there are not enough eyeballs to avoid the development of bad outcomes and traditions. For one example, the article about skirts in the Bavarian Wikipedia features three upskirt pictures, one porn actress, an anime screenshot, and a video showing a drawing of a woman with a skirt getting continuously shorter. The article became like this within a day or two of its creation, and, even though it has been edited by a dozen different accounts, has remained like this over the last seven years. (This describes the state of the article in April 2019 — I hope that with the publication of this essay, the article will finally be cleaned up).
A look on some south Slavic language Wikipedias
Second, a natural experiment is going on, where contributors that are more separated by politics than language differences have separate Wikipedias: there exist individual Wikipedia language editions for Croatian, Serbian, Bosnian, and Serbocroatian. Linguistically, the differences between the dialects of Croatian are often larger than the differences between standard Croatian and standard Serbian. Particularly the existence of the Serbocroatian Wikipedia poses interesting questions about these delineations.
Particularly the Croatian Wikipedia has turned to a point of view that has been described as problematic. Certain events and Croat actors during the 1990s independence wars or the 1940s fascist puppet state might be represented more favorably than in most other Wikipedias.
Here are two observations based on my work on south Slavic language Wikipedias:
First, claiming that a more fascist-friendly point of view within a Wikipedia increases the knowledge diversity across all Wikipedias might be technically true, but is practically insufficient. Being able to benefit from this diversity requires the reader to not only be comfortable reading several different languages, but also to engage deeply enough and spend the time and interest to actually read the article in different languages, which is mostly a profoundly boring exercise, since a lot of the content will be overlapping. Finding the juicy differences is anything but easy, especially considering that most readers are reading Wikipedia from mobile devices, and are just looking to satisfy a quick information need from a source whose curation they trust.
Most readers will only read a single language version of an article, and thus any diversity that exists across different language editions is practically lost. The sheer existence of this diversity might even be counterproductive, as one may argue that the communities should not spend resources on reflecting the true diversity of a topic within each individual language. This would cement the practical uselessness of the knowledge diversity across languages.
Second, many of the same contributors that write the articles with a certain point of view in the Croatian Wikipedia, also contribute on the English Wikipedia on the articles about the same topics — but there they suddenly are forced and able to compromise and incorporate a much wider variety of points of view. One might hope the contributors would take the more diverse points of view and migrate them back to their home Wikipedias — but that is often not the case. If contributors harbor a certain point of view (and who doesn’t?) it often leads to a situation where they push that point of view as much as they can get away with in each of the projects.
It has to be noted that the most blatant digressions from a neutral point of view in Wikipedias like the Croatian Wikipedia will not be found in the most central articles, but in the large periphery of articles surrounding these central articles which are much harder to keep an eye on.
Abstract Wikipedia and Knowledge diversity
The Abstract Wikipedia proposal does not require any of the individual language editions to use it. Each language community can decide for each article whether to fall back on the Abstract Wikipedia or whether to create their own article in their language. And even that decision can be more fine grained: a contributor can decide for an individual article to incorporate sections or paragraphs from the Abstract Wikipedia.
This allows the individual Wikipedia communities the luxury to entirely concentrate on the differences that are relevant to them. I distinctly remember that when I started the Croatian Wikipedia: it felt like I had the burden to first write an article about every country in the world before I could write the articles I cared about, such as my mother’s home village — because how could anyone defend a general purpose encyclopedia that might not even have an article on Nigeria, a country with a population of a hundred million, but one on Donji Humac, a village with a population of 157? Wouldn’t you first need an article on all of the chemical elements that make up the world before you can write about a local food?
The Abstract Wikipedia frees a language edition from this burden, and allows each community to entirely focus on the parts they care about most — and to simply import the articles from the common source for the topics that are less in their focus. It allows the community to make these decisions. As the communities grow and shift, they can revisit these decisions at any time and adapt them.
At the same time, the Abstract Wikipedia makes these differences more visible since they become explicit. Right now there is no easy way to say whether the fact that Dianne Feinstein is listed as the Mayor of San Francisco in the Cebuano Wikipedia is due to cultural particularities of the Cebuano language communities or not. Are the different population numbers of Frankfurt in the different language editions intentional expressions of knowledge diversity? With an Abstract Wikipedia, the individual communities could explicitly choose which articles to create and maintain on their own, and at the same time remove a lot of unintentional differences.
By making these decisions more explicit, it becomes possible to imagine an effective workflow that observes these intentional differences, and sets up a path to integrate them into the common article in the Abstract Wikipedia. Right now, there are 166 different language versions of the article on the chemical element Helium — it is basically impossible for a single person to go through all of them and find the content that is intentionally different between them. With an Abstract Wikipedia, which contains the common shared knowledge, contributors, researchers, and readers can actually take a look at those articles that intentionally have content that replaces or adds to the commonly shared one, assess these differences, and see if contributors should integrate the differences in the shared article.
The differences in content may be reflecting difference in policies, particularly in policies of notability and reliability. Whereas on first glance it might seem that the Abstract Wikipedia might require unified notability and reliability requirements across all Wikipedias, this is not the case: due to the fact that local Wikipedias can overlay and suppress content from the Abstract Wikipedias, they can adjust their Wikipedias based on their own rules. And the increased visibility of such decisions will lead to easier identify biases, and hopefully also to updated rules to reduce said bias.
A new incentive infrastructure
The Abstract Wikipedia will evolve the incentive infrastructure of Wikipedia.
Presently, many underrepresented languages are spoken in areas that are multilingual. Often another language spoken in this area is regarded as a high-prestige language, and is thus the language of education and literature, whereas the underrepresented language is a low-prestige language. So even though the low-prestige language might have more speakers, the most likely recruits for the Wikipedia communities, people with education who can afford internet access and have enough free time, will be able to contribute in both languages.
In which language should I contribute? If I write the article about my mother’s home town in Croatian, I make it accessible to a few million people. If I write the article about my mother’s home town in English, it becomes accessible to more than a hundred times as many people! The work might be the same, but the perceived benefit is orders of magnitude higher: the question becomes, do I teach the world about a local tradition, or do I tell my own people about their tradition? The world is bigger, and thus more likely to react, creating a positive feedback loop.
This cannibalizes the communities for local languages by diverting them to the English Wikipedia, which is perceived as the global knowledge community (or to other high-prestige languages, such as Russian or French). This is also reflected in a lot of articles in the press and in academic works about Wikipedia, where the English Wikipedia is being understood as the Wikipedia. Whereas it is known that Wikipedia exists in many other languages, journalists and researchers are, often unintentionally, regarding the English Wikipedia as the One True Wikipedia.
Another strong impediment to recruiting contributors to smaller Wikipedia communities is rarely explicitly called out: it is pretty clear that, given the current architecture, these Wikipedias are doomed in achieving their mission. As discussed above, more than half of all Wikipedia language editions have fewer than ten active contributors — and writing a comprehensive, up-to-date Wikipedia is not an achievable goal with so few people writing in their free time. The translation tools offered by the Wikimedia Foundation can considerably help within certain circumstances — but for most of the Wikipedia languages, automatic translation models don’t exist and thus cannot help the languages which would need it the most.
With the Abstract Wikipedia though, the goal of providing a comprehensive and current encyclopedia in almost any language becomes much more tangible: instead of taking on the task of creating and maintaining the entire content, only the grammatical and lexical knowledge of a given language needs to be created. This is a far smaller task. Furthermore, this grammatical and lexical knowledge is comparably static — it does not change as much as the encyclopedic content of Wikipedia, thus turning a task that is huge and ongoing into one where the content will grow and be maintained without the need of too much maintenance by the individual language communities.
Yes, the Abstract Wikipedia will require more and different capabilities from a community that has yet to be found, and the challenges will be both novel and big. But the communities of the many Wikimedia projects have repeatedly shown that they can meet complex challenges with ingenious combinations of processes and technological advancements. Wikipedia and Wikidata have both demonstrated the ability to draw on technologically rather simple canvasses, and create extraordinary rich and complex masterpieces, which stand the test of time. The Abstract Wikipedia aims to challenge the communities once again, and the promise this time is nothing else but to finally be able to reap the ultimate goal: to allow every one, no matter what their native language is, to share in the sum of all knowledge.
Acknowledgements
Thanks to the valuable suggestions on improving the article to Jamie Taylor, Daniel Russell, Joseph Reagle, Stephen LaPorte, and Jake Orlowitz.
Bibliography
- Bao, Patti, Brent J. Hecht, Samuel Carton, Mahmood Quaderi, Michael S. Horn and Darren Gergle. “Omnipedia: bridging the wikipedia language gap.” in Proceedings of the Conference on Human Factors in Computing Systems (CHI 2012), edited by Joseph A. Konstan, Ed H. Chi, and Kristina Höök. Austin: Association for Computing Machinery, 2012: 1075-1084.
- Eco, Umberto. The Search for the Perfect Language (the Making of Europe). La ricerca della lingua perfetta nella cultura europea. Translated by James Fentress. Oxford: Blackwell, 1995 (1993).
- Graham, Mark. “The Problem With Wikidata.” The Atlantic, April 6, 2012. https://www.theatlantic.com/technology/archive/2012/04/the-problem-with-wikidata/255564/
- Hoffmann, Thomas and Graeme Trousdale, “Construction Grammar: Introduction”. In The Oxford Handbook of Construction Grammar, edited by Thomas Hoffmann and Graeme Trousdale, 1-14. Oxford: Oxford University Press, 2013.
- Kaffee, Lucie-Aimée, Hady ElSahar, Pavlos Vougiouklis, Christophe Gravier, Frédérique Laforest, Jonathon S. Hare and Elena Simperl. “Mind the (Language) Gap: Generation of Multilingual Wikipedia Summaries from Wikidata for Article Placeholders.” in Proceedings of the 15th European Semantic Web Conference (ESWC 2018), edited by Aldo Gangemi, Roberto Navigli, Marie-Esther Vidal, Pascal Hitzler, Raphaël Troncy, Laura Hollink, Anna Tordai, and Mehwish Alam. Heraklion: Springer, 2018: 319-334.
- Kaffee, Lucie-Aimée, Hady ElSahar, Pavlos Vougiouklis, Christophe Gravier, Frédérique Laforest, Jonathon S. Hare and Elena Simperl. “Learning to Generate Wikipedia Summaries for Underserved Languages from Wikidata.” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2, edited by Marilyn Walker, Heng Ji, and Amanda Stent. New Orleans: ACL Anthology, 2018: 640-645.
- Schindler, Mathias and Denny Vrandečić. “Introducing new features to Wikipedia: Case studies for Web Science.” IEEE Intelligent Systems 26, no. 1 (January-February 2011): 56-61.
- Vrandečić, Denny. “Restricting the World.” Wikimedia Deutschland Blog. February 22, 2013. https://blog.wikimedia.de/2013/02/22/restricting-the-world/
- Vrandečić, Denny and Markus Krötzsch. “Wikidata: A Free Collaborative Knowledgebase.” Communications of the ACM 57, no. 10 (October 2014): 78-85. DOI 10.1145/2629489.
- Kaljurand, Kaarel and Tobias Kuhn. “A Multilingual Semantic Wiki Based on Attempto Controlled English and Grammatical Framework.” in Proceedings of the 10th European Semantic Web Conference (ESWC 2013), edited by Philipp Cimiano, Oscar Corcho, Valentina Presutti, Laura Hollink, and Sebastian Rudolph. Montpellier: Springer, 2013: 427-441.
- Milekić, Sven. “Croatian-language Wikipedia: when the extreme right rewrites history.” Osservatorio Balcani e Caucaso, September 27, 2018. https://www.balcanicaucaso.org/eng/Areas/Croatia/Croatian-language-Wikipedia-when-the-extreme-right-rewrites-history-190081
- Ranta, Aarne. Grammatical Framework: Programming with Multilingual Grammars. Stanford: CSLI Publications, 2011.
- Vrandečić, Denny. “Towards a multilingual Wikipedia,” in Proceedings of the 31st International Workshop on Description Logics (DL 2018), edited by Magdalena Ortiz and Thomas Schneider. Phoenix: Ceur-WS, 2018.
- Wierzbicka, Anna. Semantics: Primes and Universals. Oxford: Oxford University Press, 1996.
- Wikidata Community: “Lexicographical data.” Accessed June 1, 2019. https://www.wikidata.org/wiki/Wikidata:Lexicographical_data
- Wulczyn, Ellery, Robert West, Leila Zia and Jure Leskovec. “Growing Wikipedia Across Languages via Recommendation.” in Proceedings of the 25th International World-Wide Web Conference (WWW 2016), edited by Jaqueline Bourdeau, Jim Hendler, Roger Nkambou, Ian Horrocks, and Ben Y. Zhao. Montréal: IW3C2, 2016: 975-985.
Toy Story 4
Toy Story 4 was great fun!
Toy Story 3 had a great closure (and a lot of tears), so would, what could they do to justify a fourth part? They developed the characters further than ever before. Woody is faced with a lot of decisions, and he has to grow in order to say an even bigger good-bye than last time.
Interesting fact: PETA protested the movie because Bo Peep uses a shepherd's crook, and those are considered a "symbol of domination over animals."
Bo Peep was a pretty cool character in the movie. And she used her crook well.
The cast was amazing: besides the many who kept their roles (Tom Hanks, Tim Allen, Annie Potts, Joan Cusack, Timothy Dalton, even keeping Don Rickles from archive footage after his death, and everyone else) many new voices (Betty White, Mel Brooks, Christina Hendricks, Keanu Reeves, Bill Hader, Tony Hale, Key and Peele, and Flea from the Red Hot Chili Peppers).
The end of civilization?
This might be controversial with some of my friends, but no, there is no high likelihood of human civilization ending within the next 30 years.
Yes, climate change is happening, and we're obviously not reacting fast and effective enough. But that won't kill humanity, and it will not end civilization.
Some highly populated areas might become uninhabitable. No question about this. Whole countries in southern Asia, central and South America, in Africa, might become too hot and too humid or too dry for human living. This would lead to hundreds of millions, maybe billions of people, who will want to move, to save their lives and the lives of their loved ones. Many, many people would die in these migrations.
The migration pressures on the countries that are climatically better off may become enormous, and it will either lead to massive bloodshed or to enormous demographic changes, or, most likely, both.
But look at the map. There are large areas in northern Asia and North America that would dramatically improve their habitability for humans if they would warm a bit. Large areas could become viable for growing wheat, fruits, corn.
As it is already today, and as it was for most of human history, we produce enough food and clean water and shelter and energy for everyone. The problem is not production, it is and will always be distribution. Facing huge upheaval and massive migration the distribution channels will likely break down and become even more ineffective. The disruption of the distribution network will likely also endanger seemingly stable states, and places that thought to pass the events unscathed will be hurt by that breakdown. The fact that there would be enough food will make the humanitarian catastrophes even more maddening.
Money will make it possible to shelter away from the most severe effects, no matter where you start now. It's the poor that will bear the brunt of the negative effects. I don't think that's surprising to anyone.
But even if almost none of today's countries might survive as they are, and if a few billion people die, the chances of humanity to end, of civilization to end, are negligible. Billions will survive into the 21st century, and will carry on history.
So, yes, the changes might be massive and in some areas catastrophic. But humanity and civilization will preserve.
Why this post? I don't think it is responsible to exaggerate the bad predictions too much. It makes the predictions less believable. Also, to have a sober look at the possible changes may make it easier to understand why some countries react as they do. Does this mean we don't need to react and try to reduce climate change? If that's your conclusion, you haven't read carefully along. I said something about possibly billions becoming displaced.
Web Conference 2019
Last week saw the latest incarnation of the Web Conference (previously known as WWW or dubdubdub), going from May 15 to 17 (with satellite events the two days before). When I was still in academia, WWW was one of the most prestigious conference series for my research area, so when it came to be held literally across the street from my office, I couldn’t resist going to it.
The conference featured two keynotes (the third, by Lawrence Lessig, was cancelled on short notice due to a family emergency):
- Google’s Jeff Dean was giving a rather mind-blowing talk on the advances of machine learning in the last year or two, particularly focusing on medicine and auto-ML, but covering all kind of advances from chips, TPUs, programming frameworks, to use cases such as early detection of diabetes or cancer. (video)
- TED fellow Claire Wardle talked about the health of the information ecosystem on the Web (or, as I would put it, about fake news, and why that is a bad term), and it was refreshingly nuanced, thought-provoking, and lacking answers - but describing and circumscribing the problem much better than I have seen it before. (video)
Watch the talks on YouTube on the links given above. Thanks to Marco Neumann for pointing to the links!
The conference was attended by more than 1,400 people (closer to 1,600?), making it the second largest since its inception (trailing only Lyon from last year), and about double the size than it used to be only four or five years ago. The conference dinner in the Exploratorium was relaxed and enjoyable. Acceptance rate was at 18%, which made for 225 accepted full papers.
The proceedings are available for free (yay!), so browse them for papers you find interesting. Personally, I really enjoyed the papers that looked into the use of WhatsApp to spread misinformation before the Brazil election, Dataset Search, and pre-empting SPARQL queries from blocking the endpoint. The proceedings span 5,047 pages, and are available online.
I had the feeling that Machine Learning was taking much more space in the program than it used to when I used to attend the conference regularly - which is fine, but many of the ML papers were only tenuously connected to the Web (which was the same criticism that we raised against many of the Semantic Web / Description Logic papers back then).
Thanks to the general chairs for organizing the conference, Leila Zia and Ricardo Baeza-Yates, and thanks to the sponsors, particularly Microsoft, Bloomberg, Amazon, and Google.
The two workshops I attended before the Web Conference were the Knowledge Graph Technology and Applications 2019 workshop on Monday, and the Wiki workshop 2019 on Tuesday. They have their own trip reports.
If you have trip reports, let me know and I will link to them.
Wiki workshop 2019
Last week, May 14, saw the fifth incarnation of the Wiki workshop, co-located with the Web Conference (formerly known as dubdubdub), in San Francisco. The room was tight and very full - I am bad at estimating, but I guess 80-110 people were there.
I was honored to be invited to give the opening talk, and since I had a bit more time than in the last few talks, I really indulged in sketching out the proposal for the Abstract Wikipedia, providing plenty of figures and use cases. The response was phenomenal, and there were plenty of questions not only after the talk but also throughout the day and in the next few days. In fact, the Open Discussion slot was very much dominated by more questions about the proposal. I found that extremely encouraging. Some of the comments were immediately incorporated into a paper I am writing right now and that will be available for public reviews soon.
The other presentations - both the invited and the accepted ones - were super interesting.
- Timnit Gebru talked about the limitations of AI and when it can backfire
- Jure Leskovec spoke about their work on discovering hoaxes in Wikipedia automatically, and how bad humans are at this task (the algorithm detected 86% of hoaxes, humans 66% - random would be 50%)
- Neil Thompson gave a talk on how much Wikipedia shapes science, based on a super interesting experiment
- Erica Kochi talked about UNICEF’s innovation lab
Thanks to Dario Taraborelli, Bob West, and Miriam Redi for organizing the workshop.
A little extra was that I smuggled my brother and his wife into the workshop for my talk (they are visiting, and they have never been to one of my talks before). It was certainly interesting to hear their reactions afterwards - if you have non-academic relatives, you might underestimate how much they may enjoy such an event as mere spectators. I certainly did.
See also the #wikiworkshop2019 tag on Twitter.
Knowledge Graph Technology and Applications 2019
Last week, on May 13, the Knowledge Graph Technology and Applications workshop happened, co-located with the Web Conference 2019 (formerly known as WWW), in San Francisco. I was invited to give the opening talk, and talked about the limits of Knowledge Graph technologies when trying to express knowledge. The talk resonated well.
Just like in last week's KGC, the breadth of KG users is impressive: NASA uses KGs to support air traffic management, Uber talks about the potential for their massive virtual KG over 200,000 schemas, LinkedIn, Alibaba, IBM, Genentech, etc. I found particularly interesting that Microsoft has not one, but at least four large Knowledge Graphs: the generic Knowledge Graph Satori; an Academic Graph for science, papers, citations; the Enterprise Graph (mostly LinkedIn), with companies, positions, schools, employees and executives; and the Work graph about documents, conference rooms, meetings, etc. All in all, they boasted more than a trillion triples (why is it not a single graph? No idea).
Unlike last week, the focus was less on sharing experiences when working with Knowledge Graphs, but more on academic work, such as query answering, mixing embeddings with KGs, scaling, mapping ontologies, etc. Given that it is co-located with the Web Conference, this seems unsurprising.
One interesting point that was raised was the question of common sense: can we, and how can we use a knowledge graph to represent common sense? How can we say that a box of chocolate may fit in the trunk of a car, but a piano would not? Are KGs the right representation for that? The question remained unanswered, but lingered through the panel and some QnA sessions.
The workshop was very well visited - it got the second largest room of the day, and the room didn’t feel empty, but I have a hard time estimating how many people where there (about 100-150?). The audience was engaged.
The connection with the Web was often rather tenuous, unless one thinks of KGs as inherently associated with the Web (maybe because they often could use Semantic Web standards? But also often they don’t). On the other side it is a good outlet within the Web Conference for the Semantic Web crowd and to make them mingle more with the KG crowd, I did see a few people brought together into a room that often have been separated, and I was able to point a few academic researchers to enterprise employees that would benefit from each other.
Thanks to Ying Ding from the Indiana University and the other organizers for organizing the workshop, and for all the discussion and insights it generated!
Update: corrected that Uber talked about the potential of their knowledge graph, not about their realized knowledge graph. Thanks to Joshua Shivanier for the correction! Also added a paragraph on common sense.
Knowledge Graph Conference 2019, Day 1
On Tuesday, May 7, began the first Knowledge Graph Conference. Organized by François Scharffe and his colleagues at Columbia University, it was located in New York City. The conference goes for two days, and aims at a much more industry-oriented crowd than conferences such as ISWC. And it reflected very prominently in the speaker line-up: especially finance was very well represented (no surprise, with Wall Street being just downtown).
Speakers and participants from Goldman Sachs, Capital One, Wells Fargo, Mastercard, Bank of America, and others were in the room, but also from companies in other industries, such as Astra Zeneca, Amazon, Uber, or AirBnB. The speakers and participants were rather open about their work, often listing numbers of triples and entities (which really is a weird metric to cite, but since it is readily available it is often expected to be stated), and these were usually in the billions. More interesting than the sheer size of their respective KGs were their use cases, and particularly in finance it was often ensuring compliance to insider trading rules and similar regulations.
I presented Wikidata and the idea of an Abstract Wikipedia as going beyond what a Knowledge Graph can easily express. I had the feeling the presentation was well received - it was obvious that many people in the audience were already fully aware of Wikidata and are actively using it or planning to use it. For others, particularly the SPARQL endpoint with its powerful visualization capabilities and the federated queries, and the external identifiers in Wikidata, and the approach to references for the claims in Wikidata were perceived as highlights. The proposal of an Abstract Wikipedia was very warmly received, and it was the first time no one called it out as a crazy idea. I guess the audience was very friendly, despite New York's reputation.
A second set of speakers were offering technologies and services - and I guess I belong to this second set by speaking about Wikidata - and among them were people like Juan Sequeda of Capsenta, who gave an extremely engaging and well-substantiated talk on how to bridge the chasm towards more KG adoption; Pierre Haren of Causality Link, who offered an interesting personal history through KR land from LISP to Causal Graphs; Dieter Fensel of OnLim, who had a a number of really good points on the relation between intelligent assistants and their dialogue systems and KGs; Neo4J, Eccenca, Diffbot.
A highlight for me was the astute and frequent observation by a number of the speakers from the first set that the most challenging problems with Knowledge Graphs were rarely technical. I guess graph serving systems and cloud infrastructure have improved so much that we don't have to worry about these parts anymore unless you are doing crazy big graphs. The most frequently mentioned problems were social and organizational. Since Knowledge Graphs often pulled data sources from many different parts of an organization together, with a common semantics, they trigger feelings of territoriality. Who gets to define the common ontology? What if the data a team provides has problems or is used carelessly, who's at fault? What if others benefit from our data more than we did even though we put all the effort in to clean it up? How do we get recognized for our work? Organizational questions were often about a lack of understanding, especially among engineers, for fundamental Knowledge Graph principles, and a lack of enthusiasm in the management chain - especially when the costs are being estimated and the social problems mentioned before become apparent. One particularly visible moment was when Bethany Sehon from Capital One was asked about the major challenges to standardizing vocabularies - and her first answer was basically "egos".
All speakers talked about the huge benefits they reaped from using Knowledge Graphs (such as detecting likely cliques of potential insider trading that later indeed got convicted) - but then again, this is to be expected since conference participation is self-selecting, and we wouldn't hear of failures in such a setting.
I had a great day at the inaugural Knowledge Graph Conference, and am sad that I have to miss the second day. Thanks to François Scharffe for organizing the conference, and thanks to the sponsors, OntoText, Collibra, and TigerGraph.
For more, see:
Golden
I'd say that Golden might be the most interesting competitor to Wikipedia I've seen in a while (which really doesn't mean that much, it's just the others have been really terrible).
This one also has a few red flags:
- closed source, as far as I can tell
- aiming for ten billion topics in their first announcement, but lacking an article on Germany
- obviously not understanding what the point of notability policies are, and no, it is not about server space
They also have a features that, if they work, should be looked at and copied by Wikipedia - such as the editing assistants and some of the social features that are built-in into the platform.
Predictions:
- they will make a splash or two, and have corresponding news cycles to it
- they will, at some point, make an effort to import or transclude Wikipedia content
- they will never make a dent in Wikipedia readership, and will say that they wouldn't want to anyway because they love Wikipedia (which I believe)
- they will make a press release of donating all their content to Wikipedia (even though that's already possible thanks to their license)
- and then, being a for-profit company, they will pivot to something else within a year or two.
May 2019 talks
I am honored to give the following three invited talks in the next few weeks:
- Knowledge Graph Conference, Columbia University, New York, May 7, 2019
- Workshop on Knowledge Graph Technology and Applications, co-located with The Web Conference in San Francisco, May 13, 2019
- Wiki Workshop 2019, co-located with The Web Conference in San Francisco, May 14, 2019
The topics will all be on Wikidata, how the Wikipedias use it, and the Abstract Wikipedia idea.
AI and role playing
An article about AI and role playing games, and thus in the perfect intersection of my interest.
But the article is entirely devoid of any interesting content, and basically boils down to asking the question "could RPGs be a Turing test for AI?"
I mean, the answer is so painfully obviously "yes" that no one ever bothered to write it down. I mean, Turing wrote the test as a role playing game basically!
Papaphobia
In a little knowledge engineering exercise, I was trying to add the causes of a phobia to the respective Wikidata items. There are currently about 160 phobias in Wikidata, and only a few listed in a structured way what they are afraid of. So I was going through them, trying to capture it in s a structured way. Here's a list of the current state:
Now, one of those phobias was the Papaphobia - the fear of the pope. Now, is that really a thing? I don't know. CDC does not seem to have an entry on it. On the Web, in the meantime, some pages have obviously taken to mining lists of phobias and creating advertising pages that "help" you with Papaphobia - such as this one:
This page is likely entirely auto-generated. I doubt it that they have "clients for papaphobia in 70+ countries", whom they helped "in complete discretion" within a single day! "People with severe fears and phobias like papaphobia (which is in fact the formal diagnostic term for papaphobia) are held prisoners by their phobias."
This site offers more, uhm, useful information.
"Group psychotherapy can also help where individuals share their experience and, in the process, understand and recover from their phobia." Really? There are enough cases that we can even set up a group therapy?
Now, maybe I am entirely off here - maybe, papaphobia is really a thing. With search in Scholar I couldn't find any medical sources (the term is mentioned in a number of sociological and historical works, to express general sentiments in a population or government against the authority of the pope, but I could not find any mentions of it in actual medical literature).
Now could those pages up there be benign cases of jokes? Or are they trying to scam people with promises to heal their actual fears, and they just didn't curate the list of fears sufficiently, because, really, you wouldn't find this page unless you actually search for this term?
And now what? Now what if we know these pages are made by scammers? Do we report them to the police? Do we send a tip to journalists? Or should we just do nothing, allowing them to scam people with actual fears? Well, by publishing this text, maybe I'll get a few people warned, but it won't reach the people it has to reach at the right time, unfortunately.
Also, was it always so hard to figure out what is real and what is not? Does papaphobia exist? Such a simple question. How should we deal with it on Wikidata? How many cases are there, if it exists? Did it get worse for people with papaphobia now that we have two people living who have been made pope?
My assumption now is that someone was basically working on a corpus, looking for words ending in -phobia, in order to generate a list of phobias. And then the term papaphobia from sociological and historical literature popped up, and it landed in some list, and was repeated in other places, etc., also because it is kind of a funny idea, and so a mixture of bad research and joking bubbled through, and rolled around on the Web for so long that it looks like it is actually a thing, to the point that there are now organizations who will gladly take your money (CTRN is not the only one) to treat you for papaphobia.
The world is weird.
An indigenous library
Great story about an indigenous library using their own categorization system instead of the Dewey Decimal System (which really doesn't work for indigenous topics - I mean it doesn't really work for the modern world as well, but that's another story).
What I am wondering though if if they're not going far enough. Dewey's system is eventually rooted in Aristotelian logic and categorization - with a good dash of practical concerns of running a physical library.
Today, these practical concerns can be overcome, and it is unlikely that indigenous approaches to knowledge representation would be rooted in Aristotelian logic. Yes, having your own categorization system is a great first step - but that's like writing your own anthem following the logic of European hymns or creating your own flag following the weird rules of European medieval heraldry. How would it look like if you were really going back to the principles and roots of the people represented in these libraries? Which novel alternatives to representing and categorizing knowledge could we uncover?
Via Jens Ohlig.
How much information is in a language?
About the paper "Humans store about 1.5 megabytes of information during language acquisition“, by Francis Mollica and Steven T. Piantadosi.
This is one of those papers that I both love - I find the idea is really worthy of investigation, having an answer to this question would be useful, and the paper is very readable - and can't stand, because the assumptions in the papers are so unconvincing.
The claim is that a natural language can be encoded in ~1.5MB - a little bit more than a floppy disk. And the largest part of this is the lexical semantics (in fact, without the lexical semantics, the rest is less than 62kb, far less than a short novel or book).
They introduce two methods about estimating how many bytes we need to encode the lexical semantics:
Method 1: let's assume 40,000 words in a language (languages have more words, but the assumptions in the paper is about how many words one learns before turning 18, and for that 40,000 is probably an Ok estimation although likely on the lower end). If there are 40,000 words, there must be 40,000 meanings in our heads, and lexical semantics is the mapping of words to meanings, and there are only so many possible mappings, and choosing one of those mappings requires 553,809 bits. That's their lower estimate.
Wow. I don't even know where to begin in commenting on this. The assumption that all the meanings of words just float in our head until they are anchored by actual word forms is so naiv, it's almost cute. Yes, that is likely true for some words. Mother, Father, in the naive sense of a child. Red. Blue. Water. Hot. Sweet. But for a large number of word meanings I think it is safe to assume that without a language those word meanings wouldn't exist. We need language to construct these meanings in the first place, and then to fill them with life. You can't simply attach a word form to that meaning, as the meaning doesn't exist yet, breaking down the assumptions of this first method.
Method 2: let's assume all possible meanings occupy a vector space. Now the question becomes: how big is that vector space, how do we address a single point in that vector space? And then the number of addresses multiplied with how many bits you need for a single address results in how many bits you need to understand the semantics of a whole language. There lower bound is that there are 300 dimensions, the upper bound is 500 dimensions. Their lower bound is that you either have a dimension or not, i.e. that only a single bit per dimension is needed, their upper bound is that you need 2 bits per dimension, so you can grade each dimension a little. I have read quite a few papers with this approach to lexical semantics. For example it defines "girl" as +female, -adult, "boy" as -female,-adult, "bachelor" as +adult,-married, etc.
So they get to 40,000 words x 300 dimensions x 1 bit = 12,000,000 bits, or 1.5MB, as the lower bound of Method 2 (which they then take as the best estimate because it is between the estimate of Method 1 and the upper bound of Method 2), or 40,0000 words x 500 dimensions x 2 bits = 40,000,000 bits, or 8MB.
Again, wow. Never mind that there is no place to store the dimensions - what are they, what do they mean? - probably the assumption is that they are, like the meanings in Method 1, stored prelinguistically in our brains and just need to be linked in as dimensions. But also the idea that all meanings expressible in language can fit in this simple vector space. I find that theory surprising.
Again, this reads like a rant, but really, I thoroughly enjoyed this paper, even if I entirely disagree with it. I hope it will inspire other papers with alternative approaches towards estimating these numbers, and I'm very much looking forward to reading them.
- Humans store about 1.5MB of information during language acquisition, Royal Society Open Science
Milk consumption in China
Quiet disappointed by The Guardian. Here's a (rather) interesting article on the history of milk consumption in China. But the whole article is trying to paint how catastrophic this development might be: the Chinese are trying to triple their intake in milk! That means more cows! That's bad because cows fart us into a hot house!
The argumentation is solid - more cows are indeed problematic. But blaming it on milk consumption in China? Let's take a look at a few numbers omitted from the article, or stuffed into the very last paragraph.
- On average, a European consumes six times as much milk as a Chinese. So, even if China achieves its goal and triples average milk consumption, they will drink only half as much as a European.
- Europe has double the number of dairy cows than China has.
- China is planning to increase their milk output by 300% but only increase resources for that by 30% according to the article. I have no idea how that works, but sounds like a great deal to me.
- And why are we even talking about dairy cows? The number of beef cows in the US or in Europe each outnumber the dairy cows by a fair amount (unsurprisingly - a cow produces quite a lot of milk over a longer time, whereas its meat production is limited to a single event)
- There are about 13 million dairy cows in China. The US have more than 94 million cattle, Brazil has more than 211 million, world wide it's more than 1.4 billion - but hey, it's the Chinese milk cows that are the problem.
Maybe the problem can be located more firmly in the consumption habits of people in the US and in Europe than the "unquenchable thirst of China".
The article is still interesting for a number of other reasons.
Shazam!
Shazam! was fun. And had more heart than many other superhero stories. I liked that, for the first time, a DC universe movie felt like it's organically part of that universe - with all the backpacks with Batman and Superman logos and stuff. That was really neat.
Since I saw him in the first trailer I was looking forward to see Steve Carell playing the villain. Turns out it was Mark Strong, not Steve Carell. Ah well.
I am not sure the film knew exactly at whom it was marketed. The theater was full with kids, and given the trailers it was clear that the intention was to get as many families into it as possible. But the horror sequences, the graphic violence, the expletives, and the strip club scenes were not exactly for that audience. PG-13 is an appropriate rating.
It was a joy to watch the protagonist and his buddy explore and discover his powers. Colorful, lively, fun. Easily the best scenes of the movie.
The foster family drama gave the movie it's heart, but the movie seemed a bit overwhelmed by it. I wish that part was executed a bit better. But then again, it's a superhero movie, and given that it was far better than many of the other movies of its genre. But as far as High School and family drama superheroes go, it doesn't get anywhere near Spiderman: Homecoming.
Mid credit scenes. A tradition that Marvel started and that DC keeps copying - but unlike Marvel DC hasn't really paid up to the teasers in their scenes. And regarding cameos - also something where DC could learn so much from Marvel. Also, what's up with being afraid of naming their heroes? Be it in Man of Steel with Superman or here with Billy, the hero doesn't figure out his name (until the next movie comes along and everybody refers to him as Superman as if it was obvious all the time).
All in all, an enjoyable movie while waiting for Avengers: Endgame, and hopefully a sign that DC is finally getting on the right path.
EMWCon 2019, Day 2
Today was the second day of the Enterprise MediaWiki Conference, EMWCon, in Daly City at the Genesys headquarters.
The day started with my keynote on Wikidata and the Abstract Wikipedia idea. The idea was received very friendly.
Today, the day was filled with stories from people building systems on top of MediaWiki, and in particularly Semantic MediaWiki, Cargo, and some Wikibase. This included SFMoma presenting their system to collaboratively document art, using Cargo and Lua on the League of Legends wiki, running a whole wiki farm for Finnish memory and language institutions, the Lost Plays database, and - what I found particularly impressive - an engineer at NASA who implemented a workflow for document approval including authorization, audibality, and a full Web interface within a mere week, and still thinking that it could have been done much faster.
A common theme was "how incredibly easy it was". Yes, almost everyone mentioned something they got stumped on, and this really points to the community needing maybe more usage on StackOverflow or IRC or something, but in so many use cases, people who were not developers were able to create pretty complex workflows and apps right there in their browsers. This also ties in with the second common theme, that a lot of the deployments of such wikis are often starting "under the radar".
There were also genuinely complex solutions that were using Semantic MediaWiki as a mere component: Matteo Busanelli was presenting a solution that included lifting external data sources, deploying ontologies, reasoning, and all the whistles and bells - a very impressive and powerful architecture.
The US government uses Semantic MediaWiki in many places, most notably Intellipedia used by more than 16 intelligence agencies, Diplopedia by the Department of State, and Powerpedia for the Department of Energy. EPA's Statipedia is no more, but new wikis are popping up in other agency, such as WikITA for the International Trade Administration, and for the Nuclear Regulatory Commission. Canada's GCpedia was mentioned with a lot of respect, and the wish that the US would have something similar.
NASA has a whole wiki farm: within mission control alone they had 12 different wikis after a short while, many grown bottom up. They noticed that it would make sense to merge them together - which wasn't easy, neither technically nor legally nor managerially. They found that a lot of their knowledge was misclassified - for example, they classified handbooks which can be bought by anyone on Amazon. One of the biggest changes the wiki caused at NASA was that the merged ISS wiki lead to opening more knowledge to more people, and drawing the circles larger. 20% of the people who have access to the wikis actively contribute to the wikis! This is truly impressive.
So far, no edit has been made from space - due to technical issues. But they are working on it.
The day ended with a panel, asking the question where MediaWiki is in the marketplace, and how to grow.
Again, thanks to Yaron Koren and Cindy Cicalese for organizing the conference, and Genesys for hosting us. All presentations are available on YouTube.
EMWCon 2019, Day 1
Today was the first day of the Enterprise MediaWiki Conference, EMWCon, in Daly City. Among the attendees were people from NASA (6 or more people), UIC (International Union of Railways), the UK Ministry of Defence, the US radioactivity safety agencies, cancer research institutes, the Bureaus of Labour Statistics, PG&E, General Electric, and a number of companies providing services around MediaWiki, such as WikiTeq, Wikiworks, dokit, etc., with or without semantic extensions. The conference was located at the Headquarter of Genesys.
I'm not going to comment on all talks, and also I will not faithfully report on the talks - you can just go to YouTube to watch the talks themselves. The following is a personal, biased view of the first day.
NASA made an interesting comment early on: the discussion was about MediaWiki and its lack of fine-grained access control. You can set up a MediaWiki easily for a controlled group (so that not everyone in the world can access it), but it is not so easy to say "oh, this set of pages is available for people in this group, and managers in that org can access the pages with this markers", etc. So NASA, at first, set up a lot of wiki installations, each one for such specific groups - but eventually turned it all around and instead had a small number of well-defined groups and merged the wikis into them, tearing down barriers within the org and making knowledge wider available.
Evita Hollis from General Electric had an interesting point in her presentation on how GE does knowledge sharing: they use SharePoint and Yammer to connect people to people, and MediaWiki to connect people to Knowledge. MediaWiki has been not-exactly-great at allowing people to work together in real-time - it is a different flow, where you capture and massage knowledge slowly into it. There is a reason why Ops at Wikimedia do not use a wiki during an incident that much, but rather IRC. I think there is a lot of insight in her argument - and if we take that serious, we could actually really lift MediaWiki to a new level, and take Wikipedia there too.
Another interesting point is that SharePoint at General Electric had three developers, and MediaWiki had one. The question from the audience was, whether that reflect how difficult it is to work with SharePoint, or whether that reflected some bias of the company towards SharePoint. Hollis was adamant about how much she likes Sharepoint, but the reason for the imbalance was that MediaWiki, particularly Semantic MediaWiki, allows actually much more flexibility and power than SharePoint without having to touch a single line of wiki source code. It is a platform that allows for rapid experimentation by the end user (I am adding the Spiderman adage about great power coming with great responsibility).
Daren Welsh from NASA talked about many different forms of biases and how they can bubble up on your wiki. Very interesting was one effect: if knowledge from the wiki is becoming too readily availble, people may start to become dependent on it. They had tests where they took away the wiki randomly from flight controllers in training, in order to ensure they are resourceful enough to still figure out what to do - and some failed miserably.
Ike Hecht had a brilliant presentation on the kind of quick application development Semantic MediaWiki lends itself to. He presented a task manager, a news feed, and a file management system, calling them "Semantic Structures That Do Stuff" - which is basically a few pages for your wiki, instead of creating extensions for all of these. This also resonated with GE's statement about needling less developers. I think that this is wildly underutilized and there is a lot of value in this idea.
Thanks to Yaron Koren - who also gave an intro to the topic - and Cindy Cicalese for organizing the conference, and Genesys for hosting us. All presentations are available on YouTube.
EMWCon Spring 2019
I'm honored to be invited to keynote the Enterprise MediaWiki conference in Daly City. The keynote is on Thursday, I will talk about Wikidata and beyond - towards an abstract Wikipedia.
The talk is planned to be recorded, so it should be available afterwards for everyone interested.
Turing Award to Bengio, LeCun, and Hinton
Congratulations to Yoshua Bengio, Yann LeCun, and Geoffrey Hinton on being awarded the Turing Award, the most prestigious award in Computer Science.
Their work had revolutionized huge parts of computer science as it is used in research and industry, and has lead to the current impressive results in AI and ML. They were continuing to work on an area that was deemed unpromising, and has suddenly swept through whole industries and reshaped them.
Something Positive in Deutsch wieder online
2005 und 2006 übersetzten Ralf Baumgartner und ich die ersten paar Something Positive comics von R. K. Milholland ins Deutsche. Die 80 Comics, die wir damals übersetzt haben, sind hiermit wieder online. Wir haben noch vier weitere Comics übersetzt, die in den nächsten Tagen auch nach und nach online kommen werden.
Viel Spass! Oh, und die Comics sind für Erwachsene.
DSA Erfolgswahrscheinlichkeiten
Ich fand es immer spannend, auszurechnen, wie hoch die Wahrscheinlichkeit ist, dass eine Talentprobe in DSA gelingt oder nicht. Ich konnte über die Jahre hinweg keine vernünftige, geschlossene Formel finden, und so blieb ich immer bei Überschlagsrechnungen. Dabei visualisierte ich mir im Kopf die drei Würfelwürfe als die drei Dimensionen eines Raumes, in dem ein Teil des Raumes gelungene Proben und der Rest des Raumes misslungene Proben darstellt.
Ich dachte lange darüber nach, dass es interessant ware, diesen Raum tatsächlich zu visualisieren. 2010 musste ich während eines Forschungsaufenthalts in Los Angeles ein paar Webtechniken erlernen - HTML Canvas, jQuery, Blueprint, etc. - und am besten lerne ich, indem ich ein kleines Projekt mache. Also nutzte ich diese Gelegenheit. Damals war DSA4 aktuell, und entsprechend machte ich das Projekt für die Regeln von DSA4.
2017 überarbeitete Hanno Müller-Kalthoff die Visualisierung und passte sie an die neuen Regeln von DSA5 an. Hier sind Links für beide Seiten und eine DSA5 App:
- Erfolgswahrscheinlichkeit bei DSA4 Talentproben
- Erfolgswahrscheinlichkeit bei DSA5 Talentproben
- Android App für DSA5 Wahrscheinlichkeiten
A bitter, better lesson
Rich Sutton is expressing some frustration in his short essay on computation and simple methods beating smart methods again and again.
Rodney Brooks answers with great arguments on why this is not really the case, and how we're just hiding human ingenuity and smartness better.
They're both mostly right, and it was interesting to read the arguments on both sides. And yet, not really new - it's mostly rehashing the arguments from The unreasonable effectiveness of data by Alon Halevy, Peter Norvig, and Fernando Pereira ten years ago. But nicely updated and much shorter. So worth a read!
Wikipedia demonstriert
Eine Reihe von Wikipedien (Deutsch, Dänisch, Estnisch, Tschechisch) tragen heute schwarz um schlecht gemachte Gesetzesänderungen zu verhindern. Ich bin stolz auf die Freiwilligen der Wikipedien, die das organisiert bekommen haben.
Spring cleaning
Going through my old online presence and cleaning it up is really a trip down memory lane. I am also happy that most - although not all - of the old demos still work. This is going to be fun to release it all again.
Today I discovered that we had four more German translations of Something Positive that we never published. So that's another thing that I am going to publish soon, yay!
Prediction coming true
I saw my post from seven years ago, where I said that I really like Facebook and Google+, but I want a space where I have more control about my content so it doesn't just disappear. "Facebook and Google+ -- maybe they won't disappear in a year. But what about ten?"
And there we go, Google+ is closing in a few days.
I downloaded my data from there (as well as my data from Facebook and Twitter), to see if there is anything to be salvaged from that, but I doubt it.
Restarting, 2019 edition
I had neglected Simia for too long - there were five entries in the last decade. A combination of events lead me to pour some effort back into it - and so I want to use this chance to restart it, once again.
Until this weekend, Simia was still running on a 2007 version of Semantic MediaWiki and MediaWiki - which probably helped with Simia getting hacked a year or two ago. Now it is up to date with a current version, and I am trying to consolidate what is already there with some content I had created in other places.
Also, life has been happening. If you have been following me on Facebook (that link only works if you're logged in), you have probably seen some of that. I married, got a child, changed jobs, and moved. I will certainly catch up on this too, but there is no point in doing that all in one huge mega-post. Given that I am thinking about starting a new project just these days, this might be the perfect outlet to accompany that.
I make no promises with regards to the quality of Simia, or the frequency of entries. What I would really love recreate would be a space that is as interesting and fun for as my Facebook wall was, before I stopped engaging there earlier this year - but since you cannot even create comments here, I have to figure out how to make this even remotely possible. For now, suggestions on Twitter or Facebook are welcome. And no, moving to WordPress or another platform is hardly an option, as I really want to stay with Semantic MediaWiki - but pointers to interesting MediaWiki extensions are definitely welcome!
Stars in our eyes
I grew up in a suburban, almost rural area in southern Germany, and I remember the hundreds, if not thousands of stars I could see at night. In the summers, that I spent on an island in Croatia, it was even more marvelous, and the dark night sky was breathtaking.
As I grew up, the stars dimmed, and I saw fewer and fewer of those, until only the brightest stars were visible. It was blindingly obvious that air and light pollution have swallowed that every-night miracle and confined it to my memory only.
Until in my late twenties I finally accepted and got glasses. Now the stars are back, as beautiful and brilliant as they have ever been.
Croatian Elections 2016
Croatian elections are upcoming.
The number of Croatians living abroad - in the so called Croatian diaspora - is estimated to be almost 4 Million according to the Croatian state office for Croatians abroad - only little less than the 4.3 Million who live in Croatia. The estimates vary wildly, and most of them actually do not have Croatian citizenship. But it is estimated that between 9-10% of holders of the Croatian citizenship live abroad.
These 9-10% are represented in the Croatian parliament: out of the 151 Members of Parliament, there are 3 (three) voted by the diaspora. That's 2% of the parliament representing 10% of the population.
In order for a member of the diaspora to vote, they have to register well before the election with their nearest diplomatic mission or consulate. The registration deadline is today, at least for my consulate. But for the election itself, you have to personally appear and vote at the consulate. For me, that would mean to drive or fly all the way to Los Angeles from San Francisco. And I am rather close to one of the 9 consulates in the US. There are countries that do not have Croatian embassies at all. Want to vote? Better apply for a travel visa to the country with the next embassy. Live in Nigeria? Have a trip to Libya or South Africa. There is no way to vote per mail or - ohwow21stcentury? - electronically. For one of the three Members of Parliament that represent us.
I don't really feel like the parliament wants us to vote. Making the vote mean so little and making it so hard to vote.
Gödel and physics
"A logical paradox at the heart of mathematics and computer science turns out to have implications for the real world, making a basic question about matter fundamentally unanswerable."
I just love this sentence, published in "Nature". It raises (and somehow exposes the author's intuition about) one of the deepest questions in science: how are mathematics, logic, computer science, i.e. the formal sciences, on the one side, and the "real world" on the other side, related? What is the connection between math and reality? The author seems genuinely surprised that logic has "implications for the real world" (never mind that "implication" is a logical term), and seems to struggle with the idea that a counter-intuitive theorem by Gödel, which has been studied and scrutinized for 85 years, would also apply to equations in physics.
Unfortunately the fundamental question does not really get tackled: the work described here, as fascinating as it is, was an intentional, many year effort to find a place in the mathematical models used in physics where Gödel can be applied. They are not really discussing the relation between maths and reality, but between pure mathematics and mathematics applied in physics. The original deep question remains unsolved and will befuddle students of math and the natural sciences for the next coming years, and probably decades (besides Stephen Wolfram, who beieves to have it all solved in NKS, but that's another story).
Nature: Paradox at the heart of mathematics makes physics problem unanswerable
Phys.org: Quantum physics problem proved unsolvable: Godel and Turing enter quantum physics
AI is coming, and it will be boring
I was asked about my opinion on this topic, and I thought I would have some profound thoughts on this. But I ended up rambling, and this post doesn’t really make any single strong point. tl;dr: Don’t worry about AI killing all humans. It’s not likely to happen.
In an interview with the BBC, Stephen Hawking stated that “the development of full artificial intelligence could spell the end of the human race”. Whereas this is hard to deny, it is rather trivial: any sufficiently powerful tool could potentially spell the end of the human race given a person who knows how to use that tool in order to achieve such a goal. There are far more dangerous developments - for example, global climate change, the arsenal of nuclear weapons, or an economic system that continues to sharpen inequality and social tension?
AI will be a very powerful tool. Like every powerful tool, it will be highly disruptive. Jobs and whole industries will be destroyed, and a few others will be created. Just as electricity, the car, penicillin, or the internet, AI will profoundly change your everyday life, the global economy, and everything in between. If you want to discuss consequences of AI, here are a few that are more realistic than human extermination: what will happen if AI makes many jobs obsolete? How do we ensure that AIs make choices compliant with our ethical understanding? How to define the idea of privacy in a world where your car is observing you? What does it mean to be human if your toaster is more intelligent than you?
The development of AI will be gradual, and so will the changes in our lifes. And as AI keeps developing, things once considered magical will become boring. A watch you could talk to was powered by magic in Disney’s 1991 classic “The Beauty and the Beast”, and 23 years later you can buy one for less than a hundred dollars. A self-driving car was the protagonist of the 80s TV show “Knight Rider”, and thirty years later they are driving on the streets of California. A system that checks if a bird is in a picture was considered a five-year research task in September 2014, and less than two months later Google announces a system that can provide captions for pictures - including birds. And these things will become boring in a few years, if not months. We will have to remind ourselves how awesome it is to have a computer in our pocket that is more powerful than the one that got Apollo to the moon and back. That we can make a video of our children playing and send it instantaneously to our parents on another continent. That we can search for any text in almost any book ever written. Technology is like that. What’s exciting today, will become boring tomorrow. So will AI.
In the next few years, you will have access to systems that will gradually become capable to answer more and more of your questions. That will offer advice and guidance towards helping you navigate your life towards the goal you tell it. That will be able to sift through text and data and start to draw novel conclusions. They will become increasingly intelligent. And there are two major scenarios that people are afraid of at this point:
- That the system will become conscious and develop their own intentions and their own will, and they will want to destroy humanity: the Skynet scenario from the Terminator movies.
- That the system might get a task, and figure out a novel solution for the task which unfortunately wipes out humanity. This is the paperclip scenario— an AI gets the task to create paperclips, and kills all humans by doing so — , which has not yet been turned into a blockbuster.
The Skynet scenario is just mythos. There is no indication that raw intelligence is sufficient to create intrinsic intention or will.
The paperclip scenario is more realistic. And once we get closer to systems with such power, we will need to put the right safeguards in place. The good news is that we will have plenty of AIs at our disposal to help us with that. The bad news is that discussing such scenarios now is premature: we simply don’t know how these systems will look like. That’s like starting a committee a hundred years ago to discuss the danger coming from novel weaponry: no one in 1914 could have predicted nuclear weapons and their risks. It is unlikely that the results of such a committee would have provided much relevant ethical guidance for the Manhattan project three decades later. Why should that be any different today?
In summary: there are plenty of consequences of the development of AI that warrant intensive discussion (economical consequences, ethical decisions made by AIs, etc.), but it is unlikely that they will bring the end of humanity.
Further reading
- Jaron Lanier on the dangers of the Myth of AI, with answers from Steven Pinker, George Dyson, Stuart Russel, Rodney Brooks and others
- Elon Musk warns about AI (Guardian article)
- Bill Joy on why the future does not need us
- Oren Etzioni on why he is not afraid of AI
- Ethics of AI on Wikipedia
Published originally on Medium on December 14, 2014
Start the website again
This is no blog anymore. I haven't had entries for years, and even before then sporadically. This is a wiki, but somehow it is not that either. Currently you cannot make comments. Updating the software is a pain in the ass. But I like to have a site where I can publish again. Switch to another CMS? Maybe one day. But I like Semantic MediaWiki. So what will I do? I do not know. But I know I will slowly refresh this page again. Somehow.
A new part of my life is starting soon. And I want to have a platform to talk about it. And as much as I like Facebook or Google+, I like to have some form of control over this platform. Facebook and Google+ -- maybe they won't disappear in a year. But what about ten? Twenty? Fifty years? I'll still be around (I hope), but they might not...
Let's see what will happen here. For now, I republished the retelling of a day as a story I first published on Google+ (My day in Jerusalem) and a poem that feels eerily relevant whenever I think about it (Wenn ich wollte)
Popculture in logics
- You ⊑ ∀need.Love (Lennon, 1967)
- ⊥ ≣ compare.You (Nelson, 1985)
- Cowboy ⊑ ∃sing.SadSadSong (Michaels, 1988)
- ∀t : I ⊑ love.You (Parton, 1973)
- ∄better.Time ⊓ ∄better⁻¹.Time (Dickens, 1859)
- {god} ⊑ Human ⊨ ? (Bazilian, 1995)
- Bad(X)? (Jackson, 1987)
- ⃟(You ⊑ save.I) (Gallagher, 1995)
- Dreamer(i). ∃x : Dreamer(x) ∧ (x ≠ i). ⃟ ∃t: Dreamer(you). (Lennon, 1971)
- Spoon ⊑ ⊥ (Wachowski, 1999)
- ¬Cry ← ¬Woman (Marley, 1974)
- ∄t (Poe, 1845)
Solutions: Turn around your monitor to read them.
sǝlʇɐǝq ǝɥʇ 'ǝʌol sı pǝǝu noʎ llɐ ˙ǝuo
ǝɔuıɹd ʎq ʎllɐuıƃıɹo sɐʍ ʇı 'ƃuos ǝɥʇ pǝɹǝʌoɔ ʇsnɾ pɐǝuıs ˙noʎ oʇ sǝɹɐdɯoɔ ƃuıɥʇou ˙oʍʇ
˙uosıod ʎq uɹoɥʇ sʇı sɐɥ ǝsoɹ ʎɹǝʌǝ ɯoɹɟ '"ƃuos pɐs pɐs ɐ sƃuıs ʎoqʍoɔ ʎɹǝʌǝ" ˙ǝǝɹɥʇ
ʞɔɐɹʇpunos ǝıʌoɯ pɹɐnƃʎpoq ǝɥʇ ɹoɟ uoʇsnoɥ ʎǝuʇıɥʍ ʎq ɹɐlndod ǝpɐɯ ʇnq uoʇɹɐd ʎllop ʎq ʎllɐuıƃıɹo 'noʎ ǝʌol sʎɐʍlɐ llıʍ ı 'ɹo - ",noʎ, ɟo ǝɔuɐʇsuı uɐ ɥʇıʍ pǝllıɟ ,ǝʌol, ʎʇɹǝdoɹd ɐ ƃuıʌɐɥ" uoıʇdıɹɔsǝp ǝɥʇ ʎq pǝɯnsqns ɯɐ ı 'ʇ sǝɯıʇ llɐ ɹoɟ ˙ɹnoɟ
suǝʞɔıp sǝlɹɐɥɔ ʎq sǝıʇıɔ oʍʇ ɟo ǝlɐʇ ɯoɹɟ sǝɔuǝʇuǝs ƃuıuǝdo ǝɥʇ sı sıɥʇ ˙(ʎʇɹǝdoɹd ǝɥʇ ɟo ǝsɹǝʌuı suɐǝɯ 1- ɟo ɹǝʍod" ǝɥʇ) ǝɯıʇ ɟo ʇsɹoʍ ǝɥʇ sɐʍ ʇı ˙sǝɯıʇ ɟo ʇsǝq ǝɥʇ sɐʍ ʇı ˙ǝʌıɟ
(poƃ)ɟoǝuo ƃuıɯnsqns sn ʎq pǝlıɐʇuǝ sı ʇɐɥʍ sʞsɐ ʇı ʎllɐɔısɐq ˙ʇıɥ ɹǝpuoʍ ʇıɥ ǝuo 5991 ǝɥʇ 'sn ɟo ǝuo sɐʍ poƃ ɟı ʇɐɥʍ ˙xıs
pɐq ǝlƃuıs ʇıɥ ǝɥʇ uı "pɐq s,oɥʍ" ƃuıʞsɐ 'uosʞɔɐɾ lǝɐɥɔıɯ ˙uǝʌǝs
ɔıƃol lɐpoɯ ɯoɹɟ ɹoʇɐɹǝdo ʎılıqıssod ǝɥʇ sı puoɯɐıp ǝɥʇ ˙"ǝɯ ǝʌɐs oʇ ǝuo ǝɥʇ ǝɹ,noʎ ǝqʎɐɯ" ǝuıl ǝɥʇ sɐɥ ʇı ˙sısɐo ʎq 'llɐʍɹǝpuoʍ ˙ʇɥƃıǝ
˙ooʇ ǝuo ǝɹɐ noʎ ǝɹǝɥʍ ǝɯıʇ ɐ sı ǝɹǝɥʇ ǝqʎɐɯ puɐ ˙(ǝɯ ʇou ǝɹɐ sɹǝɥʇo ǝsoɥʇ puɐ 'sɹǝɯɐǝɹp ɹǝɥʇo ǝɹɐ ǝɹǝɥʇ) ǝuo ʎluo ǝɥʇ ʇou ɯɐ ı ʇnq ˙ɹǝɯɐǝɹp ɐ ɯɐ ı" ˙ǝuıƃɐɯı 'uıɐƃɐ uouuǝl uɥoɾ ˙ǝuıu
(ǝlɔɐɹo ǝɥʇ sʇǝǝɯ ǝɥ ǝɹoɟǝq ʇsnɾ oǝu oʇ ƃuıʞɐǝds pıʞ oɥɔʎsd ǝɥʇ) xıɹʇɐɯ ǝıʌoɯ ǝɥʇ ɯoɹɟ ǝʇonb ssɐlɔ ˙uoods ou sı ǝɹǝɥʇ ˙uǝʇ
ʎǝuoɯ ǝɯos sʇǝƃ puǝıɹɟ sıɥ os ƃuıʎl ʎlqɐqoɹd sɐʍ ǝɥ ʇnq 'puǝıɹɟ ɐ oʇ sɔıɹʎl ǝɥʇ pǝʇnqıɹʇʇɐ ʎǝlɹɐɯ ˙"ʎɹɔ ʇou" sʍolloɟ "uɐɯoʍ ʇou" ɯoɹɟ ˙uǝʌǝlǝ
ǝod uɐllɐ ɹɐƃpǝ ʎq '"uǝʌɐɹ ǝɥʇ" ɯoɹɟ ɥʇonb ˙ǝɹoɯɹǝʌǝu :ɹo ˙ǝɯıʇ ou sı ǝɹǝɥʇ ˙ǝʌlǝʍʇ
My horoscope for today
Here's my horoscope for today:
You may be overly concerned with how your current job prevents you from reaching your long-term goals. The Sun's entry into your 9th House of Big Ideas can work against your efficiency by distracting you with philosophical discussions about the purpose of life. These conversations may be fun, but they should be kept to a minimum until you finish your work.
How the heck did they know??
England eagerly lacking cofidence
My Google Alerts just send me the following news alert about Croatia. At least the reporters checked all their sources :)
England players lacking confidence against Croatia International Herald Tribune - France AP ZAGREB, Croatia: England's players confessed to a lack of confidence when they took on football's No. 186-ranked nation in their opening World Cup ...
England eager to break Croatia run Reuters UK - UK By Igor Ilic ZAGREB (Reuters) - England hope to put behind their gloomy recent experiences against Croatia when they travel to Zagreb on Wednesday for an ...
Beating the Second Law
Yihon Ding has an interesting blogpost taking analogies to the laws of thermodynamics and why this means trouble for the Semantic Web.
I disagree in one aspect: I think it is possible to invest the amount of human power to the system and to still keep it going. I can't nail it down exactly -- I didn't read "Programming the Universe" yet, so I can't really discuss it, but the feeling goes along the following lines: the value of a network increases superlinearly, if not even quadratic (Metcalfe's Law), whereas the amount of information increases sublinearly (due to redundancies in human knowledge). Or, put it in another way: get more people and Wikipedia or Linux gets better, because they have a constrained scope. The more you constrain the scope the more value is added by more people.
This is an oversimplification.
Blogging from an E90
After pondering it for far too long, I finally got a new mobile phone: a Nokia E90. It is pretty big and heavy, but I don't mind really. I am looking at it as a light-weight laptop replacement. But I am not sure I will learn to love the keyboard, really. Experimenting.
But since it has a full keyboard, programming in Python is indeed an option. I had Python on my previous phone too, but heck, T9 is not cool to type code.
One world. One web.
I am in Beijing at the opening of the WWW2008 conference. Like all WWWs I was before, it is amazing. The opening ceremony was preceded by a beautiful dance, combining tons of symbols. First a woman in a traditional Chinese dress, then eight dancers in astronaut uniforms, a big red flag with "Welcome to Beijing" on it (but not on the other side, when he came back), and then all of them together... beautiful.
Boris Motik's paper is a best paper candidate! Yay! Congratulations.
I rather listen to the keynote now :)
Blogging from my XO One.
Certificate of Coolness
Now that the Cool URIs for the Semantic Web note by Richard and Leo have been published -- congratulation guys! -- I am sure looking forward if anyone will create a nice badge and a procedure to get official Certificates of Coolness. Pretty please?
On a different note: I know, I should have blogged from New Zealand. It sure was beautiful Maybe I will still blog about it a bit later. My sister has blogged extensively, and also made a few great pictures, take a look over there if you're interested.
Coming to New Zealand
Yes! Three weeks of vacation in New Zealand, which is rumoured to be quite a beauty. This also means: three weeks no work, no projects, no thesis, no Semantic We...
Oh, almost. Actually I will enjoy to have the opportunity to give a talk on Semantic Wikipedia while staying in Auckland. If you're around, you may want to come by.
It is on February 22nd, 1pm-2pm at the AUT. You may want to tell Dave Parry that you're coming, he is my host.
Looking forward to this trip a lot!
Charlie Wilson's War
Ein einfacher Kongressmann (Tom Hanks). Eine sehr rechte reiche Texanering (Julia Roberts). Ein äußerst guter CIA Agent (Philip Seymour Hoffman). Und Sowjets die in Afghanistan einmarschieren, im Kalten Krieg. Amerika muss sich wehren, auch am Hindukusch!
Der Film behandelt den afghanischen Krieg (den aus den 1980er Jahren), und es geht um sehr ernste Themen. Zudem beruht er auf wahren Ereignissen. Dennoch verpackt er es in abstrusen Witz, liefert uns charmante Antihelden, und deutet schließlich auch an, wie es zum nächsten Afghanistankrieg kommen konnte (den aus den 2000er Jahren), doch ist das kaum das Thema in diesem Film.
Wie bereits Hunting Party ein Film, der doch sensibel mit jenen Wahrheiten umgeht, für die er eintritt, und mit umso derberen Humor und Aufklärung die Missstände anprangert. Ein besonderer Spagat gelingt dem Film da er die Aufteilung des politischen Spektrums in rechts und links nicht einfach mit Böse und Gut gleichsetzt, wie es etwa Michael Moore gerne macht, sondern ähnlich wie Team America nach beiden Seiten austeilt -- Lob, wie auch Kritik.
Wir sahen den Film gestern in der Sneak, leider in der Originalversion -- insbesondere die Texanischen Dialekte waren echt schwer zu verstehen, weswegen wohl der eine oder andere Gag verloren ging. Ich hoffe ihn dann auch in der deutschen Synchro zu sehen.
Charlie Wilson's War (Der Krieg des Charlie Wilson) läuft in Deutschland am 7. Februar 2008 in den Kinos an.
Bewertung: 4 von 5
7 Jahre
Heute sind es genau sieben Jahre, dass ich diese Website eröffnet habe. Und heute wird sie umbenannt! In den letzten Wochen stellte ich die Software vollständig auf Semantic MediaWiki um, welches es mir deutlich einfacher erlaubt, die Seite zu pflegen als jemals zuvor.
In den nächsten Wochen will ich langsam, aber sicher, die alten Inhalte, die seit einem Hacker-Angriff auf Nodix verschwunden sind, wieder hochladen.
Eine wichtige Änderung gibt es freilich (nicht die Hintergrundfarbe, die ist geblieben): der Name der Website wurde geändert. Kein Nodix mehr, ab jetzt heißt die Seite Simia. Und ihr werdet merken, viele der Seiten sind Englisch, andere Deutsch. Einfach auch, weil inzwischen vieles von dem was ich mache, Englisch ist. Ich hoffe, dass das nicht abschreckt. Es sind ja dennoch noch viele Deutschsprachige Inhalte vorhanden.
Und was leider noch nicht funktioniert, ist das Kommentieren, sorry. Das heißt, vorübergehend ist das nur per Email möglich. Ich arbeite dran.
Kindheitsträume wahr werden lassen
Randy Pausch ist Professor für User Interfaces and der CMU, einer der bekanntesten Universitäten der USA. Im September 2006 wurde bei ihm Bauchspeicheldrüsenkrebs diagnostiziert. Seitdem kämpft er um jeden Tag.
In der Vortragsreihe Journeys (Reisen) der CMU, welche Randy mit seinem Vortrag eröffnete, sollen die Vortragenden sich überlegen, was sie den Zuhörern sagen würden, wenn dies ihre letzte Gelegenheit für einen Vortrag wäre. Ihr Erbe, sozusagen.
Der Vortrag -- auch wenn er knappe anderthalb Stunden dauert -- stellt flott und unterhaltend Randys Kindheitsträume vor, und wie sie wahr geworden sind, oder nicht. Er erzählt viele Anekdoten, und fasst wichtige Weisheiten zusammen.
Das Video des Vortrags, mit Untertiteln in Deutsch oder Englisch, ist bei Google Video erhältlich. Sehenswert.
Darjeeling Limited
Wunderschöner Film. Auch wenn der Sympatexter offenbar nicht allzu begeistert war, mir gefiel er sehr. Wem Wes Andersons andere Filme gefallen haben (insbesondere The Royal Tenenbaums und The Life Aquatic with Steve Zissou), der wird sich auch an Darjeling Limited sehr freuen.
Der Film ist farbenfroh, hat einen witzigen Soundtrack, unzählige skurrile Situationen, und hin und wieder auch sehr tiefer Stoff zum Nachdenken. Anderson setzt seine Schauspieler hervorragend in Szene, verzaubert mit den wunderbaren Macken der drei Brüder, und lässt einen mit der Gewissheit wieder aus dem Kino gehen, dass die eigene Familie gar nicht so verrückt ist, wie man immer angenommen hat. Die drei Brüder auf dem Weg durch Indien können erst sich selbst finden, wenn sie zueinander gefunden haben -- und das ist erst möglich, nachdem sie mit dem Gesicht nach vorne auf ein echtes Schicksal treffen.
Bewertung: 5 von 5
Social Web and Knowledge Management
Obviously, the social web is coming. And it's also coming to this year's WWW conference in Beijing!
I find this topic very interesting. The SWKM picks up the theme of last year's very successful CKC2007 workshop, also at the WWW, where we aimed at allowing the collaborative knowledge construction. The SWKM is a bit broader, since it is not just about knowledge construction, but about the whole topic of knowledge management, and how the web changes everything.
If you are interested in the social web, or the semantic web, or specifically about the intersection of these two, and how it can be applied for knowledge management within or without an organisation, you will like the SWKM workshop at the WWW2008. You can submit papers until January 21st, 2008. All information can be found at the Social Web and Knowledge management workshop website.
Semantic MediaWiki 1.0 released
After about two years of development and already with installations all over the world, we are very happy to announce the release of Version 1.0 of Semantic MediaWiki, and thus the first stable version. No alpha, no beta, it's out now, and we think you can use it productively. Markus managed to release it in 2007 (on the last day of the year), and it has moved far beyond what 0.7 was, in stability, features, and performance. The biggest change is a completely new ask syntax, much more powerful since it works much smoother with MediaWiki's other systems like the parser functions, and we keep constantly baffling ourselves about what is possible with the new system.
We have finally reached a point where we can say, OK, let's go for massive user testing. We want big and heavy used installations to test our system. We are fully aware that the full power of the queries can easily kill an installation, but there are many ways to tweak performance and expressivity. We are now highly interested in performance reports, and then moving towards our actual goal, Wikipedia.
A lot has changed. You can find a full list of changes in the release notes. And you can download and install Semantic MediaWiki form SourceForge. Spread the word!
There remains still a lot of things to do. We have plenty of ideas how to make it more useful, and our users and co-developers also seem to have plenty of ideas. It is great fun to see the numbers of contributors to the code increase, and also to see the mailing lists being very lively. Personally, I am very happy to see Semantic MediaWiki flourish as it does, and I am thankful to Markus for starting this year (or rather ending the last) with such a great step.
Willkommen auf Simia
Willkommen auf Simia, der neuen Website von Denny Vrandecic. Nachdem ich in meinem Blog seit gefühlten drei Zeitaltern nix mehr geschrieben habe, und auf meinen Seiten seit Anbeginn der Zeiten keine neuen Inhalte eingestellt habe, kann ich euch jetzt sagen, es lag daran, dass ich die ganze Technik umstellen wollte.
Womit ich endlich gut vorangekommen bin. Zur Zeit finden sich hier alle Blogeinträge von Nodix und die Kommentare. Die Funktion zum Erstellen neuer Kommentare funktioniert noch nicht, aber ich arbeite daran. Ihr werdet auch merken, dass deutlich mehr Inhalte auf der Seite in Englisch sind als früher.
Technisch gesehen ist Simia eine Semantic MediaWiki Installation. Damit gehört dieser Blog auch zu meiner Forschung, indem ich ein wenig Erfahrung aus erster Hand sammeln möchte, wie es ist, sein Blog und seine persönliche Homepage mit Semantic MediaWiki zu führen. (Insofern ist das natürlich kein Blog mehr, sondern ein so genanntes Bliki, aber wen schert's?). Und da das ganze semantisch ist, will ich herausfinden, wie so eine persönliche Website ins Semantic Web passt...
Um Up to date zu bleiben, gibt es eine Reihe von feeds auf Simia. Wählt Euch aus, was ihr wollt. Schöne Grüße, und ich hoffe, Ihr habt Euch gut durch die Weihnachtszeit gemampft! :)
San Francisco and Challenges
Time is running totally crazy on me in the last few weeks. Right now I am in San Francisco -- if you like to suggest a meeting, drop me a line.
The CKC Challenge is going on and well! If you didn't have the time yet, check it out! Everybody is speaking about how to foster communities for shared knowledge building, this challenge is actually doing it, and we hope to get some good numbers and figures out of it. An fun -- there is a mystery prize involved! Hope to see as many of you as possible at the CKC 2007 in a few days!
Yet another challenge with prizes is going on at Centiare. Believe it or not, you can actually make money with using a Semantic MediaWiki, wih the Centiare Prize 2007. Read more there.
First look at Freebase
I got the chance to get a close look at Freebase (thanks, Robert!). And I must say -- I'm impressed. Sure, the system is still not ready, and you notice small glitches happening here and there, but that's not what I was looking for. What I really wanted to understand is the idea behind the system, how it works -- and, since it was mentioned together with Semantic MediaWiki one or twice, I wanted to see how the systems compare.
So, now here are my first impressions. I will sure play more around with the system!
Freebase is a databse with a flexible schema and a very user friendly web front end. The data in the database is offered via an API, so that information from Freebase can be included in external applications. The web front end looks nice, is intuitive for simple things, and works for the not so simple things. In the background you basically have a huge graph, and the user surfs from node to node. Everything can be interconnected with named links, called properties. Individuals are called topics. Every topic can have a multitude of types: Arnold Schwarzenegger is of type politician, person, actor, and more. Every such type has a number of associated properties, that can either point to a value, another topic, or a compound value (that's their solution for n-ary relations, it's basically an intermediate node). So the type politician adds the party, the office, etc. to Arnold, actor adds movies, person adds the family relationships and dates of birth and death (I felt existentially challenged after I created my user page, the system created a page of me inside freebase, and there I had to deal with the system asking me for my date of death).
It is easy to see that types are crucial for the system to work. Are they the right types to be used? Do they cover the right things? Are they interconnected well? How do the types play together? A set of types and their properties form a domain, like actor, movie, director, etc. forming the domain "film", or album, track, musician, band forming the domain "music". A domain is being administrated by a group of users who care about that domain, and they decide on the properties and types. You can easily see ontology engineering par excellence going on here, done in a collaborative fashion.
Everyone can create new types, but in the beginning they belong to your personal domain. You may still use them as you like, and others as well. If your types, or your domain, turns out to be of interest, it may become promoted as being a common domain. Obviously, since they are still alpha, there is not yet too much experience with how this works out with the community, but time will tell.
Unsurprising I am also very happy that Metaweb's Jamie Taylor will give an invited talk at the CKC2007 workshop in Banff in May.
The API is based on JSON, and offers a powerful query language to get the knowledge you need out of Freebase. The description is so good that I bet it will find almost immediate uptake. That's one of the things the Semantic Web community, including myself, did not yet manage to do too well: selling it to the hackers. Look at this API description for how it is done! Reading it I wanted to start hacking right away. They also provide a few nice "featured" applications, like the Freebase movie game. I guess you can play it even without a freebase account. It's fun, and it shows how to reuse the knowledge from Freebase. And they did some good tutorial movies.
So, what are the differences to Semantic MediaWiki? Well, there are quite a lot. First, Semantic MediaWiki is totally open source, Metaweb, the system Freebase runs on, seems not to be. Well, if you ask me, Metaweb (also the name of the company) will probably want to sell MetaWeb to companies. And if you ask me again, these companies will make a great deal, because this may replace many current databases and many problems people have with them due to their rigid structure. So it may be a good idea to keep the source closed. On the web, since Freebase is free, only a tiny amount of users will care that the source of Metaweb is not free, anyway.
But now, on the content side: Semantic MediaWiki is a wiki that has some features to structure the wiki content with a flexible, collaboratively editable vocabulary. Metaweb is a database with a flexible, collaboratively editable schema. Semantic MediaWiki allows to extend the vocabulary easier than Metaweb (just type a new relation), Metaweb on the other hand enables a much easier instantiation of the schema because of its form based user interface and autocompletion. Metaweb is about structured data, even though the structure is flexible and changing. Semantic MediaWiki is about unstructured data, that can be enhanced with some structure between blobs of unstructured data, basically, text. Metaweb is actually much closer to a wiki like OntoWiki. Notice the name similarity of the domains: freebase.com (Metaweb) and 3ba.se (OntoWiki).
The query language that Metaweb brings along, MQL, seems to be almost exactly as powerful as the query language in Semantic MediaWiki. Our design has been driven by usability and scalability, and it seems that both arrived at basically the same conclusions. Just a funny coincidence? The query languages are both quite weaker than SPARQL.
One last difference is that Semantic MediaWiki is fully standards based. We export all data in RDF and OWL. Standard-compliant tools can simply load our data, and there are tons of tools who can work with it, and numerous libraries in dozens of programming languages. Metaweb? No standard. A completely new vocabulary, a completely new API, but beautifully described. But due to the many similarities to Semantic Web standards, I would be surprised if there wasn't a mapping to RDF/OWL even before Freebase goes fully public. For all who know Semantic Web or Semantic MediaWiki, I tried to create a little dictionary of Semantic Web terms.
All in all, I am looking forward to see Freebase fully deployed! This is the most exciting Web thingy 2007 until now, and after Yahoo! pipes, and that was a tough one to beat.
The benefit of Semantic MediaWiki
I can't comment on Tim O'Reilly's blog right now it seems, maybe my answer is too long, or it has too many links, or whatever. It only took some time, my mistake. He blogged about Semantic MediaWiki -- yaay! I'm a fanboy, really -- but he asks "but why hasn't this approach taken off? Because there's no immediate benefit to the user." So I wanted to answer that.
"About Semantic MediaWiki, you ask, "why hasn't this approach taken off?" Well, because we're still hacking :) But besides that, there is a growing number of pages who actually use our beta software, which we are very thankful to (because of all the great feedback). Take a look at discourseDB for example. Great work there!
You give the following answer to your question: "Because there's no immediate benefit". Actually, there is benefit inside the wiki: you can ask for the knowledge that you have made explicit within the wiki. So the idea is that you can make automatic tables like this list of Kings of Judah from the Bible wiki, or this list of upcoming conferences, including a nice timeline visualization. This is immediate benefit for wiki editors: they don't have to make pages like these examples (1, 2, 3, 4, 5, or any of these) by hand. Here's were we harness self-interest: wiki editors need to put in less work in order to achieve the same quality of information. Data needs to be entered only once. And as it is accessible to external scripts with standard tools, they can even write scripts to check the correctness or at some form of consistency of the data in the wiki, and they are able to aggregate the data within the wiki and display it in a nice way. We are using it very successfully for our internal knowledge management, where we can simply grab the data and redisplay it as needed. Basically, like a wiki with a bit more DB functionality.
I will refrain from comparing to Freebase, because I haven't seen it yet -- but from what I heard from Robet Cook it seems that we are partially complementary to it. I hope to see it soon :)"
Now, I am afraid since my feed's broken this message will not get picked up by PlanetRDF, and therefore no one will ever see it, darn! :( And it seems I can't use trackback. I really need to update to a real blogging software.
DL Riddle
Yesterday we stumbled upon quite a hard description logics problem. At least I think it is hard. The question was, why is this ontology unsatisfiable? Just six axioms. The ontology is availbe in OWL RDF/XML, in PDF (created with the owl tools), and here in Abstract Syntax.
Class(Rigid complete restriction(subclassof allValuesFrom(complementOf(AntiRigid)))) Class(NonRigid partial) DisjointClasses(NonRigid Rigid) ObjectProperty(subclassof Transitive) Individual(publishedMaterial type(NonRigid)) Individual(issue type(Rigid) value(subclassof publishedMaterial))
So, the question is, why is this ontology unsatisfiable? It is even a minimally unsatisfiable subset, actually, that means, remove any of the axioms and you get a satisfiable ontology. Maybe you like to use it to test your students. Or yourself. The debugger in SWOOP actually gave me the right hint, but it didn't offer the full explanation. I figured it out, after a few minutes of hard thinking (so, now you know how bad I am at DL).
Do you know? (I'll post the answer in the comments if no one else does in a few days)
(Just in case you wonder, this ontology is based on a the OntOWLClean ontology from Chris Welty, see his paper at FOIS2006 if you like more info)
Zur Macht der Blogger
sympatexter hat einen Eintrag dazu geschrieben, dass sich Blogger gerne für zu wichtig nehmen (als Antwort auf ein Stück von Robert Basic, der darüber schreibt, dass sich Blogger noch nicht wichtig genug nehmen). Als Randbemerkung: es ist amüsant zu sehen, dass ausgerechnet sympatexter auf diesen Missstand hinweißt, insbesondere da die Tagline des eigenen Blogs sympatexter rules the world ist. (Mein Fehler, sorry)
Was ist der Sinn des Bloggens? Das würde vielleicht zu weit führen. Aber einzelne Argumente des sympatexters möchte ich doch genauer beleuchten:
- "Was die Blogger interessiert, interessiert auch leider NUR die Blogger." Stimmt nicht ganz - oder zumindest würde ich dafür gerne mehr Beleg sehen. Blogger werden von der Werbewirtschaft als Multiplikatoren betrachtet - eine Eigenschaft, die sie nur haben können, wenn mehr Leute Blogs lesen als sie schreiben. Außerdem bloggen viele über allgemein interessante Themen, von Lost über Britney Spears, Verbrauchererfahrungen mit Produkten und Dienstleistungen, die Bundestagswahlen bis hin zu Menschenrechtsverletzungen in Guantanamo oder direkten Berichten aus Krisengebieten im Nahen Osten oder Thailand. Glaubt Ihr nicht? Schaut auf Technorati nach, die haben eine aktuelle Liste von populären Themen. Heutige Favoriten: die Oscars, Antonella Barba, und Al Gore. Alles Themen die auch außerhalb der Blogosphäre relevant sind.
- Meine Zustimmung zu der Beobachtung bezüglich der Statistiken. Die Zahlen, die in den Medien genannt werden, sind häufig irreführend, aber das ist eine Eigenschaft von Statistiken und Medien. Verfolgt man die Zahlen auf die Quelle, wird man oft enttäuscht sein.
- "In Deutschland lesen sehr wenige Menschen Blogs." Auch hier hätte ich gerne Zahlen. Ich bin mir sicher, dass ein großer Teil der webnutzenden Bevölkerung schon mal einen Blog gelesen hat, schlicht, weil sie bei Anfragen bei den Suchmaschinen häufig auf Blogeinträge stoßen. Vielleicht sind sich die Leser nicht mal bewusst, dass sie einen Blog lesen (ebenso wie der Anteil der Wikipedia-Leser, der nicht weiß, dass die Wikipedia von jedem verändert werden kann, stark zugenommen hat). Einige meiner bestbesuchten Einträge haben mit dem Kochen von Milchreis, den Machenschaften des Kleeblatt-Verlags, und Filmen zu tun. Die Leute, die das Lesen sind nicht die üblichen Leser meines Blogs -- aber ein wichtiger Anteil.
- "Die meisten Blogs haben noch nicht mal dreistellige Zugriffszahlen pro Tag und werden meistens von Freunden gelesen." Zustimmung, und gleichzeitig die Frage: na und? Ich erwarte ja, dass dieser Blog hier eigentlich nur von Leuten gelesen wird, die mich kennen. Das kann wieder für einzelne Beiträge anders sein, aber im Allgemeinen trifft das zu. Und das, was ich schreibe, interessiert auch meistens nur diese Wenigen -- wenn überhaupt. Aber das ist OK. Blogs werden vielfach dafür verwendet, die Kommunikation zu Freunden und Bekannten, oder gar zur Familie, zu vereinfachen, gar zu ermöglichen, oder sie schlicht aufrechtzuerhalten. Und das ist gut so. Nicht jeder Blog muss Hunderttausende von Lesern haben, das wäre nicht mal möglich. Man darf halt als Blogger dann aber auch nicht erwarten, dass Hunderttausende lesen und durch die Einträge beeinflusst werden.
- "Etwas zu verlinken, was älter als eine Woche ist, ist ja schon fast Blasphemie - so versinkt das meiste, kaum wahrgenommen, in den Archiven." Zurecht beanstandet. Man sollte häufiger in die Archive verlinken, und strukturierte Einträge machen, die langfristig von Interesse sind. Semantische Technologien, wie ich sie auch in meiner Arbeit entwickle, sollen auch konkret an diesen Baustellen arbeiten. Ein Probekapitel zu semantischen Blogs und Wikis aus einem jüngst erschienen Buch über Wikis und Blogs gibt dazu ein wenig Einsicht, wie man sich das vorstellen kann. Leider sind nur die ersten 8 Seiten online verfügbar. (Achtung Werbung!) Kauft das Buch! (Werbung Ende) Solche Technologien sollen helfen, Blogeinträge dann verfügbar zu machen, wenn sie relevant sind. Einen ersten Vorgeschmack bietet die Firefox Extension Blogger Web Comments von Google.
Letztlich aber bleibt ein Argument vor allem: selbst wenn es wenige lesen, und es viel zu häufig Nabelschau ist, was die Blogger machen -- dieser Eintrag mit eingeschlossen, ironischerweise -- ist das Bloggen eine Technik, die es zum ersten Mal in der Geschichte der Menschheit tatsächlich so vielen Leuten konkret ermöglicht, aktiv eine Stimme zu haben. Ob das, was diese Leute damit anfangen, gut ist oder nicht, dass sei eine Entscheidung des Einzelfalls. Aber allein die Tatsache, dass heute Klein-Gretchen aus Hintertupfingen ihre handgekrakelten Bilder hochladen kann, und sie sofort weltweit zugänglich sind, ist ein Schritt auf dem Weg zu einer globalen Gesellschaft. Ein kleiner, ja, aber ein notwendiger und auch wichtiger.
Talk in Korea
If you're around this Tuesday, February 13th, in Seoul, come by the Semantic Web 2.0 conference. I had the honour to be invited to give a talk on the Semantic Wikipedia (where a lot is happening right now, I will blog about this when I come back from Korea, and when the stuff gets fixed).
Looking forward to see you there!
Mail problems
The last two days my mail account had trouble. If you could not send something to me, sorry! Now it should work again.
Since it is hard to guess who tried to eMail me in the last two days (I guess three persons right), I hope to reach some this way.
Building knowledge together - extended
In case you did not notice yet -- the CKC2007 Workshop on Social and Collaborative Construction of Structured Knowledge at the WWW2007 got an extended deadline due to a number of requests. So, you have time to rework your submissions or finish yours! Also the demo submission deadline is upcoming. We want to have a shootout of the tools that have been created in the last few years, and get hands on to the differences, problems, and best ideas.
See you in Banff!
Nutkidz Jubiläum
Die 50. Folge der nutkidz ist erschienen! Und zum Jubiläum haben wir uns was besonderes einfallen lassen.
Viel Spaß! Und übrigens, ja, sie erscheinen wieder regelmäßig. Zwar nur monatlich, aber immerhin regelmäßig. Und wieviele monatliche Webcomics gibt es schon?
Collaborative Knowledge Construction
The deadline is upcoming! This weekend the deadline for submissions to the Workshop on Social and Collaborative Construction of Structured Knowledge at the WWW2007 will be over. And this may be easily the hottest topic of the year, I think: how do people construct knowledge in a community?
Ontologies are meant to be shared conceptualizations -- but how many tools really allow to build ontologies in a widely shared manner?
I am especially excited about the challenge that comes along with the workshop, to examine different tools, and to see how their perform. If you have a tool that fits here, write us.
So, I know you have thought a lot about the topic of collaboratively building knowledge -- write your thoughts down! Send them to us! Come to Banff! Submit to CKC2007!
Was für ein Zufall!
Ich schreibe einem Kollegen in den Niederlanden. Der Antwortet mir, dass er bald nach Barcelona zieht, auf eine neue Stelle. Keine zwei Minuten später schickt mir Sixt eine eMail mit einem Spezialangebot, Hotel und Mietwagen für drei Tage Barcelona für nur X Euro.
Was für ein Zufall!
Semantic MediaWiki goes business
... but not with the developers. Harry Chen writes about it, and several places copy the press release about Centiare. Actually, we didn't even know about it, and were a bit surprised to hear that news after our trip to India (which was very exciting, by the way). But that's OK, and actually, it's pretty exciting as well. I wish Centiare all the best! Here is their press release.
They write:
Centiare's founder, Karl Nagel, genuinely feels that the world is on the verge of an enormous breakthrough in MediaWiki applications. He says, "What Microsoft Office has been for the past 15 years, MediaWiki will be for the next fifteen." And Centiare will employ the most robust extension of that software, Semantic MediaWiki.
Wow -- I'd never claim that SMW is the most robust extension of MediaWiki -- there are so many of them, and most of them have a much easier time of being robust! But the view of MediaWiki taking the place of Office -- Intriguing. Although I'd put my bets rather on stuff like Google Docs (former Writely), and add some semantic spice to it. Collaborative knowledge construction will be the next big thing. Really big I mean. Oh, speaking about that, check out this WWW workshop on collaborative knowledge construction. Deadline is February 2nd, 2007.
Click here for more information about Centiare.
Goldener Würfel
Nein, kein Rollenspielpreis, das war der Goldene Becher. Vielmehr hatte Schwesterchen von der Post einen Brief abgeholt, während ich in Indien war, und nun, da ich zurück bin, habe ich ihn endlich aufgemacht, und deswegen kann ich jetzt nicht über Indien schreiben sondern widme mich diesem Brief.
Der Inhalt? Ein Würfel, scheinbar mit goldener Folie überzogen, und wo die Eins sein sollte ist ein kleines Bild von etwas kaum erkennbaren. Ich dachte im ersten Moment, es sei eine Rorschach-Figur. Nachdem Schwesterchen ja schon letztes Jahr beim Hustle-the-Sluff dabei war, nehme ich an, dass es diesmal etwas ähnliches ist. Also, ab zu Googles Blogsearch, und danach gesucht, und, wer sagt's denn, gleich ein Treffer, bei Daniel Gramsch, dem Zeichner von Alina Fox.
Aus einem Kommentar ist zu entnehmen, dass Daniel Rüd ebenfalls einen solchen Brief enthalten hat, aber noch nicht darüber gebloggt hat. Ein weiterer Kommentar von Angie enthält sogar einen Link, auf dem man erkennt, dass der vermeintliche Rorschachtest doch eine Kuppel ist, von Schloss Charlottenburg in Berlin, mit der Fortuna drauf. Passend für einen Würfel, durchaus.
Laut dem Fuchsbau deutet das ganze auf ein sogenanntes Alternate Reality Game hin, eine Art elaborierter Mischung aus Live-Rollenspiel und Schnitzeljagd. Etwas, für das ich zur Zeit überhaupt nicht die Zeit habe, aber dann wiederum klingt es so spannend, dass ich sehr viel Lust darauf habe. Ich habe erst unlängst das spannende Buch Convergence Culture von Henry Jenkins vom MIT CMS verschlungen, in dem er solche und ähnliche Phänomene beschreibt.
Drum fänd ich's spannend, doch dabei zu sein. Also, auf zu der von Angie entdeckten Webseite, um mehr Informationen auszugraben. Angie, wenn Du das liest -- wie hast Du die Seite ausfindig gemacht? Und wer bist Du?
Wer sonst hat noch einen Würfel erhalten?
Frohes Neues Jahr!
Letztes Jahr schrieb ich einen langen 2005er Abschiedseintrag. Dieses Jahr nicht, nicht etwa weil das Jahr nicht gut zu mir war -- es war sehr gut zu mir! -- sondern einfach, weil mir die Zeit fehlt. Ich muss noch packen. In weniger als zwei Stunden beginnt meine Reise nach Indien. Nein, nicht wegen der Arbeit, ganz privat. Langsam werde ich nervös, dass ich das mit dem Packen nicht mehr packe.
2006 war unglaublich gut. Ich konnte von mancher Arbeit die Früchte ernten, und andere Pflanzen weiter wachsen sehen. 2007 und 2008 stehen dann weitere Ernten an. Allerdings fällt mir auf, dass ich wahrscheinlich einer der schlechtesten Blogger des Planeten bin. Da schreibe ich an Büchern mit, und hier erwähne ich die nicht mal! Das werde ich nächstes Jahr nachholen müssen. Allerdings hängt das auch ein wenig mit dem geplanten Relaunch von Nodix zusammen. Viele Inhalte warten noch darauf, dass ich sie wieder hochlade, aber das mache ich erst, wenn ich die neue Software eingerichtet habe. Den Wunschtermin - zum Nodix-Geburtstag - werde ich wohl nicht mehr schaffen, schade. Aber ich lenke wieder ab, ich sollte wirklich packen. Wir hören uns ja wieder, in ein paar Wochen. Vielleicht erzähle ich sogar von Indien. Und von ein paar anderen Reisen von diesem Jahr. Zu erzählen gäbe es zumindest manches.
Allen Lesern meine besten Wünsche zum Neuen Jahr! Allen eine schöne Feier, einen guten Rutsch, mögen ein paar Eurer Wünsche für 2007 in Erfüllung gehen.
Five things you don't know about me
Well, I don't think I have been tagged yet, but I could be within the next few days (the meme is spreading), and as I won't be here for a while, I decided to strike preemptively. If no one tags me, I assume to take one of danah's.
So, here we go:
- I was born without fingernails. They grew after a few weeks. But nevertheless, whenever they wanted to cut my nails when I was a kid, no one could do it alone -- I always panicked and needed to be held down.
- Last year, I contributed to four hardcover books. Only one of them was scientific. The rest were modules for Germany's most popular role playing game, The Dark Eye.
- I am a total optimist. OK, you knew that. But you did not know that I actually tend to forget everything bad. Even in songs, I noticed that I only remember the happy lines, and I forget the bad ones.
- I co-author a webcomic with my sister, the nutkidz. We don't manage to meet any schedule, but we do have a storyline. I use the characters quite often in my presentations, though.
- I still have an account with Ultima Online (although I play only three or four times a year), and I even have a CompuServe Classic account -- basically, because I like the chat software. I did not get rid of my old PC, because it still runs the old CompuServe Information Manager 3.0. I never figured out how to run IRC.
I bet no one of you knew all of this! Now, let's tag some people: Max, Valentin, Nick, Elias, Ralf. It's your turn.
Semantic Web patent
Tim Finin and Jim Hendler are asking about the earliest usage of the term Semantic Web. Tim Berners-Lee (who else?) spoke about the need of semantics in the web at the WWW 1994 plenary talk in Geneva, though the term Semantic Web does not appear there directly. Whatever. What rather surprised me, though, is, when surfing a bit for the term, I discovered that Amit Sheth, host of this year's ISWC, filed the patent on it, back in 2000: System and method for creating a Semantic Web. My guess would be, that is the oldest patent of it.
Der am schnellsten gebrochene Vorsatz
- Keine Vorsätze haben.
Schneller als den kann man keinen Vorsatz brechen.
Supporting disaster relief with semantics
Soenke Ziesche, who has worked on humanitarian projects for the United Nations for the last six years, wrote an article for xml.com on the use of semantic wikis in disaster relief operations. That is a great scenario I never thought about, and basically one of these scenarios I think of when I say in my talks: "I'll be surprised if we don't get surprised by how this will be used." Probably I would even go to state the following: if nothing unexpected happens with it, the technology was too specific.
Just the thought that semantic technology in general, and maybe even Semantic MediaWiki in particular, could relief the effects of a natural disaster, or maybe even safe a life, this thought is so incredible exciting and rewarding. Thank you so much Soenke!
All problems solved
Today I feel a lot like the nameless hero from the PhD comics, and what is currently happening to him (begin of the storyline, continuation, especially here, and very much like here, but pitily, not at all like here). Today we had Boris Motik visiting the AIFB, who is one of the brightest people on this planet. And he gave us a more than interesting talk on how to integrate OWL with relational databases. What especially interested me was his great work on constraints -- especially since I was working on similar issues, unit tests for ontologies, as I think constraints are crucial for evaluating ontologies.
But Boris just did it much cleaner, better, and more thorough. So, I will dive into his work and try to understand it to see, if there is anything left to do for me, or if I have to refocus. There's still much left, but I am afraid the most interesting part from a theoretic point is solved. Or rather, in the name of progress, I am happy it is solved. Let's get on with the next problem.
(I *know* it is my own fault)
Semantic Wikipedia presentations
Last week on the Semantics 2006 Markus and I gave talks on the Semantic MediaWiki. I was happy to be invited to give one of the keynotes at the event. A lot of people were nice enough to come to me later to tell me how much they liked the talk. And I got a lot of requests for the slides. I decided to upload them, but wanted to clean them a bit. I am pretty sure that the slides are not self-sufficient -- they are tailored to my style of presentations a lot. But I added some comments to the slides, so maybe this will help you understand what I tried to say if you have not been in Vienna. Find the slides of the Semantics 2006 keynote on Semantic Wikipedia here. Careful, 25 MB.
But a few weeks ago I was at the KMi Podium for an invited talk there. The good thing is, they don't have just the slides, they also have a video of the talk, so this will help much more in understanding the slides. The talk at KMi has been a bit more technical and a lot shorter (different audiences, different talks). Have fun!
Rollenspiel und Web 2.0
Letzte Woche hielt ich in Wien einen Vortrag auf der Semantics 2006. Danach wurde ich um ein Radio-Interview gebeten, und dabei sprachen wir über das Semantic Web, Web 2.0 und ähnliche Themen -- meine Arbeit halt. Semantic Web, das Web der Daten, Web 2.0, das Mitmach-Web (ganz grob).
Plötzlich aber wechselte die Reporterin das Thema, meinte, ich würde ja auch an Deutschlands beliebtestem Rollenspiel Das Schwarze Auge arbeiten. Ob ich den Zuhörern erklären könnte, was denn Rollenspiel sei. Und da erklärte ich Rollenspiel als Geschichtenerzählen 2.0 -- Geschichtenerzählen zum Mitmachen, wo es darum geht, in der Gruppe eine gemeinsame Geschichte zu erzählen.
Na, wenn das mal keine neue Definition ist.
Zeitverschiebung
Es ist Mittag in Hawaii, und ich bin müde! Herrje.
Liegt wahrscheinlich daran, dass ich in Karlsruhe bin.
Semantic MediaWiki 0.6: Timeline support, ask pages, et al.
It has been quite a while since the last release of Semantic MediaWiki, but there was enormous work going into it. Huge thanks to all contributors, especially Markus, who has written the bulk of the new code, reworked much of the existing, and pulled together the contributions from the other coders, and the Simile team for their great Timeline code that we reused. (I lost overview, because the last few weeks have seen some travels and a lot of work, especially ISWC2006 and the final review of the SEKT project I am working on. I will blog on SEKT more as soon as some further steps are done).
So, what's new in the second Beta-release of the Semantic MediaWiki? Besides about 2.7 tons of code fixes, usability and performance improvements, we also have a number of neat new features. I will outline just four of them:
- Timeline support: you know SIMILE's Timeline tool? No? You should. It is like Google Maps for the fourth dimension. Take a look at the Timeline webpage to see some examples. Or at ontoworld's list of upcoming events. Yes, created dynamically out of the wiki data.
- Ask pages: the simple semantic search was too simple, you think? Now we finally have a semantic search we dare not to call simple. Based on the existing Ask Inline Queries, and actually making them also fully functional, the ask pages allow to dynamically query the wiki knowledge base. No more sandbox article editing to get your questions answered. Go for the semantic search, and build your ask queries there. And all retrievable via GET. Yes, you can link to custom made queries from everywhere!
- Service links: now all attributes can automatically link to further resources via the service links displayed in the fact box. Sounds abstract? It's not, it's rather a very powerful tool to weave the web tighter together: service links specify how to connect the attributes data to external services that use that data, for example, how to connect geographic coordinates with Yahoo maps, or ontologies with Swoogle, or movies with IMdb, or books with Amazon, or ... well, you can configure it yourself, so your imagination is the limit.
- Full RDF export: some people don't like pulling the RDF together from many different pages. Well, go and get the whole RDF export here. There is now a maintenance script included which can be used via a cron job (or manually) to create an RDF dump of the whole data inside the wiki. This is really useful for smaller wikis, and external tools can just take that data and try to use it. By the way, if you have an external tool and reuse the data, we would be happy if you tell us. We are really looking forward to more examples of reuse of data from a Semantic MediaWiki installation!
I am looking much forward to December, when I can finally join Markus again with the coding and testing. Thank you so very much for your support, interest, critical and encouraging remarks with regards to Semantic MediaWiki. Grab the code, update your installation, or take the chance and switch your wiki to Semantic MediaWiki.
Just a remark: my preferred way to install both MediaWiki and Semantic MediaWiki is to pull it directly from the SVN instead of taking the releases. It's actually less work and helps you tremendously in keeping up to date.
Semantic Web Challenge 2006 winners
Sorry for the terseness, but I am sitting in the ceremony.
18 submissions. 14 passed the minimal criteria.
Find more information on challenge.semanticweb.org -- list of Finalists, links, etc. See also on ontoworld.
And the winners are ...
3. Enabling Semantic Web communities with DBin: an overview (by Christian Morbidoni, Giovanni Tummarello, Michele Nucci)
2. Foafing the Music: Bridging the semantic gap in music recommendation (by Oscar Celma)
1. MultimediaN E-Culture demonstrator (by Alia Amin, Bob Wielinga, Borys Omelayenko, Guus Schreiber, Jacco van Ossenbruggen, Janneke van Kersen, Jan Wielemaker, Jos Taekema, Laura Hollink, Lynda Hardman, Marco de Niet, Mark van Assem, Michiel Hildebrand, Ronny Siebes, Victor de Boer, Zhisheng Huang)
Congratulations! It is great to have such great projects to show off! :)
ISWC 2008 coming to Karlsruhe
Yeah! ISWC2006 is just starting, and I am really looking forward to it. The schedule looks more than promising, and Semantic MediaWiki is among the finalists for the Semantic Web Challenge! I will write more about this year's ISWC the next few days.
But, now the news: yesterday it was decided that ISWC2008 will be hosted by the AIFB in Karlsruhe! It's a pleasure and a honor -- and I am certainly looking forward to it. Yeah!
Semantic Web and Web 2.0
I usually don't just point to other blog entries (thus being a bad blogger regarding netiquette), but this time Benjamin Nowack nailed it in his post on the Semantic Web and Web 2.0. I read the iX article (a popular German computer technology magazine), and I lost quite some respect for the magazine as there were so many unfounded claims, off-the-hand remarks, and so much bad attitude in the article (and in further articles scuttered around the issue) towards the Semantic Web that I thought the publisher was personally set on a crusade. I could go through the article and write a commentory on it, and list the errors, but honestly, I don't see the point. At least it made me appreciate peer review and scientific method a lot more. The implementation of peer review is flawed as well, but I realize it could be so much worse (and it could be better as well - maybe PLoS is a better implementation of peer review).
So, go to Benji's post and convince yourself: there is no "vs" in Semantic Web and Web 2.0.
Java developers f*** the least
Andrew Newman conducted a brilliant and significant study on how often programmers use f***, and he splitted it on programming languages. Java developers f*** the least, whereas LISP programmers use it on every fourth opportunity. In absolute term, there are still more Java f***s, but less than C++ f***s.
Just to add a further number to the study -- because Andrew unexplicably omitted Python -- here's the data: about 196,000 files / 200 occurences -> 980. That's the second highest result, placing it between Java and Perl (note that the higher the number, the less f***s -- I would have normalized that by taking it 1/n, but, fuck, there's always something to complain).
Note that Google Code Search actually is totally inconsisten with regards to their results. A search for f*** alone returns 600 results, but if you look for f*** in C++ it returns 2000. So, take the numbers with more than a grain of salt. The bad thing is that Google counts are taken as a basis for a growing number of algorithms in NLP and machine learning (I co-authored a paper that does that too). Did anyone compare the results with Yahoo counts or MSN counts or Ask counts or whatever? This is not the best scientific practice, I am afraid. And I comitted it too. Darn.
Meeting opportunities
I read in an interview in Focus (German) with Andreas Weigend, he says that publishing his travel arrangements in his blog helped him meet interesting people and allow for unexpected opportunities. I actually noticed the same thing when I wrote about coming to Wikimania this summer. And those were great meetings!
So, now, here are the places I will be in the next weeks.
- Oct 18-Oct 20, Madrid: SEKT meeting
- Oct 22-Oct 26, Milton Keynes (passing through London): Talk at KMi Podium, Open University, on Semantic MediaWiki. There's a webcast! Subscribe, if you like.
- Oct 30-Nov 3, Montpellier: ODBASE, and especially OntoContent. Having a talk there on Unit testing for ontologies.
- Nov 5-Nov 13, Athens, Georgia: ISWC and OWLED
- Nov 15-Nov 17, Ipswich: SEKT meeting
- Nov 27-Dec 1, Vienna: Keynote at Semantics on Semantic Wikipedia
- Dec 13-17, Ljubljana: SEKT meeting
- Dec 30-Jan 10, Mumbai and Pune: the travel is private, but this doesn't mean at all we may not meet for work if you're around that part of the world
Just mail me if you'd like to meet.
RDF in Mozilla 2
I read last week Brendan Eich's post on Mozilla 2, where he said that with Moz2 they hope that they can "get rid of RDF, which seems to be the main source of "Mozilla ugliness"". Danny Ayers commented on this, saying that RDF "should be nurtured not ditched."
Well, RDF in Mozilla always was crappy, and it was based on a pre-1999-standard RDF. No one ever took up the task -- remind you, it's open source -- to dive into the RDF inside Mozilla and repair and polish it, make it a) compatible to the 2004 RDF standard, (why didn't RDF get version numbers, by the way?) and b) clean up the code and make it faster.
My very first encounter with RDF was through Mozilla. I was diving into Mozilla as a platform for application development, which seemed like a very cool idea back then (maybe it still is, but Mozilla isn't really moving into this direction). RDF was prominent there: as an internal data structure for the developed applications. Let's repeat that: RDF, which was developed to allow the exchange of data on the web, was used within Mozilla as an internal data structure.
Surprisingly, they had performance issues. And the code was cluttered with URIs.
I still think it is an interesting idea. In last year's Scripting for the Semantic Web workshop I presented an idea on integrating semantic technologies tightly into your programming. Marian Babik and Ladislav Hluchy picked that idea up and expanded and implemented the work much better than I ever could.
It would be very interesting how this combination could really be put to work. An internal knowledge base for your app that is queried via SPARQL. Doesn't sound like the most performant idea. But then -- imagine not having one tool accessing that knowledge base. But rather a system architecture with a number of tools accessing that knowledge base. Adding data to existing data. Imagine just firing up a newly installed Adressbook, and -- shazam! -- all your data is available. You don't like it anymore? Switch back. No changes lost. Everything is just views.
But then again, didn't the DB guys try to do the same? Yes, maybe. But with semantic web technology, shouldn't it be easier to do it, because it is meant to integrate?
Just thinking. Would love to see a set of tools based on a plugabble knowledge base. I'm afraid, performance would suck. I hope we will see.
Das Stöckchen behalte ich
So. Ich fange das nächste Stöckchen auf, von Buddy. Also los.
Fünf Dinge, die ich nicht habe, aber gerne hätte
- Weltfrieden.
- Das Semantic Web.
- Einen Roman. Selbstgeschrieben, fertig, und mit Verleger. Und richtig gut.
- Ein Direktes Neuronales Interface zur Matrix. Ich meine zum Web.
- Die Eine Richtige.
- Sechs Richtige.
- Die Fähigkeit bis Fünf zu zählen.
Die Reihenfolge enspricht nicht der Relevanz.
Fünf Dinge, die ich habe, aber lieber nicht hätte
- Keine Ahnung.
- Eine schlecht gewartete Website.
- Zu wenig Zeit.
- Mir wird schlecht, wenn ich Gurken esse.
- Ein paar Kilogramm.
Fünf Dinge, die ich nicht habe, aber auch nicht haben möchte
- Allzuviel gesunder Menschenverstand.
- Verzweiflung.
- Langeweile.
- Geldsorgen.
- Die Falsche.
Fünf Dinge, die ich habe und aus keinem Grund der Welt missen möchte
- Schwesterchen.
- Freunde.
- Meine Doktorandenstelle am AIFB.
- Optimismus. Eine Menge.
- Musik.
Fünf Menschen, die dies noch nicht beantwortet haben, von denen ich mir das aber wünsche
- Der Papst.
- Die Bundeskanzlerin. In ihrem nächsten Podcast.
- John Lennon.
- Lisa Simpson.
- Der unbekannte Soldat.
Enjoying dogfood
I guess the blog's title is a metaphor gone awry... well, whatever. About two years ago at Semantic Karlsruhe (that is people into semantic technologies at AIFB, FZI, and ontoprise) we installed a wiki to support the internal knowledge management of our group. It was well received and used. We also have an annual survey about a lot of stuff within our group, to see where we can improve. So last year we found out, that the wiki was received OK. Some were happy, some were not, nothing special.
We switched to a Semantic MediaWiki since last year, which was a labourous step. But it seems to have payed off: recently we had our new survey. The scale goes from very satisfied (56%) over satisfied (32%) and neutral (12%) to unsatisfied (0%) and very unsatisfied (0%).
You can tell I was very happy with these results -- and quite surprised. I am not sure, how much the semantics made the difference, or maybe we did more "gardening" on the wiki since we felt more connected to it, and gardening cannot be underestimated, both in importance and resources. In this vein, very special thanks to our gardeners!
One problem a very active gardener pointed out not long ago was that gardening gets hardly appreciated. How do other small-scale or intranet wiki tackle this problem? Well, in Wikipedia we have the barnstars, and related cool stuff -- but that is basically working because we have an online community and online gratification is OK for that (or do I misunderstand the situation here? I am not a social scientist). But how to translate that to an actually offline community that has some online extensions like in our case?
Berlin, Berlin, ich war jetzt in Berlin...
... und nicht in Olpe. Da fahre ich wohl in ein paar Wochen hin. Aber aus einem ganz anderen Grund. Dafür fliegt Schwesterchen nach Berlin. Aber auch aus einem ganz anderen Grund.
Und Berlin ist sehr wow. Der Reichstag, das Bundeskanzleramt, riesige, beeindruckende Gebäude; die gewaltigen Parks; atemberaubend: das Pergamonmuseum. Einfach unglaublich. Ich habe immer gedacht, der Pergamonaltar wäre halt ein Altar, also ein Steinblock. Niemand hat mir gesagt, dass sie den ganzen Tempel auseinandergeschnitten haben und nach Berlin gebracht haben! Unglaublich. Und dann geht man weiter, tritt durch einen Eingang, und denkt sich, hmm, irgendwie habe ich Blau im Nacken. Und da dreht man sich um, und ist gerade durch das Ischtartor getreten. Und es sieht noch viel beeindruckender aus, als in den Büchern. Ist halt auch etwas größer als in den Büchern.
Und Nofretete ist auch hübsch. Nicht ganz so hübsch wie Ginevra, also bleibt letztere mein Desktop-Hintergrund.
{kind=link}
Und das Mauermusuem hat mich mehrfach auf meine Tränendrüse gedrückt. Wahnsinnsgeschichten. Und auf dem Weg zu einem allgemeinem Menschenrechtsmuseum. Mit Info zu Gandhi, zu dem Aufstand in Ungarn, zu den Religionen und ihren Gemeinsamkeiten, und vieles mehr. Aber halt auch: wie ist die Mauer gebaut? Die Helden, die Tunnel bauten. Die Helden, die trotz Befehl nicht auf die Flüchtlinge schossen. Die Helden, die den Stacheldraht hochheben, damit das Kind durchkommt. Die Helden, die stark genug waren, keine Gewalt anzuwenden. Ich weiß nicht, ob ich die selbe Stärke hätte.
Habe auch ein Stück Mauer gekauft. Und weggeschickt. Weil die Mauer muss weg.
Genau.
Ach ja, und die Arbeit war auch cool. Wahrscheinlich eine der coolsten Locations überhaupt: Unter den Linden 1. Direkt an der Museumsinsel.
Apricot ist keine Farbe
Zumindest nicht für Männer. Es gibt aber einen kleinen Anteil Frauen, die vier statt drei verschiedene Zapfen im Auge haben. Dadurch können sie tatsächlich mehr verschiedene Farben sehen (bis zu 100 Millionen verschiedene Farben -- statt nur eine Million bei uns Männern, und den meisten Frauen, nur etwa 2-3% der Frauen sind sogenannte Tetrachromanten). Es sei unvorstellbar, wie das aussehe (ja, das kann ich mir vorstellen, ich meine, nicht vorstellen).
Blöd. Ich fühle mich jetzt voll benachteiligt. Gott ist doch Sexist, verflixtnochmal.
Wetten, dass...
„Hast Du die Titelseite gesehen? Schon wieder eine Story über den 11. September…“
„Weißt Du, solange es noch um 2001 geht, ist doch alles in Ordnung.“
„Das ist doch nur für die Medien. Meinst Du, die schlagen wieder zu?“
„Zum Jahrestag?“
„Ja. Wäre doch der Hammer.“
„Ich weiß nicht. Das ist sicher zu vorhersagbar. Alle werden vorbereitet sein.“
„Eben! Stell Dir vor, das gelingt ihnen! Damit zeigen sie, wie fett sie sind.“
„Ja, schon, aber ich glaube, es klappt nicht.“
„Ich würde wetten…“
„Was?!“
„50 Euro. Am 11. September kommt es zu einem weiteren Anschlag.“
„Diesen Jahres?“
„Ja.“
„Ich weiß nicht…“
„Na gut, ich gewinne nur, wenn es mehr als 200 Tote gibt, sonst zählt es nicht.“
„Hmm… abgemacht.“
… die Polizei war abgelenkt durch einen Bombenalarm im Hauptbahnhof … wegen einem vergessenen Koffer… ein terroristischer Hintergrund … eine Reihe von Explosionen erschütterte das Brandenburger Tor, bevor es schließlich in sich zusammenstürzte … die ersten Schätzungen gehen von mehr als 100 Toten aus … die wollen doch Krieg! Dann geben wir ihnen Krieg! … niemand hätte erwartet, dass ausgerechnet Deutschland … die Bundesregierung wurde in Sicherheit gebracht … die ganze Nation konnte zusehen, wie das Brandenburger Tor … vermutet Al-Quaida … wurde eine Moschee angegriffen … Live Schaltung nach Washington … uneingeschränkte Solidarität mit unseren deutschen Brüdern und Schwestern … tiefe Bestürzung … einziges Ziel der sukzessiven Explosionen war, den Fernsehteams genug Zeit … bestätigt, dass es bislang 200 Todesopfer gab, und eine weitere Frau noch um ihr Leben kämpft …
Er zündete sich eine Zigarette an. Seine Finger zitterten. Er stand im Treppenhaus des Hospitals. Hier durfte er rauchen. Und die Ruhe genießen. Das dauernde piep, piep, piep zehrte an seinen Nerven. Seine Mutter. Seine Mutter kämpfte um das Leben.
Die Tür ging auf. Sein bester Freund stand da, schaute etwas blass. Er holte seinen Geldbeutel raus, und drückte ihm zwei Zwanziger in die Hand.
„Fehlen noch Zehn. Kriegst Du morgen im Club.“
Noch ein Stöckchen
Diesmal von Schwesterchen.
Wann stehst Du zur Arbeit auf?
Sehr unterschiedlich. Manchmal erst zu Mittag, manchmal um 5:45.
Stehst Du rechtzeitig auf oder bleibst Du bis zur letzten Minute liegen?
Ich bleibe so lange liegen wie möglich.
Wie viele Wecker hast Du?
Einen. Seit meiner Grundschulzeit der selbe. So eine grüner, würfelförmiger Plastikradiowecker mit roter LED-Digitalanzeige.
Machst Du Frühsport?
Sollte ich mal anfangen.
Frühstückst Du? Wenn ja, was?
Meistens. Habe gehört, dass es gesund sein soll.
Wie fährst Du zur Arbeit?
Zunächst mit der U-Bahn zum Hauptbahnhof, dann von dort aus mit dem IC nach Karlsruhe, dort mit der Bahn zur Uni. Und das heute seit genau 2 Jahren. Habe Jubiläum :)
So, das Stöckchen gebe ich jetzt, nachdem es erledigt ist, Pflichtgemäß an Ralf und Cindy weiter. Ich gehe davon aus, dass wir Arbeit durch Uni ersetzen können. Außerdem sollte Cindy mal wieder was schreiben.
Hmm, eigentlich würde ich bei Ralf ja gerne den Blogeintrag verlinken, in dem er antwortet. Da dieser aber noch nicht geschrieben ist, geht das nicht. Blödes Web. Sollte man mal was erfinden. Ich kann ja raten, wo die Antwort auf dieses Stöckchen sein wird.
Das Lied vom Herrn Baron
Das Diadem von Elfenhand ist ein DSA Abenteuer von mir, welches in der Abenteuersammlung Leicht verdientes Gold erschienen ist. In dem Abenteuer spielt ein Lied eine wichtige Rolle, und so wurde es das erste (und bisher einzige) DSA Abenteuer mit Noten (Apropos Noten: wer es gespielt hat, kann auf dem Wiki Aventurica seine Meinung dazu abgeben - auch als Spielleiter)
So, hier ein besonderer Autorenservice (nachdem ich heute wieder mal nach der Melodie gefragt wurde), das Midi file zu Der Baron.
Viel Spaß bei dem Abenteuer! Ganz klar mein bestes DSA Abenteuer (bisher... ;)
Geht doch
Kroatien besiegt den Fußballweltmeister Italien 2:0. Gestern abend. Im Fußball.
Semantic MediaWiki officially Beta
Semantic MediaWiki has gone officially Beta. Markus Krötzsch released Version 0.5 yesterday -- download it at Sourceforge and update your installation!
Markus and I are both busy today updating existing installations (and creating new ones -- greetings towards California!). The new version has several new features:
- One can reuse existing Semantic Web vocabulary, like FOAF. This feature is used so strongly, it led to Swoogle actually believing, FOAF was defined at ontoworld!
- The unit code was improved a lot -- one can define linear units now from inside the wiki. Africa has a list of all African countries, and you can see their size neatly listed.
- New datatypes for URLs and Emails.
- Better code (why we dare to call us Beta)
Check out the new features on ontoworld. Thanks for Markus and S for the coding marathon this weekend, that allowed to make this new release! We are fetching bugs now, and planning 0.6, and our first big stress tests, with lots and lots of data...
Volver
Pedro Almodóvar macht mal wieder einen Film, und natürlich wird er schön. Wo La mala educación auf schöne Männer setzte, spielen diesmal Frauen die Hauptrolle. Und Nebenrollen. Eigentlich, alle Rollen. In Volver, wie schon in La mala educación, sind Männer nur diejenigen, die Unheil über die Welt bringen. Frauen sind diejenigen, die danach alles verkomplizieren. Äußerst scharfsinnige Beobachtung.
Die Geschichte ist so schön kompliziert und verkorkst, dass sie schon fast wahr sein muss. Der Vergangenheit kann man nicht entfliehen, sie holt dich immer wieder ein -- vielleicht ist das die Hauptaussage des Films. Paul Valéry sagte mal, dass wir der Zukunft mit dem Rücken voran entgegengehen, dass wirnicht sehen, was uns erwartet, sondern nur das, was in der Vergangenheit geschehen ist. Und genau so handeln die Helden hier. Wann auch immer es um die Zukunft geht, verschieben sie das Gespräch auf morgen. Sie möchten die Gegenwart meistern. Die Vergangenheit überwinden. Und erst dann sehen wir weiter.
Passend dazu stellt der Film auch die morbide Faszination der Spanier mit dem Tod dar, vor allem in den kleinen Orten. Aber warum das Bild mit den Windmühlen? Teilweise wurde es in der Mancha aufgenommen, wo auch ein anderer Held, der mit Windmühlen zu tun hatte, herstammt. Doch scheint mir, rennt in diesem Film keiner gegen Windmühlen an. Bei solchen Szenen habe ich immer das Gefühl, etwas verpasst zu haben. Na was soll's, der Film war auch so schön genug.
Drama. Komplizierte Familienkiste, bei der der nächste Schritt ein wenig zu leicht zu durchschauen ist (aber das ist ja bei jeder realistischen Familienkiste so), dafür aber der übernächste Schritt meist noch eine Überraschung bereithält. Sehenswert.
ACM Review II
Thanks to Mary-Lynn Bragg for answering my complaint about non-accessible reviews so quickly. She sent me the review to read, and I was quite happy with it. Michael Lesk, one of the guys who built Unix, wrote the review, and recommended it to "designers of volunteer or collaborative systems and [...] those studying cooperative work." Thanks, Michael, thanks Mary-Lynn.
Sooo -- read our straightforward and easy to read paper! :)
By the way -- I still think ACM Computing Reviews should offer their reviews for free to the public. This would increase the impact of their reviews dramatically, and also the impact of the reviewed papers.
Schlagzeuger sind ersetzlich
Durch Maschinen. Diese Studie zeigt eine solche Möglichkeit.
Im ernst, wer Percussion mag, wird sicher dieses Video sehr cool finden. Und wer Musik mag auch. Oder Computerzeichentrick. Ich habe gelesen, dass das Programm, welches das Video erzeugt hat, ein beliebiges Midi reinladen konnte. Man musste dann nur noch die Kameraschwenks und Perspektiven bestimmen. Wow.
Weitere solche Videos bei Google. Die Animusic DVD gibt es auch, in deutlich besserer Qualität, zu kaufen.
Besser spät als nie
Auch ich fang das Stöckchen. Wenn auch spät.
Warum bloggst du?
Weil ich manchmal glaube, etwas sagen zu können, das unterhält, nachdenken lässt, erinnert, berührt, zum lachen bringt, informiert, oder auch einfach nur die Zeit etwas angenehmer vorbeigehen lässt.
Seit wann bloggst du?
Nodix gibt es seit dem 15. Januar 2001. Das erste Mal, dass ich das ganze einen Blog nannte, und auch das Aussehen der Seite den üblichen Blogstandards anpasste, war erst am 21. August 2002, als die ersten 10000 Besucher zusammengekommen waren.
Selfportrait?
Eingebildet (glaubt, gut zu sein), verrückt (Arbeitet auch am Wochenende, und hat Spaß dabei), sich in Details verlierend (und dadurch nicht das tun, was er tun sollte), großspurig (die Menschheit retten wollen, und auch zu glauben, es zu können), dickköpfig (lässt sich schwer umüberzeugen), alles machen wollen (und auch von anderen das selbe verlangen), zu selten das Partizip benutzen (es sollte benutzend heißen), und Wikipedianer (behauptet zumindest die Wikipedia).
Ansonsten findet sich unter Denny eine bessere Beschreibung.
Warum lesen Deine Leser Deinen Blog?
Weil ich hin und wieder das schaffe, was ich in Punkt 1 schreibe. Außerdem schreibe ich so selten, dass die meisten Leser dafür nicht sonderlich viel Zeit brauchen.
Welche war die letzte Suchanfrage, über die jemand auf Deine Seite kam?
Das finde ich aber sehr erfreulich: sucht man bei Google.de nach gutem Karma, kommt man zu mir (Platz 3!)
Welcher Deiner Blogeinträge bekam zu Unrecht zu wenig Aufmerksamkeit?
Oh, ich dachte nicht dass Blogeinträge ein Recht auf Aufmerksamkeit haben. Aber wenn man mich so fragt... dass Männer schlauer als Frauen sind, wurde in diesem Blog schon behauptet, mit eben so viel Recht. Ansonsten schlägt auch das Risiko Alter in eine ähnliche Kerbe. Und dann bleibt noch mein liebster Blogeintrag, über das Pendeln.
Dein aktuelles Lieblings-Blog?
nakit-arts. Oh, ich meine be croative!. Da bleibe ich auf dem Laufenden, was daheim passiert, auch wenn ich nicht daheim bin.
An welche vier Blogs wirfst du das Stöckchen weiter und warum?
Uh, ich glaube, Blogger, die ich kenne, haben das Stöckchen schon gefangen. Ich werfe die jetzt einfach mal in die Luft, mal sehen, wer fängt! Linkt hierher, wenn ihr das Stöckchen gefangen habt!
Wikimania 2006 is over
And it sure was one of the hottest conferences ever! I don't mean just because of the 40°C/100°F that we had to endure in Boston, but also because of the further speakers there.
Brewster Kahle, the man behind the Internet Archive, and who started Alexa and WAIS Inc., told us about his plans to digitalize every book (just a few Petabytes), every movie (just a few Petabytes), every record (just a... well, you get the drill), and to make a snapshot of the web every few months, and archive this. Wow.
Yochai Benkler spoke about the Wealth of Networks. You can download his book from his site, or go to a bookstore and get it there. The talk was really inviting to read it: why does a network thingy like Wikipedia work and not suck? How does this change basically everything?
Next day, there was Mitch Kapor, president of the Open Source Application Foundation -- and I am really sorry I had to miss his talk, because at the same time we were giving our workshop on how to reuse the knowledge within a Semantic MediaWiki in your own applications and websites. Markus Krötzsch, travel companion and fellow AIFB PhD student, and basically the wizard who programmed most of the Semantic MediaWiki extension, totally surprised me by being surprised about what you can do with this Semantic Web stuff. Yes, indeed, the idea is to be able to ask another website to put stuff up on yours. And to mush data.
There was David Weinberger, whose talk made me laugh more than I had for a while (and I am quite merry, usually!). I still have to rethink what he actually said, contentwise, but it made a lot of sense, and I took some notes, it was on the structure of knowledge, and how it changes in the new world we are living in.
Ben Shneiderman, the pope on visualization and User Interfaces had an interesting talk on visualizing the Wikipedia. The two talks before his, by Fernanda Viegas and Martin Wattenberg, were really great, because they have visualized real Wikipedia data -- and showed us a lot of interesting data. I hope their tools will become available soon. (Ben's own talk was rather a bit disappointing, as he didn't seem to have the time to take some real data, but only used fake data to show some general possible visualizations. As i had the chance to see him in Darmstadt last year anyway, I didn't see much new stuff).
The party at the MIT Museum was great! Even though I wasn't allow to drink, because I forgot my ID. I'd never think anyone would consider me looking younger than 21. So I take this as the most sincere compliment. Don't bother explaining they had to check my ID even if I looked 110, I really don't want to hear :) I saw Kismet! Pitily, he was switched off.
Trust me. I was kinda tired after this week. It was lots of fun, it was enormously interesting. Thanks to all the Wikipedians, who made Wikipedia and Wikimania possible. Thanks to all these people for organizing this event and helping out! I am looking forward to Wikimania 2007, wherever it will be. The bidding for hosting Wikimania 2007 are open!
Angeblich kritisch
Die Geschichte von Epic. Der Film ist schon etwas älter (äh, 2005?), jetzt aber endlich in einer hervorragenden deutschen Übersetzung zu haben.
Es geht darum, wie sich das Internet weiterentwickeln könnte. Eine recht spannende Version.
ACM Review
ACM Computing Reviews reviewed our paper on the Semantic Wikipedia. Yay! Pitily, I can't read the review because I need a login.
Would love to see what they're saying, but I guess it's not meant to be open to the public. Or to the authors.
Maybe the hottest conference ever
The Wikipedia Hacking Days are over. We have been visiting Siggraph, we had a tour through the MIT Media Lab, some of the people around were Brion Vibber (Wikimedia's CTO), Ward Cunningham (the guy who invented wikis), Dan Bricklin (the guy who invented spreadsheets), Aaron Swartz (a web wunderkind, he wrote the RSS specs at 14), Jimbo Wales (the guy who made Wikipedia happen), and many other people. We have been working at the One Laptop per Child offices, the office to easily the coolest project of the world.
During our stay at the Hacking Days, we had the chance to meet up with the local IBM Semantic Web dev staff and Elias Torres, who showed us the fabulous work they are doing right now on the Semantic Web technology stack (never before rapid application deployment was so rapid). And we also met up with the Simile project people, where we talked about connecting their stuff like Longwell and Timeline to the Semantic MediaWiki. We actually tried Timeline out on the ISWC2006 conference page, and the RDF worked out of the box, giving us a timeline of the workshop deadlines. Yay!
Today started Wikimania2006 at the Harvard Law School. was not only a keynote by Lawrence Lessig, as great as expected, but also our panel on the Semantic Wikipedia. We had an unexpected guest (who didn't get introduced, so most people didn't even realize he was there), Tim Berners-Lee, probably still jetlagged from a trip to Malaysia. The session was received well, and Brion said, that he sees us on the way of getting the extension into Wikipedia proper. Way cool. And we got bug reports from Sir Timbl again.
And there are still two days to go. If you're around and like to meet, drop a note.
Trust me — it all sounds like a dream to me.
At Wikimania 2006
I am here in Boston now, walking the sacred grounds of Harvard and MIT, and listening and talking with the great people who created the MediaWiki software that runs Wikipedia. At Thursday, Markus and I will host the Semantic Wikipedia panel, where we present the state of our implementation, and talk about how to make it real. We also have a tutorial on Sunday, about how to reuse knowledge from a Semantic MediaWiki.
If you're around Boston, MIT, Harvard, or if you even attend Wikimania and the Hacking Days, and want to meet -- contact me!
An wen...
...erinnert mich nur dieser Chatbot?
ESWC2006 is over
I have been the week in Budva, Montenegro, at the ESWC2006. It was lovely. The keynotes were inspiring, the talks had a good quality, and the SemWiki workshop was plain great. Oh, and the Semantic Wikipedia won the best poster award!
But what is much more interesting is the magic that Tom Heath, the Semantic Web Technologies Co-ordinator, managed: the ESWC website is a showcase of Semantic Web technologies! A wiki, a photo annotation tool, a chat, a search, a bibliography server, a rich semantic client, an ontology, the award winning flink... try it out!
Now I am in Croatia, and taking my first real break since I started on the Semantic Web. Offline for three weeks.
Yay.
Daheim
Nach einer Woche in Montenegro bin ich jetzt in Kroatien angekommen. Und genieße.
Offline.
OWL luna, nicer latex, OWL/XML to Abstract Syntax, and more
After a long hiatus, due to some technical problems, finally I could create a new version of the owl tools. So, version 0.27 of the owl tools is now released. It works with the new version of KAON2, and includes six months of bug fixing, but also a number of new features that have introduced a whole new world of new, exciting bugs as well.
The owl latex support was improved greatly. Translation of an owl ontology is done now more careful, and the user can specify much more of the result than before.
A new tool is owl luna - luna like local unique name assumption. It adds an axiom to your ontology that states that all individuals are different from each other. Due to most ontology editors not allowing to do this automatically, here you find a nice maintenance tool to make your ontology much less ambiguous.
The translations of OWL/RDF to OWL/XML and back have been joined in one new tool, called owl syntax, that allows you to translate owl ontologies also to OWL Abstract Syntax, a much nicer syntax for owl ontologies.
owl dlpconvert has been extended as it now also serialzes it results as RuleML if you like. So you can just pipe your ontologies to RuleML.
So, the tools have both become sharper and more numerous, making your toolbelt to work with owl in daily life more usable. Get the new owl tools now. And if you peek into the source code, the code has underwent a major clean up, and you will also see the new features I am working on, that have to do with ontology evaluation and more.
Have fun with the tools! And send me your comments, wishes, critiques!
Weltuntergang
Gestern war der 6.6.6.
Und die Welt ist doch nicht untergegangen. Da muss für so manchen Zahlenmystiker die Welt untergegangen sein.
(Übrigens war schon zum zweiten Mal der 6.6.6. Vor 1000 Jahren hat das mit dem Weltuntergang auch nicht geklappt.)
WWW2006 social wiki
The WWW2006 conference next week has a social wiki. So people can talk about evening activities, about planning BOF-Sessions, about their drinking habits. If you're coming to the conference, go there, make a page for yourself. I think it would be fun to capture the information, and to see how much data we can get together... data? Oh, yes, forgot to tell you: the WWW2006 wiki is running on Semantic MediaWiki.
Yay!
Let's show how cool this thing can get!
Semantic Mediawiki 0.4 - Knowledge Inside!
Until now, Semantic MediaWiki was kind of a nerds project. Yes, you could get a lot of information out in RDF, and actually, I used it as an RDF editor more than once -- but heck, what normal person needs that?
Now, with the freshly implemented feature, the advantages of a Semantic MediaWiki over a normal MediaWiki should become obvious: you can simply ask the wiki for stuff! Wiki, what are the 10 biggest city in the US? Put a list here. Or, wiki, what is the height of the current German chancellor? Put the info here. I have made a writeup on those inline queries on our demo wiki. Go there, read it.
But a lot of other things made it into the 0.4 release. Here's Markus' list:
- Improved output for Special:Relations and Special:Attributes: usage of
- relations and attributes is now counted
- Improved ontology import feature, allowing to import ontologies and to update existing pages with new ontological information
- Experimental suport for date/time datatype
- More datypes with units: mass and time duration
- Support for EXP-notation with numbers, as e.g. 2.345e13. Improved number formating in infobox.
- Configurable infobox: infobox can be hidden if empty, or switched off completely. This also works around a bug with MediaWiki galeries.
- Prototype version of Special:Types, showing all available datatypes with their names in the current language setting.
- "[[:located in::Paris]]" will now be rendered as "located in [[Paris]]"
- More efficient storage: changed database layout, indexes for fast search
- Code cleaned up, new style guidelines
- Bugfixes, a lot of Bugixes
Thanks to everyone who contributed and still contributes to the project! And, connected to this, thanks to the answers to my last blog entry -- I will write more on this tomorrow.
Need help with SQL
But I have no time to write it down... I will sketch my problem, and hopefully get an answer (I've started this blog in the morning, and now I need to close it, cause I have to leave).
Imagine I have following table (a triple store):
| Subject | Predicate | Object |
|---|---|---|
| Adam | yahoo im | adam@net |
| Adam | skye | adam |
| Berta | skype | berta |
How do I make a query that returns me the following table:
| Subject | o1 | o2 |
|---|---|---|
| Adam | adam@net | adam |
| Berta | - | berta |
The problems are the default value in the middle lower cell. The rest works (as maybe seen in the Semantic Mediawiki code, file includes/SMW_InlineQueries.php -- note that the CVS is not up to date for now, because SourceForge's CVS is down for days!)
It should work in general, with as many columns as I like on the answer table (based on the predicates in the first one).
Oh, and if you solved this -- or have an idea -- it would be nice if it worked with MySQL 4.0, i.e. without Subqueries.
Any ideas?
Rom mit vielen Gesichtern
Man läuft durch Rom, und man sieht, es ist die Stadt der Päpste. Überall finden sich gigantische Marmorplatten, auf denen erklärt wird, dass diese(r/s) Platz / Kirche / Gebäude / Monument / Brunnen / Brücke von Seiner Heiligkeit, P.M. (nicht etwa Prime Minister, sondern Pontifex Maxmimus) Soundso dem Sounsovielten gemacht wurde, im Jahre 12. Das heißt natürlich nicht etwa, dass das Ding knapp 2000 Jahre alt ist, sondern bezeichnet das 12. Jahr seines Papstseins. Es gibt sogar eine riesige Platte auf dem McDonalds gegenüber vom Pantheon, die auf -- Erinnerung ist schwach -- glaube Leo XII. verweist. Das Mc-Symbol ist da deutlich dezenter. Wieviele Fastfoodketten haben das noch?
Dann läuft man weiter, und entdeckt auch, dass Rom die Stadt eines antiken Imperiums ist. Das Kollosseum (gigantisch!), das Forum Romanum, das Pantheon natürlich, das Mausoleum von Kaiser Hadrian, heute Castel St Angelo, die Statuen überall. Atemberaubend.
Dann läuft man weiter, und entdeckt dass es auch die Stadt Berninis, der die Stadt in der Renaissance wieder wachküsste, und sie in eine Stadt der Brunnen verwandelte. Überall fließt Wasser, wohlgemerkt, allesamt Trinkwasser, was vor allem an den heißeren Tagen sehr beliebt ist, das Plätschern, die wunderschönen Parkanlagen (wirklich atemberaubend mit ihren künstlichen Seen und natürlichen Hügeln, und darauf die jahrhundertealten Bäume).
Und dann läuft man weiter, und man sieht, dass es auch die Stadt der Regierung eines modernen Italiens ist. Der Palast des Präsidenten, mit den wohl coolsten Wächteruniformen überhaupt (vergesst die Uniformen der Schweizer Garde, die von einem gewissen Michelangelo designt wurden). Lange, wehende Mäntel, große blitzende Knöpfe, und ein Ritter, der im Eingang steht, weit hinten, im Dunkeln, und sich nie bewegt, auf sein Schwert gestützt, mit einem großen Helm. Denke nicht, dass er gegen einen Bewaffneten mit 'ner Schusswaffe auch nur den Hauch einer Chance hätte, aber er sieht so morsmäßig cool aus!
Und schließlich, nach dem vielen Gelaufe, wird es dunkel, und dann merkt man, dass Rom auch eine Stadt der jungen Leute ist, mit unzähligen Kleinen und manchen Großen Bars, und viel Leben auf der Straße. Rom hat unglaublich viele Gesichter, aber ich nehme an, in einer Stadt mit 2800 Jahren Geschichte sammelt sich halt mit der Zei was an...
Semantic Web Summer School 2006
The Summer School for the Semantic Web and Ontological Engineering is an annual event that brings together PhD students from all over the world and some of the brightest heads in the Semantic Web, to teach, to socialize, to learn, and to have fun. This year's invited speakers are Jim Hendler himself, and Enrico Motta, Stephan Baumann, Guus Schreiber, and the tutors are John Domingue, Asun Gomez-Perez, Jerome Euzenat, Sean Bechhofer, Fabio Ciravegna, Aldo Gangemi. You will learn a lot. You will have lots of fun. The place is really beautiful, the girls, well at least last year, were really beautiful, the stuff we learned was interesting, and inspired quite some cooperation further on. And it's really great for getting to know a lot of people: at the next conference you're guaranteed to meet someone again, and thus it is also a perfect possibility ot get into the community.
The deadline is May 1st, so be sure to go over to the SSSW2006 website and sign up.
If this didn't convince you, take a look at my series of posts about last year's summer school.
Research visit
So, I have arrived for my very first longer research visit. I am staying at the Laboratory of Applied Ontologies in Rome. I have never been to Rome before, and all my type of non-work experience I'll chat about in my regular blog, in German. Here I'll stick to Semantic Stuff and such.
So, if you are nearby and would like to meet -- give me a note! I am staying in Rome up to the WWW, i.e. up to May 20th. The plan is to work on my dissertation topic, Ontology Evaluation, especially in the wake of the EON2006 workshop, but that's not all it seems. People are interested in and knowledge about Semantic Wikis as well. So there will be quite a lot stuff happening in the next few weeks -- I'm excited about it all.
Who knows what will happen? If my plan works out, at the end of the stay we will have a common framework for Ontology Evaluation. And I am not talking about this paper frameworks -- you know, that are presented in papers with titles starting "Towards a..." or "A framework for...". No, but real software, stuff you can download, and play with.
Preisschock
Innerlich beschwerte ich mich über das teure Zimmer. Gestern erfuhr ich, wieviel es eigentlich kostet -- schlappe 165 Euro pro Nacht. Das Ding ist winzig! Nein, versteht mich nicht falsch -- die Leute sind echt nett, es ist gemütlich, es ist sauber, es ist hervorragend gelegen. Aber 165 Euro pro Nacht für nichtmal 8 Quadratmeter, inklusive Badezimmer und Wandschrank? Ich meine, 1 Euro pro Stunde und Quadratmeter?
Dann bin ich lieber ruhig und bedanke mich für den Preis, den mein Gastgeber am Institut mir organisiert hat.
Ankunft
Ich hoffe, der Steuerzahler weiß zu schätzen, dass ich mich gestern für ihn richtig aufgeopfert habe. Wie gesagt, das Hotel hatte mir angeboten, mich mit einer Limo vom Flughafen abzuholen, mit Schildchen, wo mein Name draufsteht usw., das ganze Programm.
Das kostete mir zuviel, also fuhr ich mit der Bahn zum Römischen Hauptbahnhof Termini. Von dort hätte ich ja auch ein Taxi nehmen können - doch, woran erkennt man in Rom die legalen Taxis? Und um Termini herum, so heißt es, sei das schlechte Viertel von Rom.
Also ab in die Metro (übersichtlich, zwei Linien, ein Ost-West (blau) und eine Nord-Süd (rot), zwei Haltestellen) und dann zu Fuß weiter. Auf der Karte sah das nach etwa einem Kilometer aus, also solte es doch kein Problem sein. Mein Gedächtnis ließ mich nicht im Stich, den Weg fand ich.
Nur ein Kilometer ist mir 30 Kilo Gepäck doch deutlich weiter als gedacht... und das war auf der Karte nicht eingezeichnet. Ich brauchte für die Strecke tatsächlich eine Stunde, mein Rücken tat weh, meine Handflächen brannten, ich war durstig und kaputt. Ohne Handschuhe hätte ich mir die Hände wundgescheuert. Immerhin, das Wetter war angenehm kühl, schattig und windig.
Dafür schlief ich zunächst mal 12 Stunden durch. Wow. Mache ich sonst nie. Jetzt bin ich erholt und bei der Arbeit. Und es macht Spaß.
Abflug
Ich habe Schwesterchen versprochen, regelmäßig aus Rom zu berichten. Wobei ich noch keine Ahnung habe, wie ich in Rom überhaupt verbunden sein werde, mit dem Netz.
Aber von vorne -- warum verschlägt es mich überhaupt in die Ewige Stadt? Es geht dabei um das Thema meiner Doktorarbeit, herauszufinden, was eine gute Ontologie ist. Zugegeben, ich weiß erst seit kurzem, was eine Ontologie überhaupt ist -- und jetzt will ich wissen, wann eine gut ist und wann nicht? Soviel zu hohen Zielen. Jedenfalls gibt es weltweit nicht so wahnsinnig viele Experten auf diesem Gebiet, und einer davon -- der geneigte Leser wird es sicher bereits erahnen -- sitzt in Rom.
So jedenfalls kommt es, dass ich für ein paar Wochen nach Rom fahre, und wir zusammen an diesem Thema arbeiten werden. Die Arbeitsergebnisse werden sich auf Semantic Nodix finden, hier hingegen private Eindrücke und Erlebnisse.
Wie zum Beispiel, dass ich furchtbar nervös bin. Ich realisierte, dass ich noch nie so lange weg von daheim war (wobei ich großzügig daheim als sowohl Stuttgart als auch Brač zähle). Aber ich freue mich auch sehr darauf. Ich war noch nie in Rom. Und kann kein Italienisch. Aber ich habe mir auf Wikitravel schon zahlreiche Informationen über Rom eingeholt, also kann auch gar nichts schief gehen. Da habe ich etwa erfahren, dass der Bahnhof Termini, an dem ich ankomme, berühmt für seine hohe Kriminalität ist. Und dass der Flughafen Leonardo da Vinci zu weit weg ist, um ein Taxi zu nehmen. Das Hotel hat mir jedenfalls einen Limousinenservice angeboten, für läppische 55 €. Habe ich dann doch abgelehnt, mit dem Zug kostet es nur Neuneinhalb. Und es gibt auch, so wie in Sofia, betrügerische Taxen, die ohne Lizenz und zu horrenden Preisen fahren. Oder man wird von Horden von Kindern angefallen, die einem dann die Geldbörse entwenden. Bester Trick: nicht wie ein Tourist aussehen. Stelle ich mir schwierig vor, wenn ich gerade mit Rucksack und zwei Koffern ankomme.
So, wie gesagt, da ich nun informiert bin, kann ich ja ganz beruhigt hinfahren. Es wird sicher sehr schön.
Semantic Mediawiki 0.3
Yay! Markus "the Sorcerer" Krötzsch finished the new release of Semantic MediaWiki today. The demo website is already running version 0.3 for a while.
I'll let Markus speak:
I am glad to finally announce the official release of Semantic MediaWiki 0.3, available as usual at http://sourceforge.net/projects/semediawiki/. The final 0.3 is largely equivalent to the preview version that is still running on wiki.ontoworld.org -- the latest changes mainly concern localization.
Semantic MediaWiki 0.3 now runs on MediaWiki 1.6.1 that was released just yesterday. Older versions of MediaWiki should also work but upgrading is generally recommended.
The main new features of 0.3 are:
- support for geographical coordinates (new datatype),
- improved user interface: service links for JScript tooltips, CSS layout,
- OWL/RDF export of all annotation data,
- simplified installation process (including special page for setup/upgrade),
- (almost) complete localization; translations available for English and German,
- better MediaWiki integration: namespaces, user/content language, support for MediaWiki 1.6,
- specials for displaying all relations/attributes,
- experimental (OWL/RDF) ontology import feature,
- and, last but not least, we also fixed quite some bugs.
The next steps towards 0.4 will probably be the inclusion of query results into existing pages, date/time support, and individual user settings for displaying certain datatypes. We also will have another look at ways of hiding the annotations from uninitiated users.
Have fun.
Markus
P.S.: I am not available during the weekend. Upgrading existing wikis should work (it's what we do all the time ;), but be aware that there is not going to be much support during the next three days.
CeBIT
Am Wochenende war ich auf der CeBIT arbeiten. Wir stellten am Stand des BMBF Ergebnisse des AIFB vor. Einige interessante Besucher dagehabt, aber auch am Sonntag die Chance genutzt, ein wenig über die Messe zu wandern. Ich war zum ersten Mal da.
Zunächst mal: riesig groß, mit viel, viel, richtig viel freie Fläche zwischen den Messehallen. Ich meine, schaut es euch selber an. Und von der Expo 2000 sind noch ein paar nette Gebäude übrig geblieben. Groß heißt aber auch weite Wege. Meine Füße...
Und, was gab es cooles? Nein, ich werde jetzt nicht über die ganzen Semantischen Technologien reden, die es auf der CeBIT gab (Semantic Talk, oder Gnowsis, oder, halt uns), sondern drei andere Impressionen.
Erstens: Demo von Windows Vista gesehen. Positiv überrascht. Nicht nur dass es fast so cool wie MacOS X aussieht, die Metadatenfähigkeit wirkt auch überraschend zugänglich. Aber dennoch, das neu Interface ist echt fesch.
Zweitens: einen 102" Flachbildschirm gesehen. Wow. Und darauf lief der Trailer für X-Men 3. Doppelwow. Ich weiß gar nicht was jetzt cooler war.
Drittens: neben uns saßen Forscher vom Fraunhofer, die das AMI Projekt vorstellten. Eines der Projektergebnisse war eine Kamera, die alle Teilnehmer eines Meetings aufnimmt. Sie findet dabei automatisch die Gesichter in einem Bild, und insbesondere ob sie gerade sprechen, ob sie lächeln, nicken, etc. Sie hatten zur Demonstration vier Plüschtiere zum Meeting hingesetzte, und an dreien wurde auch zuverlässig das Gesicht entdeckt. Am vierten nicht -- ein nachtschwarzer Maulwurf. Da fragte ich, ob es denn auch bei unterschiedlichen Hautfarben klappe, wie eben etwa bei schwarzer Haut. Ja, überhaupt kein Problem, es ist sogar einfacher mit Menschen als mit dem ganzen Plüschzeug, weil Menschen alle die selbe Hautfarbe haben. Nur die Intensität sei unterschiedlich. Aber die Farbe, die ist bei allen gleich.
Was man mit Computern alles lernen kann.
Good ontologies?
We have asked you for your thoughts and papers. And you have sent us those -- thank you! 19 submissions, quite a nice number, and the reviewing is still going on.
Now we ask you for your results. Apply your evaluation approaches! We give you four ontologies on the EON2006 website, and we want you to take them and evaluate them. Are these ontologies good? If they are, why? If not, what can be changed? We want practical results, and we want to discuss those results with you!. So we collected four ontologies, all talking about persons, all coming from very different background and with different properties. Enough talking -- let's get down and make our hands dirty by really evaluating these ontologies.
The set is quite nice. Four ontologies. One of them we found over rdfdata.org, a great resource for ontologies, some of them I would have never found myself. We took a list of Elvis impersonators. One person edited the ontology, it is about a clear set of information, basically RDF. The second ontology is the ROVE ontology about the Semantic Web Summer School in Cercedilla last year. It was created by a small team, and is richly axiomatized. Then there is the AIFB ontology, based on the SWRC. It is created out of our Semantic Portal in the AIFB , and edited by all the members of the AIFB -- not all of them experts in the SemWeb. Finally, there's a nice collection of FOAF-files, taken from all over the web, and to be meshed up together and evaluated as one ontology, created with a plethora of different tools, by more than a hundred persons. So there should be an ontology fitting to each of the evaluation approaches.
We had a tough decision to make when choosing the ontologies. In literally the last moment we got the tempting offer to take three or four legal ontologies and to offer those for evaluation. It was hard, and we would have loved to put both ontology sets up to evaluation, but finally decided for the set mentioned previously. The legal ontologies were all of similar types, and certainly would need a domain expert for proper evaluation, which many of the evaluators won't have at hand at the moment. I hope it is the right decision (in research, you usually never know).
The EON2006 workshop will be a great opportunity to bring together all people interested in evaluating ontologies. I read all the submissions, and I am absolutely positive that we will be able to present you with a strong and interesting programme soon. I was astonished how many people have interest in that field, and was intrigued to discover and follow the paths lead out by the authors. I am looking forward to May, and the WWW!
Visa haben ungleich Visa brauchen
Als ich vor ein paar Wochen in Dortmund war, um mein Visum für Großbritannien zu beantragen, hatte ich ja eines für 5 Jahre beantragt und eines für 2 bekommen. Da habe ich schon gehofft, dass es das letzte Visum für Großbritannien sei, dass ich beantrage, und dass bis zum Ablauf desselben Kroatien Teil der Europäischen Union sein werde.
Mit einem Punkt hatte ich schon mal Recht -- Großbritannien schafft mit Wirkung zum 22. März die Visumspflicht für Kroaten ab. Das mein schönes Visum bis 2008 Gültigkeit hat ist dadurch natürlich vollkommen irrelevant geworden.
Menno, das haben die doch absichtlich gemacht.
Die GUI - XUL, HTML und CSS
Das Herzstück von Mozilla ist die Renderingengine Gecko. Sie liest zum Beispiel (X)HTML ein und stellt dieses dann auf dem Monitor dar. Damit lassen sich bereits sehr interaktive und sich äußerst dynamisch anfühlende Webseiten erstellen, insbesondere wenn man JavaScript mit verwendet. An Beispielen wie GMail oder start.com kann man erkennen, wieviel heute schon mit HTML möglich ist. Dennoch: viele GUI-Elemente wie Listen, Menüs oder Knöpfe sind in HTML eher umständlich umgesetzt. Darum wurde XUL, die XML User Interface Language, eingeführt, eine XML-Sprache zur Beschreibung von graphischen Benutzerschnittstellen.
Mit XUL ist es dann möglich zu beschreiben, wo bestimmte Elemente auftauchen, welche wo auftauchen, etc. Dadurch wird es zum Beispiel leicht fallen, verschiedene Versionen der GUI zu erstellen, eine für Experten und eine für Anfänger. Insbesondere könnte man sich einen Schritt-für-Schritt-Wizard für die Heldenerschaffung vorstellen, wie sie in den meisten anderen Editoren wie Helden praktiziert wird. Meine persönliche Vorliebe bleibt dennoch beim "Immer alles veränderbar"-Modus. Aber die Codebasis wird sehr einfach beides hergeben.
Ein weiterer Vorteil von XUL ist, dass damit das User Interface interpretiert, nicht compiliert wird. Das hat den Vorteil, dass, wenn man das Aussehen des Programms verändern will, man nicht eine ganze Programmierumgebung mit Compiler etc. braucht, sondern einfach nur einen Texteditor und etwas XML- oder HTML-Kenntnisse. Hoffnung dabei: schöne neue Skins und bessere Bedienbarkeit können von wesentlich mehr Leuten beigesteuert werden als bisher.
Apropos Skins: ja, auch das wird möglich sein. Wie von Thunderbird und Firefox gewohnt, sind XUL-basierte Anwendung vollkommen mit CSS und ähnlichem skinbar. Das heißt Farben, Hintergründe, Aussehen der Elemente sind steuerbar. Ich stelle mir jetzt schon ein Horasreich-Skin, ein Myranor-Skin und ein G7-Skin vor. Mal sehen. Es wird letztlich von Eurer Kreativität abhängen.
Auch hier ist das wichtige: man muss dafür keine Programmierumgebung besitzen und keine Programmierkenntnisse haben (auch wenn sie natürlich nicht schaden). Der wichtigste Teil des neuen Designs ist es, die einzelnen Teile der Architektur orthogonal zu gestalten, so dass man an einem bestimmten Teil arbeiten kann, ohne das man ein Experte in allen sein muss. Etwas, was bei der ersten Version sträflichst vernachlässigt wurde.
Nächstes Mal: zum Datenmodell und der Datenhaltung.
EON2006 deadline extension
We gave the workshop on Evaluating Ontologies for the Semantic Web at the WWW2006 in Edinburgh an extension to the end of the week, due to a number of requests. I think it is more fair to give an extension to all the authors than to allow some of them on request and to deny this possibility to those too shy to ask. If you have something to say on the quality of ontologies and ontology assessment, go ahead and submit! You still have a week to go, and short papers are welcomed as well. The field is exciting and new, and considering the accepted ESWC paper the interest in the field seems to be growing.
A first glance of the submissions reveals an enormous heterogeneity of methods and approaches. Wow, very cool and interesting.
What surprised me was the reaction of some: "oh, an extension. You didn't get enough submissions, sorry". I know that this is a common reason for deadline extensions, and I was afraid of that, too. A day before the deadline there was exactly one submission and we were considering cancelling the workshop. It's my first workshop and thus such things make me a whole lot nervous. But now, two days after the deadline I am quite more relaxed. The number of submissions is fine, and we know about a few more to come. Still: we are looking for more submissions actively. For the sole purpose of gathering the community of people interested in ontology evaluation in Edinburgh! I expect this workshop to become quite a leap for ontology evaluation, and I want the whole community to be there.
I am really excited about the topic, as I consider it an important foundation for the Semantic Web. And as you know I want the Semantic Web to lift off, the sooner the better. So let's get these foundations right.
For more, take a peek at the ontology evaluation workshop website.
Zurück aus Sheffield
Was wirklich gemein ist: die ganze Zeit in Sheffield hat es geregnet und gewindet. War ja nichts anders zu erwarten in England, oder?
Aber heute, da ich zurück bin, ist es dort über 10 Grad wärmer als hier, und sie haben Nieselregen und Sonnenschein statt Schnee und Grauingrau.
Die gute Nachricht: der Vortrag ist phantastisch gelaufen, das ganze Review war ein großer Erfolg. Danke allen Daumendrückern. Und danke den nutkidz, die ebenfalls eine Rolle spielten. Mehr dazu bald.
My Erdös Number
After reading a post by Ora and one by Tim Finin, I tried to figure my own Erdös Number out. First, taking Ora's path, I came up with an Erdös of 7:
Paul Erdös - Stephan Hedeniemi - Robert Tarjan - David Karger - Lynn Stein - Jim Hendler - Steffen Staab - Denny Vrandečić
But then I looked more, and with Tim's path I could cut it down to 6:
Paul Erdös - Aviczir Fraenkl - Yaacov Yesha - Yelena Yesha - Tim Finin - Steffen Staab - Denny Vrandečić
The point that unnerved me most was that the data was actually there. Not only a subscription-only database for mathematical papers (why the heck is the metadata subscription only?), but there's DBLP, there's the list of Erdös 1 and 2 people on the Erdös Number project, there's Flink, and still, I couldn't mash up the data. This syntactic web sucks.
The only idea that brought me further - without spending even more time with that - was a Google search for "my erdös number" "semantic web", in the hope to find some collegues in my field that already have found and published their own Erdös number. And yep, this worked quite fine, and showed me two further, totally disjunctive paths to the one above:
Paul Erdös - Charles J. Coulborn - A. E. Brouwer - Peter van Emde Boas - Zhsisheng Huang - Peter Haase - Denny Vrandečić
and
Paul Erdös - Menachem Magidor - Karl Schlechta - Franz Baader - Ian Horrocks - Sean Bechhofer - Denny Vrandečić
So that's and Erdös of 6 on at least 3 totally different paths. Nice.
What surprises me - isn't this scenario obviously a great training project for the Semantic Web? Far easier than Flink, I suppose, and still interesting for a wider audience as well, like Mathematicians and Noble Laureates? (Oh, OK, not them, they get covered manually here).
Update
I wrote the post quite a time ago. A colleague of mine notified me in the meantime that I have a Erdös of only 4 by the following path:
Paul Erdös - E. Rodney Canfield - Guo-Quiang Zhang - Markus Krötzsch - Denny Vrandečić
Wow. It's the social web that gave the best answer.
2019 Update
Another update, after more than a dozen years: I was informed that I have now an Erdös number of 3 by the following path:
Paul Erdös - Anthony B. Evans - Pascal Hitzler - Denny Vrandečić
I would be very surprised if this post requires any further updates.
In Sheffield
Die Stadt aus Stahl. Sheffield ist eine überraschend große Stadt, knapp 520.000 Einwohner und damit die viertgrößte Stadt in Großbritannien. Steht aber weder auf den Wetterkarten, noch hat es einen Flughafen. Es hat nichtmal eine vernünftige Verbindung zum nächsten Flughafen. Wir fuhren über eine Stunde den Snake Pass entlang, eine Strecke mit einer angeblich wunderschönen Aussicht. Es war Nacht.
Ich mach selber ja keine Photos, darum hier die Photos bei Flickr zu der Stadt. Auch auf Google Maps konnte ich das Octogon gegenüber finden. Ist ziemlich cool.
Zur Zeit sitze ich im großen Review unseres Projektes zu Semantischen Technologien. Die EU entscheidet, ob ihr Geld gut ausgegeben war. Ich bin nervös, und habe heute Nachmittag meinen Vortrag. Mit den nutkidz auf den Folien.
Drückt mir die Daumen.
Ungeschick
Neid auf Freiheit
"Vielleicht klang auch etwas Neid auf euch durch, da die Form von Meinungsäußerung, die ich als Werbetexter seit über 30 Jahren betreibe, alles andere als frei ist: Jedes Wort wird vor der Veröffentlichung lange abgewogen, mit Auftraggebern verhandelt und dann noch repräsentativ auf seine Wirkung getestet." (Quelle)
Jean-Remy von Matt hatte in einer internen eMail, die an die Blogosphäre durchgesickert ist, sich über die Miesepetrigen beschwert, die alles schlecht machen. "Wer hat die denn gefragt?" -- eines der Argumente. Was hörst Du dann hin?, frage ich mich. Wie auch immer, es war eine impulsive Reaktion. Seine, und die Arbeit seiner Kollegen, wurde niedergemacht, und er ärgerte sich. Da soll sich die Blogosphre ruhig an die eigene Nase fassen, wir quasseln noch viel mehr Unsinn als Monsieur von Matt.
Interessant aber fand ich obiges Zitat: er neidet uns die Freiheit, die wir genießen, die er nicht genießen kann.
Jean-Remy, einen Blog zu schreiben ist kinderleicht. Das kannst auch Du. Denn: Du bist Blog!
Architektur
Die bisherige Version des DSA4 Werkzeugs ist in C++ programmiert. Für die Daten entschied ich mich damals für ein XML-Datenformat, was zu der Anbindung von Xerces führte. Die GUI wurde mit wxWindows gemacht (die ersten Versionen, falls sich noch jemand erinnert, beruhten auf MSXML und native Windows GUI Elementen). Der Wechsel auf Xerces und wxWindows wurde durchgeführt, um Plattformunabhängig zu sein. Und tatsächlich: der Code compilierte auch unter Linux (dank hier an die Portierer). Aber richtig laufen tat er nie, es waren immer irgendwelche Bugs in der Linuxversion, die ich nicht in der Windowsversion nachvollziehen konnte.
Außerdem war das verwendete C++ viel zu kompliziert. Ich benutzte massig Templates (vor allem für die Rassen, Kulturen und Professionen), was den Code sehr schwer lesbar und bearbeitbar machte. Auch ein schlichtes compilen war eine recht anspruchsvolle Prozedur. Ich gehe davon aus, dass deswegen nie im größeren Maße Entwicklungsarbeit von anderen als von mir geleistet wurde: mein Code war schlicht zu kompliziert. Aus de selben Grund habe ich selber ja in den letzten Monaten den Code nicht angefasst.
Dies ist die wichtigste Lektion für die neue Version: deutlich einfacherer Code. Änderungen müssen auch ohne sich extrem reinzuarbeiten möglich sein. Idealerweise sollte das ganze Werkzeug interpretiert sein. Kein compilen mehr. Ändern. Neustart. Fertig.
Wie ich das erreichen will verrate ich in den nächsten Blogeinträgen genauer (deswegen habe ich auch nicht so viel geschrieben die letzten Tage -- und weil ich auf Dienstreisen in Kaiserslautern und Düsseldorf war -- ich wollte zunächst ein halbwegs tragbares Konzept haben. Das kommt jetzt die nächsten paar Tage. Hier schonmal eine grobe Übersicht -- ich werde im Folgenden genauer auf die Begriffe und den Aufbau eingehen.
Mozilla, die Open Source Gruppe die uns nicht nur Firefox und Thunderbird beschert hat, hat, was die Basis ihrer Tools ist, ein umfangreiches, sogenanntes Mozilla Application Framework erstellt. Im Großen und Ganzen ist es ein supermächtiges Biest -- ich will es soweit zähmen, damit das DSA4 Werkzeug darauf läuft. Hierbei gibt es eine Hauptengine, die XULRunner heißt. XUL ist so etwas wie HTML, bloß für GUIs von Anwendungen (und man kann tatsächlich auch HTML und JavaScript in XUL mit benutzen). Das bedeutet, das User Interface des neuen DSA4 Werkzeugs zu ändern wird so leicht sein wie HTML-Seiten schreiben, ja, sogar mit CSS arbeitet das ganze zusammen. Interessant ist hierbei vor allem das Verwenden von JavaScript, das eine dynamische GUI erlaubt. Die Applikationslogik hingegen kann entweder in JavaScript implementiert werden, oder auch in C++ oder Java (oder Python), um dann über XPCOM (oder PyXPCOM) darauf zuzugreifen. Potenziell also kann man auch Teile des bisherigen Codes wiederverwenden! Schließlich, die Daten werden in RDF gespeichert, einer XML-basierten Sprache, die aber deutlich Vorteile zu XML (und ein paar Nachteile) aufweist.
All dies unterstützt das Mozilla Application Framework von Haus aus. Anhand von Thunderbird und Firefox sieht man ja, dass das durchaus zu brauchbaren Applikationen führen kann. Ich hoffe, dass es auch hier aufgeht.
WLAN im Zug
Heute fuhr ich nach Düsseldorf, um bei der Britischen Botschaft mein Visum für Großbritannien zu beantragen und, so es klappt, auch gleich zu holen. Ich hatte schon einiges erwartet -- manche Horrorgeschichte wurde erzählt über Beamtentum, Formaliakrieg, Großkotzigkeit und Willkürherrschaft. Doch nichts dergleichen trat ein (zumindest nicht beim Beantragen heute morgen). Äußerst höflich, zuvorkommend und hilfsbereit.
Allerdings muss ich jetzt einige Zeit totschlagen (um am Nachmittag das fertige Visum abzuholen). Da ich die Zeit zum Arbeiten nutzen wollte, und zudem in der Gegend war, dachte ich mir, probiere ich mal das neue Pilotprojekt der Bahn aus, WLAN im ICE. Also fuhr ich nach Dortmund um von dort Richtung München nach Köln im ICE zu fahren. Dummerweise habe ich doch den falschen Zug erwischt, keinen ICE3 scheinbar, und ich kann einfach nicht herausfinden, welche Züge jetzt tatsächlich WLAN haben.
Schade. Na gut, habe ich mich doch in Düsseldorf hingesetzt und hier ein wenig gearbeitet. Und dann geht es zurück zum Konsulat. Ich war ganz frech und habe gleich ein Visum für fünf Jahre beantragt (statt des üblichen halben Jahrs). Mal sehen, was rauskommt... ein unbekannter (Fast)Landsmann, den ich zufällig am Konsulat traf, erklärte mir, dass das nie klappen würde, und dass das ganze immer Willkür sei, er hätte schließlich Erfahrung damit, schließlich muss er schon zum wiederholten Mal verlängern. Na ja, mit der Einstellung, kein Wunder dass es dann Probleme gibt. Ich vermied es, ihn darauf hinzuweisen, dass seine beiden Aussagen ("Willkür" und "das wird nie klappen") sich gegenseitig widersprechen.
Na, schauen wir mal, was rauskommt. Bloß blöd, dass das mit dem WLAN nicht geklappt hat.
Ein neuer Anfang
Alles, was aufwändiger ist als ein Blog scheint zur Zeit nicht zu funktionieren.
Wie viele von Euch wissen, verfolge ich seit langem das Ziel, ein Programm zu erstellen, welches beim Spielen von DSA in der vierten Edition Spielern und Spielleitern zur Hand geht. Wie ebenfalls die meisten wissen, war das Projekt leider die letzten Monate tot. Dies hatte mehrere Gründe: einerseits habe ich schlichtweg viel weniger Zeit als früher, und schließlich habe ich mich mit den Aufgaben beim DSA4 Werkzeug übernommen. Ich wollte sowohl das Programm erstellen - in allen Aspekten, Datenhaltung, User Interface, Logos, als auch die dazugehörige Website betreuen, als auch die Dokumentation schreiben, als auch eine Softwarebibliothek in C++ erstellen, die für DSA4-Tools gedacht ist, als auch die Druckausgabe verfeinern, als auch das XML-Format definieren, als auch die entstehende Community verwalten. Das mag eine ganz kurze Zeit funktioniert haben -- aber es musste, als ich meinen Beruf angetreten habe, schief gehen. Dummerweise liebe ich auch noch meinen Beruf, was mich zwar persönlich erfreut, aber der Entwicklung des DSA4 Werkzeugs nicht gut tut.
Ich werde in diesem Blog anfangen, die weitere Entwicklung des DSA4 Werkzeugs nach außen zu präsentieren. Dies ist ein vorläufiger Ersatz für eine echte Website, die einen Community-Prozess erlaubt. Aber diese Website werde ich nicht aufstellen. Ebenso werde ich tatsächlich nur wenige Emails im Zusammenhang mit dem DSA4 Werkzeug ausführlich beantworten. Ich brauche jemanden, der sich bereit erklärt, eine dazugehörige Website zu pflegen, und jemanden, der mir bei der Community helfen will. Ich erinnere mich, dass ich früher teilweise mehr Zeit in die Website und die Beantwortung von Emails investiert habe, als in die eigentliche Entwicklung. Dies muss ich diesmal vermeiden. Die Community war großartig! Ich brauche bloß an Leute wie Twel oder Wolfgang denken, die unglaubliches geleistet haben. Wer sich berufen fühlt, zu helfen, melde sich bitte bei mir.
Damit klar ist: ich werde auch in Zukunft nicht auf magische Weise mehr Zeit haben. Aber meine Erfahrungen in Industrie und Forschung, sowie das Wissen und die Erfahrung, die ich inzwischen über Open Source Community Prozesse und Software Engineering angesammelt habe, erlauben mir -- so die Hoffnung -- einige Fehler der ersten zwei Versionen des DSA4 Werkzeugs zu vermeiden. Die Architektur des alten DSA4 Werkzeugs war sehr durchdacht, und extrem flexibel. Leider war sie auch sehr kompliziert: metatemplate-Programmierung in C++ ist megacool, aber es macht den Einstieg für andere nicht gerade einfach. Einer der Gründe, warum es in den Monaten der aktiven Entwicklung keine 100 Zeilen von anderen Entwicklern in den Quelltext geschafft haben, oder warum niemand das Projekt aufgegriffen hat, nachdem ich offensichtlich nicht mehr weiterarbeitete. Dies wird der Hauptpunkt, den ich angreifen werde.
In den nächsten Tagen - ja, wirklich, Tagen - werde ich hier anfangen, in Blogeinträgen die neue Architektur zu skizzieren, sowie diverse Punkte auflisten. Zu einem Zeitplan möchte ich mich nicht durchringen, wann das Programm fertig wird. Aber ich kann versprechen, dass ein neuer Anfang gemacht ist. Warum? Weil das nicht Absicht ist, sondern auf erstem Code beruht. Zugegeben, bisher nur auf meiner Platte. Aber sobald es vorzeigbar ist, auch wieder auf SourceForge im CVS.
Ein halbes Jahrzehnt Nodix
Vor genau fünf Jahren habe ich Nodix begründet. Wie jedes Jahr (2002, 2003, 2004, 2005) heißt das Rückblick und Ausblick und ein wenig Zahlenspielchen, sowie Versprechen, die ich nicht einlösen werde.
Laut dem Zähler auf dieser Website hatten die Nodix-Seiten im ersten Jahr 2.000, im zeiten 20.000, dann 44.000, und dann 115.000 Besuche. Und letztes Jahr? Laut dem Zähler ging die Zahl auf 92.000 neue Besuche zurück. Was bedeutet das? Sind es tatsächlich weniger Besucher als früher? Nun ja, überraschend wäre es nicht -- einen Großteil des Jahres waren die Seiten eher ruhig, manche einfach tot, und vor fast zwei Monaten gab es einen fiesen Angriff auf Nodix, der alle Daten löschte, und die Daten immer noch nicht wieder zurück sind.
Genauer in die Zugriffsstatistiken geschaut, können wir aber sehen, dass Nodix nicht unbedingt weniger Besucher anlockt: laut der 1&1-Statistik hatten wir schon 2004 nicht 115.000 Besucher sondern 198.000 -- und letztes Jahr nicht etwa 92.000, sondern sage und schreibe 416.454 Besucher! Nicht Seitenaufrufe.
Woher die Diskrepanz? Ich tippe auf die Feeds. Seit Ende 2004 setzen die Nodix-Seiten vermehrt auf Feeds, und ihr, werte Leser, nutzt diese Gelegenheit natürlich auch, und das ist auch gut so. Der Abruf eines Feeds jedoch erhöht nicht den Zählerstand auf der Seite. Auch weiß ich nicht, ob die Statistik von 1und1 Abrufe des Feeds, der sich nicht verändert hat, auch mitzählt -- sprich, wird jedesmal, wenn jemand, der einen RSS-Feed der Nodix-Seiten abonniert hat, online geht und Feeds checkt, der Zähler erhöht? Dann wäre die Zahl von 416.454 natürlich deutlich überhöht! Aber dann wiederum biete ich auf semantic.nodix.net auch einen Feed im RSS-Format, den Feedburner aus dem Atom-Feed erstellt, den ich nicht mitzählen kann. Und PlanetRDF smusht semantic.nodix-Einträge auch noch mit. Was cool ist. Aber über Reichweite kann man dann letztlich nur noch die Kristallkugel befragen. Sie ist genauso glaubwürdig wie der Zähler von 1und1 oder der auf dieser Seite und jetzt etwa 273.000 anzeigt.
Oder kurz: ich habe eigentlich keine Ahnung, wieviele Leser Nodix eigentlich hat. Nada.
Also kommen wir zu den Rück- und Ausblicken: nutkidz sind wieder da, bisher regelmäßig, und das soll auch so bleiben. Auch die englische Übersetzung läuft prima. Apropos Übersetzungen: nach einer langen Pause ist auch die deutsche Übersetzung von something*positive wieder angelaufen. Ihr kennt das nicht? Ist auch ein Webcomic - und ein sehr fieser dazu! Ich würde sagen, ab 16 und nichts für schwache Gemüter. nakit-arts läuft prima -- Schwesterchen, gratuliere! Dies ist bei weitem der erfolgreichste Blog auf den Nodix-Seiten und auch um längen die schönste Seite von Nodix. Nur weiter so! semantic.nodix läuft und läuft gut. Wer sich für meine Arbeit interessiert, sollte da mit-lesen. Das DSA4 Werkzeug - nun, die Seite ist tot, ich denke noch darüber nach, und wenn alles nach Plan läuft, wird es dieses Jahr einen neuen Start geben. Dazu mehr zu gegebenem Zeitpunkt. XML4Ada95 hat ein Interesse geweckt ähnlich wie die Sprache selbst ;) -- ich will die Seite bald noch ein letztes Mal ändern, und dann ist das Projekt beendet. Nodix ist groß, wie ihr seht. Und es wird dieses Jahr noch weiter wachsen.
Also, auf in die zweite Hälfte des Jahrzehnts! Eine drittelmillion soll der Zähler am Jahresende anzeigen!
GESTS journal invitation! - ideas for better spam
Yeah, isn't that great! Got an invitation to submit my paper to the GESTS Journal "Transactions on Communications and Signal Processing" (won't link to it). Well, not directly my field, and I never heard of the Journal, but hey, a journal paper, isn't that great...
Ehhm, not exactly. Actually it seems to be spam. Another collegue got the same invitation last week. And no one heard about the journal. And it really isn't my field. I don't have to do anything with Signal Processing. And why do they want money for printing my article?
What I was wondering: why didn't they do it some better? With the AIFB OWL Export they could have got the machine processable information about the interests of each person at the AIFB. With a bit of SPARQLing they could have gotten tons of information -- fully machine processable! They could have found out that I am not into Signal Processing, but into Semantic Web. Personalizing Spam would be sooo easy. Spam could become so much more time-consuming to filter out, and much more attractive, if those spammers would just harvest FOAF-data and semantic exports. I really am surprised they didn't do that yet.
Comments are still missing on this post.