Semantic search
My Erdös Number
After reading a post by Ora and one by Tim Finin, I tried to figure my own Erdös Number out. First, taking Ora's path, I came up with an Erdös of 7:
Paul Erdös - Stephan Hedeniemi - Robert Tarjan - David Karger - Lynn Stein - Jim Hendler - Steffen Staab - Denny Vrandečić
But then I looked more, and with Tim's path I could cut it down to 6:
Paul Erdös - Aviczir Fraenkl - Yaacov Yesha - Yelena Yesha - Tim Finin - Steffen Staab - Denny Vrandečić
The point that unnerved me most was that the data was actually there. Not only a subscription-only database for mathematical papers (why the heck is the metadata subscription only?), but there's DBLP, there's the list of Erdös 1 and 2 people on the Erdös Number project, there's Flink, and still, I couldn't mash up the data. This syntactic web sucks.
The only idea that brought me further - without spending even more time with that - was a Google search for "my erdös number" "semantic web", in the hope to find some collegues in my field that already have found and published their own Erdös number. And yep, this worked quite fine, and showed me two further, totally disjunctive paths to the one above:
Paul Erdös - Charles J. Coulborn - A. E. Brouwer - Peter van Emde Boas - Zhsisheng Huang - Peter Haase - Denny Vrandečić
and
Paul Erdös - Menachem Magidor - Karl Schlechta - Franz Baader - Ian Horrocks - Sean Bechhofer - Denny Vrandečić
So that's and Erdös of 6 on at least 3 totally different paths. Nice.
What surprises me - isn't this scenario obviously a great training project for the Semantic Web? Far easier than Flink, I suppose, and still interesting for a wider audience as well, like Mathematicians and Noble Laureates? (Oh, OK, not them, they get covered manually here).
Update
I wrote the post quite a time ago. A colleague of mine notified me in the meantime that I have a Erdös of only 4 by the following path:
Paul Erdös - E. Rodney Canfield - Guo-Quiang Zhang - Markus Krötzsch - Denny Vrandečić
Wow. It's the social web that gave the best answer.
2019 Update
Another update, after more than a dozen years: I was informed that I have now an Erdös number of 3 by the following path:
Paul Erdös - Anthony B. Evans - Pascal Hitzler - Denny Vrandečić
I would be very surprised if this post requires any further updates.
My horoscope for today
Here's my horoscope for today:
You may be overly concerned with how your current job prevents you from reaching your long-term goals. The Sun's entry into your 9th House of Big Ideas can work against your efficiency by distracting you with philosophical discussions about the purpose of life. These conversations may be fun, but they should be kept to a minimum until you finish your work.
How the heck did they know??
Need help with SQL
But I have no time to write it down... I will sketch my problem, and hopefully get an answer (I've started this blog in the morning, and now I need to close it, cause I have to leave).
Imagine I have following table (a triple store):
| Subject | Predicate | Object |
|---|---|---|
| Adam | yahoo im | adam@net |
| Adam | skye | adam |
| Berta | skype | berta |
How do I make a query that returns me the following table:
| Subject | o1 | o2 |
|---|---|---|
| Adam | adam@net | adam |
| Berta | - | berta |
The problems are the default value in the middle lower cell. The rest works (as maybe seen in the Semantic Mediawiki code, file includes/SMW_InlineQueries.php -- note that the CVS is not up to date for now, because SourceForge's CVS is down for days!)
It should work in general, with as many columns as I like on the answer table (based on the predicates in the first one).
Oh, and if you solved this -- or have an idea -- it would be nice if it worked with MySQL 4.0, i.e. without Subqueries.
Any ideas?
New OWL tools
The KAON2 OWL Tools get more diverse and interesting. Besides the simple axiom and entity counter and dumper, the not so simple dlpconverter, and the syntactic transformer from XML/RDF to OWL/XML and back, you now also have a filter (want to extract only the subClassOf-Relations out of your ontology? Take filter), diff and merge (for some basic syntactic work with ontologies), satisfiable (which checks if the ontology can have a satisfying model), deo (turning SHOIN-ontologies in SHIN-ontologies by weakening, should be sound, but naturally not complete) and ded (removes some domain-related axioms, but it seems this one is still buggy).
I certainly hope this toolbox will still grow a bit. If you have any suggestions or ideas, feel free to mail me or comment here.
New home in Emeryville
Our new (temporary home) is the City of Emeryville. Emeryville has a population of almost 13,000 people. The apartment complex we live in has about 400 units, and I estimate that they have about 2 people on average in each. Assuming that about 90% of the apartments are occupied, this single apartment complex would constitute between 5 and 10% of the population of the whole city.
New people at Yahoo and Google
Vint Cerf starts working at Google, Dave Becket moves to Yahoo. Both like the Semantic Web (Vint said so in a German interview with c't, and I probably don't have to remind you about Daves accomplishments).
I'm sure, Yahoo got Dave because of his knowledge about the Semantic Web. And I wonder if Google got Vint out of the same reason? Somehow, I doubt it.
New tagline is my New Year's resolution
I just changed the tagline of this blog. The old one was rather, hmm, boring:
"Discovering the Semantic Web, Ontology Engineering and related technologies, and trying to understand these amazing ideas - and maybe sharing an idea or two... "
The new one is at the same time my new year's resolution for 2006.
"Kicking the Semantic Web's butt to reality"
'nuff said, got work to do.
New versions: owlrdf2owlxml, dlpconvert
New versions of owlrdf2owlxml and dlpconvert are out.
owlrdf2owlxml got renamed, as it was formerly known as rdf2owlxml. But as a colleague pointed out, this name can easily be misunderstood, meaning to transform arbitrarily RDF to OWL. It doesn't do that, it only transforms OWL to OWL, from RDF/XML-serialisation to XML Presentation Syntax. And it seems to work quite stable, it can even transform the famous wine ontology. Version 0.4 out now.
dlpconvert lost a lot of its bugs. And as most of you were feeding RDF/XML to it, well, now you can do it officially (listen to the users), too. It reads both syntaxes, and creates a Prolog program out of your ontology. Version 0.7 is out.
They are both based on KAON2, the Karlsruhe Ontology Infrastructure module, written by Boris Motik. My little tools are just wrapped around KAON2 and using its functionality. To be honest, I'm thinking of writing quite a number of little tools like this, who offer different functionality, thus providing you with a nice toolkit to handle ontologies efficiently. I don't lack ideas right now, it's just I' m not sure that there's interest in this.
Well, maybe I should just start and we'll see...
By the way, both tools are not only available as web services, but you may also download them as command line tools from their respective websites and play around it on your PC. That's a bit more comfortable than using a browser as your operating system.
No April Fool's day
This year, I am going to skip April Fool's day.
I am not being glib, but quite literal.
We are taking flight NZ7 starting on the evening of March 31 in San Francisco, flying over the Pacific Ocean, and will arrive on April 2 in the early morning in Auckland, New Zealand.
Even if one actually follows the flight route and overlays it over the timezone map, it looks very much like we are not going to spend more than a few dozen minutes, or at most a few hours, in April 1, if all goes according to plan.
Looking forward to it!
Here's the flight data of a previous NZ7 flight, from Sunday: https://flightaware.com/live/flight/ANZ7/history/20230327/0410Z/KSFO/NZAA/tracklog
Here are the timezones (but it's Northern winter time). Would be nice to overlay the two maps: 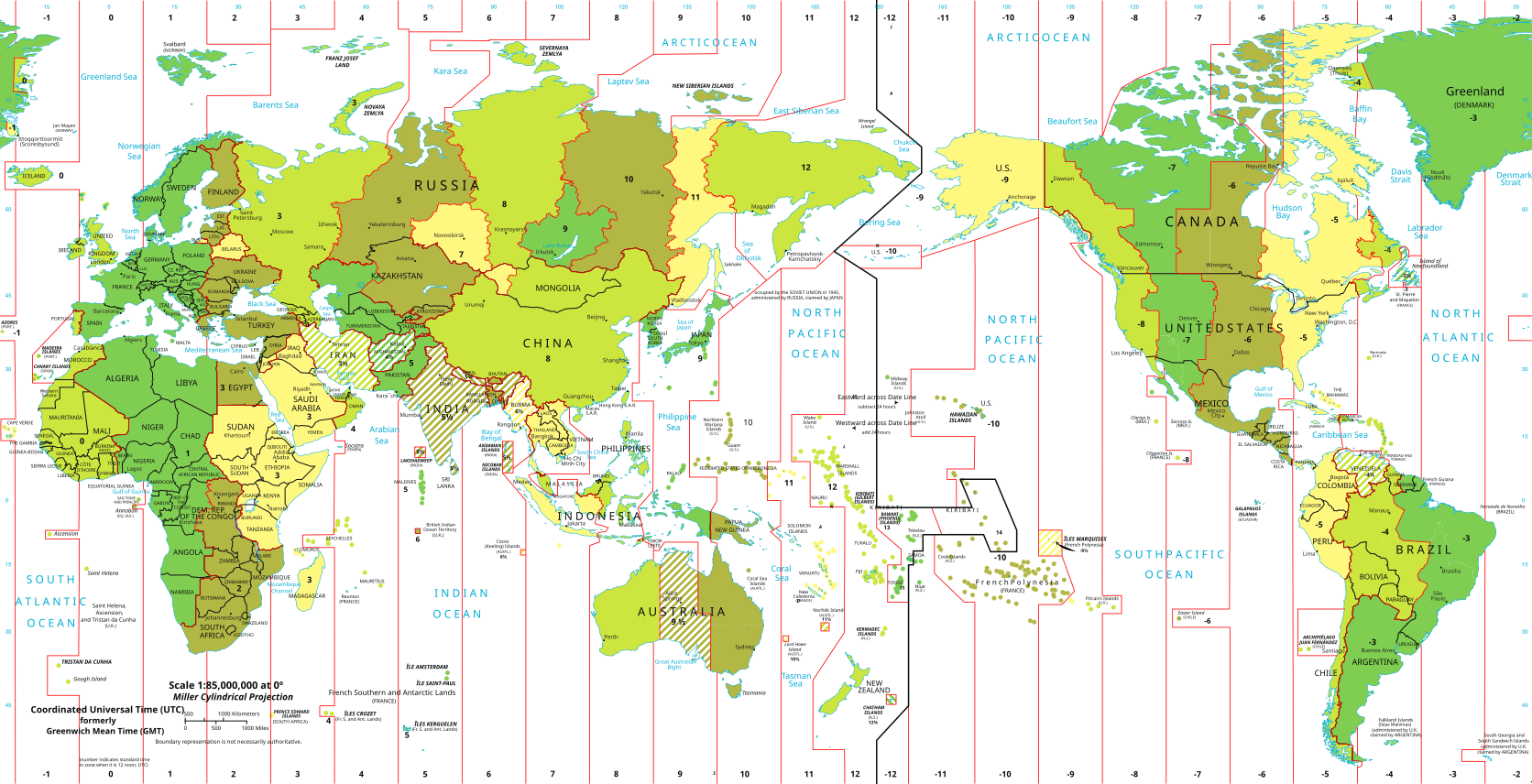
Where's Wikifunctions when it's needed?
The question seems to be twofold: how often do we cross the dateline, and how close are we to local time midnight while crossing the dateline. For a perfect date miss one would need to cross the dateline exactly once, at a 24 hour difference, as close as possible to local midnight.
Normbrunnenflasche
It's a pity there's no English Wikipedia article about this marvellous thing that exemplifies Germany so beautifully and quintessentially: the Normbrunnenflasche.
I was wondering the other day why in Germany sparkling water is being sold in 0.7l bottles and not in 1l or 2l or whatever, like in the US (when it's sold here at all, but that's another story).
Germany had a lot of small local producers and companies. To counter the advantages of the Coca Cola Company pressing in the German market, in 1969 a conference of representatives of the local companies decided to introduce a bottle design they all would use. This decision followed a half year competition and discussion on what this bottle should look like.
Every company would use the same bottle for sparkling water and other carbonated drinks, and so no matter which one you bought, the empty bottle would afterwards be routed to the closest participating company, not back home, therefore reducing transport costs and increasing competitiveness against Coca Cola.
The bottle is full of smart features. The 0.7l were chosen to ensure that the drink remained carbonated until the last sip, because larger bottles would last longer and thus gradually loose carbonization.
The form and the little pearls outside were chosen for improved grip, but also to symbolize the sparkles of the carbonization.
The metal screw cap was the real innovation there, useful for drinks that could increase pressure due to the carbonization.
And finally two slightly thicker bands along the lower half of the bottle that would, while being rerouted for another usage, slowly get more opaque due to mechanical pressure, thus indicating how well used the individual bottle was, so they could be taken out of service in time before breaking at the customer.
The bottles were reused an average of fifty times, their boxes an average of hundred times. More than five billion of them have been brought into circulation in the fifty years since their adoption, for an estimated quarter of a trillion fillings.
Northern Arizona
Last week we had a wonderful trip through Northern Arizona.
Itinerary: starting in Phoenix going Northeast through Tonto National Forest towards Winslow. In Tonto, we met our first surprise, which would become a recurring pattern: whereas we expected Arizona in April to be hot, and we were prepared for hot, it had some really cold spells, and we were not prepared for cold. We started in the Sonoran Desert, surrounded by cacti and sun, but one and a half hours later in Tonto, we were driving through a veritable snow storm, but fortunately, just as it was getting worrisome, we crossed the ridge and started descending towards Winslow to the North.
The Colorado Plateau on the other side of the ridge was then pleasant and warm, and the next days we traveled through and visited the Petrified Forest, Monument Valley, Horseshoe Bend, Antelope Canyon, and more.
After that we headed for the Grand Canyon, but temperatures dropped so low, and we didn't have the right outfit for that, we stayed less than a day there, most of it huddled in the hotel room. Still, the views we got were just amazing, and throwing snowballs was an unexpected fun exercise.
Our last stop took us to Sedona, where we were again welcomed with amazing views. The rocks and formations all had in common that they dramatically changed with the movement of the sun, or with us moving around, and the views were always fresh.
Numbers: Our trip took us about 950 miles / 1500 kilometeres of driving, and I was happy that it was a good Jeep for this trip. The difference in altitude went from 1000 feet / 330 meters in Phoenix up to 8000 feet / 2400 meters driving through Coconino. Temperatures ranged from 86° F / 30° C to 20° F / -7° C.
What I learned again is how big this country is. And how beautiful.
Surprises: One thing that surprised me was how hidden the Canyons can be. Well, you can't hide Grand Canyon, but it is easy to pass by Antelope Canyon and not realizing it is there. Because it is just a cut in the plateau.
I also was surprised about how flat and wide the land is. I have mostly lived in areas where you had mountains or at least hills nearby, but the Colorado Plateau has large wide swaths of flat land. "Once the land was as plane as a pancake".
I mentioned the biggest surprise already, which was how cold it got.
Towns: it was astonishing to see the difference between, on the one side, a town such as Page or Sedona and on the other side Winslow. All three have a similar population, but Page and Sedona felt vigorous, lively, clean, whereas Winslow felt as if it was on the decline, deserted, struggling.
The hotel we stayed in in Winslow, La Posada, was a beautiful, weird, unique jewel that I hesitate to flat-out recommend, it is too unusual for that, but that I still enjoyed experiencing. It is clearly very different from any other hotel I ever stayed in, full of history, and embracing themes of both suicide and hope, respectfully trying to grow with the native population, and aiming to revive the city's old town, and it is difficult to really capture the vibe it was sending out.
For pictures, I am afraid I am pointing to my Facebook posts, which should be visible without login:
- Scottsdale
- Palo Verde tree
- Desert Botanical Garden, Phoenix
- Desert to snowstorm
- Winslow
- La Posada hotel
- Petrified forest
- Monument valley
- Horseshoe bend
- Antelope canyon
- Grand canyon
- Sedona
OK
I often hear "don't go for the mediocre, go for the best!", or "I am the best, * the rest" and similar slogans. But striving for the best, for perfection, for excellence, is tiring in the best of times, never mind, forgive the cliché, in these unprecedented times.
Our brains are not wired for the best, we are not optimisers. We are naturally 'satisficers', we have evolved for the good-enough. For this insight, Herbert Simon received a Nobel prize, the only Turing Award winner to ever get one.
And yes, there are exceptional situations where only the best is good enough. But if good enough was good enough for a Turing-Award winning Nobel laureate, it is probably for most of us too.
It is OK to strive for OK. OK can sometimes be hard enough, to be honest.
May is mental health awareness month. Be kind to each other. And, I know it is even harder, be kind to yourself.
Here is OK in different ways. I hope it is OK.
Oké ఓకే ਓਕੇ オーケー ओके 👌 ওকে או. קיי. Окей أوكي Օքեյ O.K.
OWL 2.0
I posted this to the public OWL dev mailing list as a response to a question posed by Jim Hendler quite some while ago. I publish it here for easier reference.
Quite some while ago the question of OWL 2.0 was rised here, and I wrote already two long replies with a wishlist - but both were never sent and got lost in digital nirvana, one due to a hardware, the second due to a software failure. Well, let's hope this one passes finally through. That's why this answer is so late.
Sorry for the lengthy post. But I tried to structure it a bit and make it readable, so I hope you find some interesting stuff here. So, here is my wishlist.
- I would like yet another OWL language, call it OWL RDF or OWL Superlite, or whatever. This is like the subset of OWL Lite and RDFS. For this the difference between of owl:Class and rdf:Class needs to be somehow standardly solved. Why is this good? It makes moving from RDF to OWL easier, as it forces you to keep Individuals, Classes and Relations in different worlds, and forgets about some of the more sophisticated constructs of RDF(S) like lists, bags and such. This is a real beginners language, really easy to learn and implement.
- Defined Semantics for OWL FUll. It is unclear -- at least to me -- what some combinations of RDF(S)-Constructs and OWL DL-constructs are meant to mean.
- Add easy reification to OWL. I know, I know, making statements about statements is meant to be the root of all evil, but I find it pretty useful. If you like, just add another group of elements to OWL, statements, that are mutually disjoint from classes, instances and relations in OWL DL, but there's a sublanguage that enables us to speak about statements. Or else OWL will suck a lot in comparison to RDF(S) and RDF(S) + Rules will win, because you can't do a lot of the stuff you need to do, like saying what the source of a certain statement is, how reliable this source is, etc. Trust anyone? This is also needed to extend ontologies toward probabilistic, fuzzy or confidence-carrying models.
- I would love to be able to define syntactic sugar, like partitionOf (I think, this is from Asun's Book on Ontology Engineering). ((A, B, C) partitionOf D) means that every D is either an A or a B or a C, that every A, B or C is a D, and that A, B and C are mutually disjunct. So you can say this already, but it needs a lot of footwork. It would be nice to be able to define such shotcuts that lever upon the semantics of existing constructors.
- That said, another form of syntactic sugar - because again you can use existing OWL constructs to reach the same goal, but it is very strenuous to do so - would be to define UNA locally. Like either to say "all individuals in this ontology are mutually different" or "all individuals with this namespace are mutually different". I think, due to XML constraints the first one would be the weapon of choice.
- I would like to be able to have more ontologies in the same file. So you can use ontologies to group a number of axioms, and you also could use the name of this group to refer to it. Oh well, using the name of an ontology as an individual, what does this mean? Does it imply any further semantics? I would like to see this clarified. Is this like named graphs?
- The DOM has quite nicely partitioned itself in levels and modules. Why not OWL itself? So you could have like a level 2 ontology of mereological questions, and such stuff, all with well defined semantics, for the generic questions. I am not sure there are too many generic questions, but taxonomy is (already covered), mereology would be, and spatiotemporal and dynamic issues would be as well. Mind you, not everyone must use them, but many will need them. It would be fine to find stan dard answers to such generic questions.
- Procedural attachments would be a nice thing. Like have a a standardized possibilities to add pieces of code and have them executed by an appropriate execution environment on certain events or requests by the reasoner. Yes, I am totally aware of the implications on reasoning and decidability, but hey, you asked what people need, and did not ask for theoretical issues. Those you understand better.
- There are some ideas of others (which doesn't mean that the rest is necessarily original mine) I would like to see integrated, like a well-defined epistemic operator or streamlining the concrete domains to be more consistent with abstract domains, or to define domain and range _constraints_ on relations, and much more. Much of this stuff could be added optional in the sense of point 7.
- And not to forget that we have to integrate with rules later, and to finally have an OWL DL query language. One goal is to make it clear what OWL offers over simply adding rules atop of RDF and ignoring the ontology layer completely.
So, you see, this is quite a list, and it sure is not complete. Even if only two or three points were finally picked up I would be very happy :)
OWL luna, nicer latex, OWL/XML to Abstract Syntax, and more
After a long hiatus, due to some technical problems, finally I could create a new version of the owl tools. So, version 0.27 of the owl tools is now released. It works with the new version of KAON2, and includes six months of bug fixing, but also a number of new features that have introduced a whole new world of new, exciting bugs as well.
The owl latex support was improved greatly. Translation of an owl ontology is done now more careful, and the user can specify much more of the result than before.
A new tool is owl luna - luna like local unique name assumption. It adds an axiom to your ontology that states that all individuals are different from each other. Due to most ontology editors not allowing to do this automatically, here you find a nice maintenance tool to make your ontology much less ambiguous.
The translations of OWL/RDF to OWL/XML and back have been joined in one new tool, called owl syntax, that allows you to translate owl ontologies also to OWL Abstract Syntax, a much nicer syntax for owl ontologies.
owl dlpconvert has been extended as it now also serialzes it results as RuleML if you like. So you can just pipe your ontologies to RuleML.
So, the tools have both become sharper and more numerous, making your toolbelt to work with owl in daily life more usable. Get the new owl tools now. And if you peek into the source code, the code has underwent a major clean up, and you will also see the new features I am working on, that have to do with ontology evaluation and more.
Have fun with the tools! And send me your comments, wishes, critiques!
On the competence of conspiracists
“Look, I’ll be honest, if living in the US for the last five years has taught me anything is that any government assemblage large enough to try to control a big chunk of the human population would in no way be consistently competent enough to actually cover it up. Like, we would have found out in three months and it wouldn’t even have been because of some investigative reporter, it would have been because one of the lizards forgot to put on their human suit on day and accidentally went out to shop for a pint of milk and like, got caught in a tik-tok video.” -- Os Keyes, WikidataCon, Keynote "Questioning Wikidata"
One world. One web.
I am in Beijing at the opening of the WWW2008 conference. Like all WWWs I was before, it is amazing. The opening ceremony was preceded by a beautiful dance, combining tons of symbols. First a woman in a traditional Chinese dress, then eight dancers in astronaut uniforms, a big red flag with "Welcome to Beijing" on it (but not on the other side, when he came back), and then all of them together... beautiful.
Boris Motik's paper is a best paper candidate! Yay! Congratulations.
I rather listen to the keynote now :)
Blogging from my XO One.
Oscar winning families
Yesterday, when Jamie Lee Curtis won her Academy Award, I learned that both her parents were also nominated for Academy Awards. Which lead to the question: who else?
I asked Wikidata, which lists four others:
- Laura Dern
- Liza Minnelli
- Nora Ephron
- Sean Astin
Only one of them belongs to the even more exclusive club of people who won an Academy Award, and where both parents also did: Liza Minnelli, daughter of Vincente Minelli and Judy Garland.
Also interesting: List of Academy Award-winning families
Our four freedoms for our technology
(This is a draft. Comments are welcome. This is not meant as an attack on any person or company individually, but at certain practises that are becoming increasingly prevalent)
We are not allowed to use the devices we paid for in the ways we want. We are not allowed to use our own data in the way we want. We are only allowed to use them in the way the companies who created the devices and services allow us.
Sometimes these companies are nice and give us a lot of freedom in how to use the devices and data. But often they don’t. They close them down for all kinds of reasons. They may say it is for your protection and safety. They might admit it is for profit. They may say it is for legal reasons. But in the end, you are buying a device, or you are creating some data, and you are not allowed to use that device and that data in the way you want to, you are not allowed to be creative.
The companies don’t want you to think of the devices that you bought and the data that you created as your devices and your data. They want you to think of them as black boxes that offer you services they create for you. They don’t want you to think of a Ring doorbell as a camera, a microphone, a speaker, and a button, but they want you to think of it as providing safety. They don’t want you to think of the garage door opener as a motor and a bluetooth module and a wifi module, but as a garage door opening service, and the company wants to control how you are allowed to use that service. Companies like Chamberlain and SkyLink and Genie don’t allow you to write a tool to check on your garage door, and to close or open it, but they make deals with Google and Amazon and Apple in order to integrate these services into their digital assistants, so that you can use it in the way these companies have agreed on together, through the few paths these digital assistants are available. The digital assistant that you buy is not a microphone and a speaker and maybe a camera and maybe a screen that you buy and use as you want, but you buy a service that happens to have some technical ingredients. But you cannot use that screen to display what you want. Whether you can watch your Amazon Prime show on the screen of a Google Nest Hub depends on whether Amazon and Google have an agreement with each other, not on whether you have paid for access to Amazon Prime and you have paid for a Google Nest Hub. You cannot use that camera to take a picture. You cannot use that speaker to make it say something you want it to say. You cannot use the rich plethora of services on the Web, and you cannot use the many interesting services these digital assistants rely on, in novel and creative combinations.
These companies don’t want you to think of the data that you have created and that they have about you as your data. They don’t want you to think about this data at all. They just want you to use their services in the way they want you to use their services. On the devices they approve. They don’t want you to create other surfaces that are suited to the way you use your data. They don’t want you to decide on what you want to see in your feed. They don’t want you to be able to take a list of your friends and do something with it. They will say it is to protect privacy. They will say that it is for safety. That is why you cannot use the data you and your friends have created. They want to exactly control what you can and cannot do with the data you and your friends have created. They want to control how many ads you must see in order to be allowed to see your friends’ posts. They don't want anyone else to have the ability to provide you creative new interfaces to your feed. They don’t want you yourself the ability to look at your feed and do whatever you want with it.
Those are devices you paid for.
These are data you and your friends have created.
And more and more we are losing our freedom of using our devices and our data as we like.
It would be impossible to invent email today. It would be impossible to invent the telephone today. Both are protocols that allow everyone to communicate with anyone no matter what their email provider or their phone is. Try reading your friend’s Facebook feed on Instagram, or send a direct message from your Twitter account to someone on WhatsApp, or call your Skype contact on Facetime.
It would be impossible to launch the Web today - many companies don’t want you browsing the Web. They want you to be inside of your Facebook feed and consume your content there. They want you to be on your Twitter feed. They don’t want you to go to the Website of the New York Times and read an article there, they don’t want you to visit the Website of your friend and read their blog there. They want you to stay on their apps. Per default, they open Websites inside their app, and not in your browser, so you are always within their app. They don’t want you to experience the Web. The Web is dwindling and all the good things on it are being recut and rebundled within the apps and services of tech companies.
Increasingly, we are seeing more and more walls in the world. Already, it is becoming impossible to pay and watch certain movies and shows without buying into a full subscription in a service. We will likely see the day where you will need a specific device to watch a specific movie. Where the only way to watch a Disney+ exclusive movie is on a Disney+ tablet. You don’t think so? Think about how easy it is to get your Kindle books onto another Ebook reader. How do you enable a skill or capability available in Alexa on your Nest smart speaker? How can you search through the books that you bought and are in your digital library, besides by using a service provided by the company that allows you to search your digital library? When you buy a movie today on YouTube or on iMovies, what do you own? What are you left with when the companies behind these services close that service, or go out of business altogether?
Devices and content we pay for, data we and our friends create, should be ours to use in empowering and creative ways. Services and content should not be locked in with a certain device or subscription service. The bundling of services, content, devices, and locking up user data creates monopolies that stifle innovation and creativity. I am not asking to give away services or content or devices for free, I am asking to be allowed to pay for them and then use them as I see fit.
What can we do?
As far as I can tell, the solution, unfortunately, seems to be to ask for regulation. The market won’t solve it. The market doesn’t solve monopolies and oligopolies.
But don’t ask to regulate the tech giants individually. We don’t need a law that regulates Google and a law that regulates Apple and a law that regulates Amazon and a law to regulate Microsoft. We need laws to regulate devices, laws to regulate services, laws to regulate content, laws that regulate AI.
Don’t ask for Facebook to be broken up because you think Mark Zuckerberg is too rich and powerful. Breaking up Facebook, creating Baby Books, will ultimately make him and other Facebook shareholders richer than ever before. But breaking up Facebook will require the successor companies to work together on a protocol to collaborate. To share data. To be able to move from one service to another.
We need laws that require that every device we buy can be made fully ours. Yes, sure, Apple must still be allowed to provide us with the wonderful smooth User Experience we value Apple for. But we must also be able to access and share the data from the sensors in our devices that we have bought from them. We must be able to install and run software we have written or bought on the devices we paid for.
We need laws that require that our data is ours. We should be able to download our data from a service provider and use it as we like. We must be allowed to share with a friend the parts of our data we want to share with that friend. In real time, not in a dump download hours later. We must be able to take our social graph from one social service and move to a new service. The data must be sufficiently complete to allow for such a transfer, and not crippled.
We need laws that require that published content can be bought and used by us as we like. We should be able to store content on our hard disks. To lend it to a friend. To sell it. Anything I can legally do with a book I bought I must be able to legally do with a movie or piece of music I bought online. Just as with a book you are not allowed to give away the copies if the work you bought still enjoys copyright.
We need laws that require that services and capabilities are unbundled and made available to everyone. Particularly as technological progress with regards to AI, Quantum computing, and providing large amounts of compute becomes increasingly an exclusive domain for trillion dollar companies, we must enable other organizations and people to access these capabilities, or run the risk that sooner or later all and any innovation will be happening only in these few trillion dollar companies. Just because a company is really good at providing a specific service cheaply, it should not be allowed to unfairly gain advantage in all related areas and products and stifle competition and innovation. This company should still be allowed to use these capabilities in their products and services, but so should anyone else, fairly prized and accessible by everyone.
We want to unleash creativity and innovation. In our lifetimes we have seen the creation of technologies that would have been considered miracles and impossible just decades ago. These must belong to everybody. These must be available to everyone. There cannot be equity if all of these marvellous technologies can be only wielded by a few companies on the West coast of the United States. We must make them available to all the people of the world: the people of the Indian subcontinent, the people of Subsaharan Africa,the people of Latin America, and everyone else. They all should own the devices they paid for, the data they created, the content they paid for. They all should have access to the same digital services and capabilities that are available to the engineers at Amazon or Google or Microsoft. The universities and research centers of the world should be able to access the same devices and services and extend them with their novel and creative ideas. The scrappy engineers in Eastern Europe and India and Nigeria and Central Asia should be able to call the AI models trained by Google and Microsoft and use them in novel ways to run their devices and chip-powered cars and agricultural machines. We want a world of freedom, tinkering, where creativity and innovation are unleashed, and where everyone can contribute their ideas, their creativity, and where everyone can build their fortune.
Papaphobia
In a little knowledge engineering exercise, I was trying to add the causes of a phobia to the respective Wikidata items. There are currently about 160 phobias in Wikidata, and only a few listed in a structured way what they are afraid of. So I was going through them, trying to capture it in s a structured way. Here's a list of the current state:
Now, one of those phobias was the Papaphobia - the fear of the pope. Now, is that really a thing? I don't know. CDC does not seem to have an entry on it. On the Web, in the meantime, some pages have obviously taken to mining lists of phobias and creating advertising pages that "help" you with Papaphobia - such as this one:
This page is likely entirely auto-generated. I doubt it that they have "clients for papaphobia in 70+ countries", whom they helped "in complete discretion" within a single day! "People with severe fears and phobias like papaphobia (which is in fact the formal diagnostic term for papaphobia) are held prisoners by their phobias."
This site offers more, uhm, useful information.
"Group psychotherapy can also help where individuals share their experience and, in the process, understand and recover from their phobia." Really? There are enough cases that we can even set up a group therapy?
Now, maybe I am entirely off here - maybe, papaphobia is really a thing. With search in Scholar I couldn't find any medical sources (the term is mentioned in a number of sociological and historical works, to express general sentiments in a population or government against the authority of the pope, but I could not find any mentions of it in actual medical literature).
Now could those pages up there be benign cases of jokes? Or are they trying to scam people with promises to heal their actual fears, and they just didn't curate the list of fears sufficiently, because, really, you wouldn't find this page unless you actually search for this term?
And now what? Now what if we know these pages are made by scammers? Do we report them to the police? Do we send a tip to journalists? Or should we just do nothing, allowing them to scam people with actual fears? Well, by publishing this text, maybe I'll get a few people warned, but it won't reach the people it has to reach at the right time, unfortunately.
Also, was it always so hard to figure out what is real and what is not? Does papaphobia exist? Such a simple question. How should we deal with it on Wikidata? How many cases are there, if it exists? Did it get worse for people with papaphobia now that we have two people living who have been made pope?
My assumption now is that someone was basically working on a corpus, looking for words ending in -phobia, in order to generate a list of phobias. And then the term papaphobia from sociological and historical literature popped up, and it landed in some list, and was repeated in other places, etc., also because it is kind of a funny idea, and so a mixture of bad research and joking bubbled through, and rolled around on the Web for so long that it looks like it is actually a thing, to the point that there are now organizations who will gladly take your money (CTRN is not the only one) to treat you for papaphobia.
The world is weird.
Partial copyright for an AI generated work
Interesting development in US cases around copyright and AI: author Elisa Shupe asked for copyright registration on a book that was created with the help of generative AI. Shupe stated that not giving her registration would be disabilities discrimination, since she would not have been able to create her work otherwise. On appeal, her work was partially granted protection for the “selection, coordination, and arrangement of text generated by artificial intelligence”, without referral to the disability argument.
Pastir Loda
Vladimir Nazor is likely the most famous author from the island of Brač, the island my parents are from. His most acclaimed book seems to be Pastir Loda, Loda the Shepherd. It tells the story of a satyr that, through accidents and storms, was stranded on the island of Brač, and how he lived on Brač for the next almost two thousand years.
It is difficult to find many of his works, they are often out of print. And there isn't much available online, either. Since Nazor died in 1949, his works are in the public domain. I acquired a copy of Pastir Loda from an antique book shop in Zagreb, which I then forwarded to a friend in Denmark who has a book scanner, and who scanned the book so I can make the PDF available now.
The book is written in Croatian. There is a German translation, but that won't get into the public domain until 2043 (the translator lived until 1972), and according to WorldCat there is a Czech translation, and according to Wikipedia a Hungarian translation. For both I don't know who the translator is, and so I don't know the copyright status of these translations. I also don't know if the book has ever been translated to other languages.
I wish to find the time to upload and transcribe the content on Wikisource, and then maybe even do a translation of it into English. For now I upload the book to archive.org, and I also make it available on my own Website. I want to upload it to Wikimedia Commons, but I immediately stumbled upon the first issue, that it seems that to upload it to Commons the book needs to be published before 1928 and the author has to be dead for more than 70 years (I think that should be an or). I am checking on Commons if I can upload it or not.
Until then, here's the Download:
Philosophische Grundlagen
I had a talk on Philosophical Foundations of Ontologies last week at the AIFB. I prepared it in German (and thus, all the slides were in German) and just before I started I got asked if I may give the talk in English.
Having never heard a single lesson in philosophy in English and having read English philosophy only on Wikipedia before, I said yes. Nevertheless, the talk was very well perceived, and so I decided to upload it. It's pure evil PowerPoint, no semantic slides format, and I didn't yet manage to translate it to English. If anyone can offer me some help with that - I simply don't know many of the technical terms, and I don't have ready access to the sources - I would be very happy! Just drop me a note, please.
Philosophische Grundlagen der Ontologie (PowerPoint, ca. 4,5 MB)
Broken link
Playing around with Aliquot
- Warning! Very technical, not particularly insightful, and overly long post about hacking, discrete mathematics, and rabbit holes. I don't think that anything here is novel, others have done more comprehensive work, and found out more interesting stuff. This is not research, I am just playing around.
Ernest Davis is a NYU professor, author of many publications (including “Rebooting AI” with Gary Marcus) and a friend on Facebook. Two days ago he posted about Aliquot sequences, and that it is yet unknown how they behave.
What is an Aliquot sequence? Given a number, take all its proper divisors, and add them up. That’s the next number in the sequence.
It seems that most of these either lead to 0 or end in a repeating pattern. But it may also be that they just keep on going indefinitely. We don’t know if there is any starting number for which that is the case. But the smallest candidate for that is 276.
So far, we know the first 2,145 steps for the Aliquot sequence starting at 276. That results in a number with 214 digits. We don’t know the successor of that number.
I was curious. I know that I wouldn’t be able to figure this out quickly, or, probably ever, because I simply don’t have enough skills in discrete mathematics (it’s not my field), but I wanted to figure out how much progress I can make with little effort. So I coded something up.
Anyone who really wanted to make a crack on this problem would probably choose C. Or, on the other side of the spectrum, Mathematica, but I don’t have a license and I am lazy. So I chose JavaScript. There were two hunches for going with JavaScript instead of my usual first language, Python, which would pay off later, but I will reveal them later in this post.
So, my first implementation was very naïve (source code). The function that calculates the next step in the Aliquot sequence is usually called s in the literature, so I kept that name:
const divisors = (integer) => {
const result = []
for(let i = BigInt(1); i < integer; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
const sum = x => x.reduce( (partialSum, i) => partialSum + i, BigInt(0) )
const s = (integer) => sum(divisors(integer))
I went for BigInt, not integer, because Ernest said that the 2,145th step had 214 digits, and the standard integer numbers in JavaScript stop being exact before we reach 16 digits (at 9,007,199,254,740,991, to be exact), so I chose BigInt, which supports arbitrary long integer numbers.
The first 30 steps ran each under a second on my one decade old 4 core Mac occupying one of the cores, reaching 8 digits, but then already the 36th step took longer than a minute - and we only had 10 digits so far. Worrying about the limits of integers turned out to be a bit preliminary: With this approach I would probably not reach that limit in a lifetime.
I dropped BigInt and just used the normal integers (source code). That gave me 10x-40x speedup! Now the first 33 steps were faster than a second, reaching 9 digits, and it took until the 45th step with 10 digits to be the first one to take longer than a minute. Unsurprisingly, a constant factor speedup wouldn’t do the trick here, we’re fighting against an exponential problem after all.
It was time to make the code less naïve (source code), and the first idea was to not check every number smaller than the target integer whether it divides (line 3 above), but only up to half of the target integer.
const divisors = (integer) => {
const result = []
const half = integer / 2
for(let i = 1; i <= half; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
Tiny change. And exactly the expected impact: it ran double as fast. Now the first 34 steps ran under one second each (9 digits), and the first one to take longer than a minute was the 48th step (11 digits).
Checking until half of the target seemed still excessive. After all, for factorization we only need to check until the square root. That should be a more than constant speedup. And once we have all the factors, we should be able to quickly reconstruct all the divisors. Now this is the point where I have to admit that I have a cold or something, and the code for creating the divisors from the factors is probably overly convoluted and slow, but you know what? It doesn’t matter. The only thing that matters will be the speed of the factorization.
So my next step (source code) was a combination of a still quite naïve approach to factorization, with another function that recreates all the divisors.
const factorize = (integer) => {
const result = [ 1 ]
let i = 2
let product = 1
let rest = integer
let limit = Math.ceil(Math.sqrt(integer))
while (i <= limit) {
if (rest % i == 0) {
result.push(i)
product *= i
rest = integer / product
limit = Math.ceil(Math.sqrt(rest))
} else {
i++
}
}
result.push(rest)
return result
}
const divisors = (integer) => {
const result = [ 1 ]
const inner = (integer, list) => {
result.push(integer)
if (list.length === 0) {
return [ integer ]
}
const in_results = [ integer ]
const in_factors = inner(list[0], list.slice(1))
for (const f of in_factors) {
result.push(integer*f)
result.push(f)
in_results.push(integer*f)
in_results.push(f)
}
return in_results
}
const list = factorize(integer)
inner(list[0], list.slice(1))
const im = [...new Set(result)].sort((a, b) => a - b)
return im.slice(0, im.length-1)
}
That made a big difference! The first 102 steps all were faster than a second, reaching 20 digits! That’s more than 100x speedup! And then, after step 116, the thing crashed.
Remember, integer only does well until 16 digits. The numbers were just too big for the standard integer type. So, back to BigInt. The availability of BigInt in JavaScript was my first hunch for choosing JavaScript (although that would have worked just fine in Python 3 as well). And that led to two surprises.
First, sorting arrays with BigInts is different from sorting arrays with integers. Well, I find already sorting arrays of integers a bit weird in JavaScript. If you don’t specify otherwise it sorts numbers lexicographically, instead of by value:
[ 10, 2, 1 ].sort() == [ 1, 10, 2 ]
You need to provide a custom sorting function in order to sort the numbers by value, e.g.
[ 10, 2, 1 ].sort((a, b) => a-b) == [ 1, 2, 10 ]
The same custom sorting functions won’t work for BigInt, though. The custom function for sorting requires an integer result, not a BigInt. We can write something like this:
.sort((a, b) => (a < b)?-1:((a > b)?1:0))
The second surprise was that BigInt doesn’t have a square root function in the standard library. So I need to write one. Well, Newton is quickly implemented, or copy and pasted (source code).
Now, with switching to BigInt, we get the expected slowdown. The first 92 steps run faster than a second, reaching 19 digits, and then the first step to take longer than a minute is step 119, with 22 digits.
Also, the actual sequences started indeed diverging, due to the inaccuracy of large JavaScript integer: step 83 resulted in 23,762,659,088,671,304 using integers, but 23,762,659,088,671,300 using BigInt. And whereas that looks like a tiny difference on only the last digit, the number for the 84th step showed already what a big difference that makes: 20,792,326,702,587,410 with integers, and 35,168,735,451,235,260 with BigInt. The two sequences went entirely off.
What was also very evident is that at this point some numbers took a long time, and others were very quick. This is what you would expect from a more sophisticated approach to factorization, that it depends on the number and size of the factors. For example, calculating step 126 required to factorize the number 169,306,878,754,562,576,009,556, leading to 282,178,131,257,604,293,349,484, and that took more than 2 hours with that script on my machine. But then in Step 128 the result 552,686,316,482,422,494,409,324 was calculated from 346,582,424,991,772,739,637,140 in less than a second.
At that point I also started taking some of the numbers, and googled them, surfacing a Japanese blog post from ten years ago that posted the first 492 numbers, and also confirming that the 450th of these numbers corresponds to a published source. I compared the list with my numbers and was happy to see they corresponded so far. But I guesstimated I would not in a lifetime reach 492 steps, never mind the actual 2,145.
But that’s OK. Some things just need to be let rest.
That’s also when I realized that I was overly optimistic because I simply misread the number of steps that have been already calculated when reading the original post: I thought it was about 200-something steps, not 2,000-something steps. Or else I would have never started this. But now, thanks to the sunk cost fallacy, I wanted to push it just a bit further.
I took the biggest number that was posted on that blog post, 111,953,269,160,850,453,359,599,437,882,515,033,017,844,320,410,912, and let the algorithm work on that. No point in calculating steps 129, which is how far I have come, through step 492, if someone else already did that work.
While the computer was computing, I leisurely looked for libraries for fast factorization, but I told myself that no way am I going to install some scientific C library for this. And indeed, I found a few, such as the msieve project. Unsurprising, it was in C. But I also found a Website, CrypTool-Online with msieve on the Web (that’s pretty much one of the use cases I hope Wikifunctions will also support rather soonish). And there, I could not only run the numbers I already calculated locally, getting results in subsecond speed which took minutes and hours on my machine, but also the largest number from the Japanese website was factorized in seconds.
That just shows how much better a good library is than my naïve approach. I was slightly annoyed and challenged by the fact how much faster it is. Probably also runs on some fast machine in the cloud. Pretty brave to put a site like that up, and potentially have other people profit from the factorization of large numbers for, e.g. Bitcoin mining on your hardware.
The site is fortunately Open Source, and when I checked the source code I was surprised, delighted, and I understood why they would make it available through a Website: they don’t factorize the number in the cloud, but on the edge, in your browser! If someone uses a lot of resources, they don’t mind: it’s their own resources!
They took the msieve C library and compiled it to WebAssembly. And now I was intrigued. That’s something that’s useful for my work too, to better understand WebAssembly, as we use that in Wikifunctions too, although for now server side. So I rationalized, why not see if I can get that run on Node.
It was a bit of guessing and hacking. The JavaScript binding was written to be used in the browser, and the binary was supposed to be loaded through fetch. I guessed a few modifications, replacing fetch with Node’s FS, and managed to run it in Node. The hacks are terrible, but again, it doesn’t really matter as long as the factorization would speed up.
And after a bit of trying and experimenting, I got it running (source code). And that was my second hunch for choosing JavaScript: it had a great integration for using WebAssembly, and I figured it might come in handy to replace the JavaScript based solution. And now indeed, the factorization was happening in WebAssembly. I didn’t need to install any C libraries, no special environments, no nothing. I just could run Node, and it worked. I am absolutely positive there are is cleaner code out there, and I am sure I mismanaged that code terribly, but I got it to run. At the first run I found that it added an overhead of 4-5 milliseconds on each step, making the first few steps much slower than with pure JavaScript. That was a moment of disappointment.
But then: the first 129 steps, which I was waiting hours and hours to run, zoomed by before I could even look. Less than a minute, and all the 492 steps published on the Japanese blog post were done, allowing me to use them for reference and compare for correctness so far. The overhead was irrelevant, even across the 2,000 steps the overhead wouldn’t amount to more than 10 seconds.
The first step that took longer than a second was step 596, working on a 58 digit number. All the first 595 steps took less than a second each. The first step that took more than a minute, was step 751, a 76 digit number, taking 62 seconds, factorizing 3,846,326,269,123,604,249,534,537,245,589,642,779,527,836,356,985,238,147,044,691,944,551,978,095,188. The next step was done in 33 milliseconds.
The first 822 steps took an hour. Step 856 was reached after two hours, so that’s another 34 steps in the second hour. Unexpectedly, things slowed down again. Using faster machines, modern architectures, GPUs, TPUs, potentially better algorithms, such as CADO-NFS or GGNFS, all of that could speed that up by a lot, but I am happy how far I’ve gotten with, uhm, little effort. After 10 hours, we had 943 steps and a 92 digit number, 20 hours to get to step 978 and 95 digits. My goal was to reach step 1,000, and then publish this post and call it a day. By then, a number of steps already took more than an hour to compute. I hit step 1000 after about 28 and a half hours, a 96 digit number: 162,153,732,827,197,136,033,622,501,266,547,937,307,383,348,339,794,415,105,550,785,151,682,352,044,744,095,241,669,373,141,578.
I rationalize this all through “I had fun” and “I learned something about JavaScript, Node, and WebAssembly that will be useful for my job too”. But really, it was just one of these rabbit holes that I love to dive in. And if you read this post so far, you seem to be similarly inclined. Thanks for reading, and I hope I didn’t steal too much of your time.
I also posted a list of all the numbers I calculated so far, because I couldn’t find that list on the Web, and I found the list I found helpful. Maybe it will be useful for something. I doubt it. (P.S.: the list was already on the Web, I just wasn't looking careful enough. Both, OEIS and FactorDB have the full list.)
I don’t think any of the lessons here are surprising:
- for many problems a naïve algorithm will take you to a good start, and might be sufficient
- but never fight against an exponential algorithm that gets big enough, with constant speedups such as faster hardware. It’s a losing proposition
- But hey, first wait if it gets big enough! Many problems with exponential complexity are perfectly solvable with naïve approaches if the problem stays small enough
- better algorithms really make a difference
- use existing libraries!
- advancing research is hard
- WebAssembly is really cool and you should learn more about it
- the state of WebAssembly out there can still be wacky, and sometimes you need to hack around to get things to work
In the meantime I played a bit with other numbers (thanks to having a 4 core computer!), and I will wager one ambitious hypothesis: if 276 diverges, so does 276,276, 276,276,276, 276,276,276,276, etc., all the way to 276,276,276,276,276,276,276,276,276, i.e. 9 times "276".
I know that 10 times "276" converges after 300 steps, but I have tested all the other "lexical multiples" of 276, and reached 70 digit numbers after hundreds of steps. For 276,276 I pushed it further, reaching 96 digits at step 640. (And for at least 276,276 we should already know the current best answer, because the Wikipedia article states that all the numbers under one million have been calculated, and only about 9,000 have an unclear fate. We should be able to check if 276,276 is one of those, which I didn't come around to yet).
Again, this is not research, but just fooling around. If you want actual systematic research, the Wikipedia article has a number of great links.
Thank you for reading so far!
P.S.: Now that I played around, I started following some of the links, and wow, there's a whole community with great tools and infrastructure having fun about Aliquot sequences and prime numbers doing this for decades. This is extremely fascinating.
Popculture in logics
- You ⊑ ∀need.Love (Lennon, 1967)
- ⊥ ≣ compare.You (Nelson, 1985)
- Cowboy ⊑ ∃sing.SadSadSong (Michaels, 1988)
- ∀t : I ⊑ love.You (Parton, 1973)
- ∄better.Time ⊓ ∄better⁻¹.Time (Dickens, 1859)
- {god} ⊑ Human ⊨ ? (Bazilian, 1995)
- Bad(X)? (Jackson, 1987)
- ⃟(You ⊑ save.I) (Gallagher, 1995)
- Dreamer(i). ∃x : Dreamer(x) ∧ (x ≠ i). ⃟ ∃t: Dreamer(you). (Lennon, 1971)
- Spoon ⊑ ⊥ (Wachowski, 1999)
- ¬Cry ← ¬Woman (Marley, 1974)
- ∄t (Poe, 1845)
Solutions: Turn around your monitor to read them.
sǝlʇɐǝq ǝɥʇ 'ǝʌol sı pǝǝu noʎ llɐ ˙ǝuo
ǝɔuıɹd ʎq ʎllɐuıƃıɹo sɐʍ ʇı 'ƃuos ǝɥʇ pǝɹǝʌoɔ ʇsnɾ pɐǝuıs ˙noʎ oʇ sǝɹɐdɯoɔ ƃuıɥʇou ˙oʍʇ
˙uosıod ʎq uɹoɥʇ sʇı sɐɥ ǝsoɹ ʎɹǝʌǝ ɯoɹɟ '"ƃuos pɐs pɐs ɐ sƃuıs ʎoqʍoɔ ʎɹǝʌǝ" ˙ǝǝɹɥʇ
ʞɔɐɹʇpunos ǝıʌoɯ pɹɐnƃʎpoq ǝɥʇ ɹoɟ uoʇsnoɥ ʎǝuʇıɥʍ ʎq ɹɐlndod ǝpɐɯ ʇnq uoʇɹɐd ʎllop ʎq ʎllɐuıƃıɹo 'noʎ ǝʌol sʎɐʍlɐ llıʍ ı 'ɹo - ",noʎ, ɟo ǝɔuɐʇsuı uɐ ɥʇıʍ pǝllıɟ ,ǝʌol, ʎʇɹǝdoɹd ɐ ƃuıʌɐɥ" uoıʇdıɹɔsǝp ǝɥʇ ʎq pǝɯnsqns ɯɐ ı 'ʇ sǝɯıʇ llɐ ɹoɟ ˙ɹnoɟ
suǝʞɔıp sǝlɹɐɥɔ ʎq sǝıʇıɔ oʍʇ ɟo ǝlɐʇ ɯoɹɟ sǝɔuǝʇuǝs ƃuıuǝdo ǝɥʇ sı sıɥʇ ˙(ʎʇɹǝdoɹd ǝɥʇ ɟo ǝsɹǝʌuı suɐǝɯ 1- ɟo ɹǝʍod" ǝɥʇ) ǝɯıʇ ɟo ʇsɹoʍ ǝɥʇ sɐʍ ʇı ˙sǝɯıʇ ɟo ʇsǝq ǝɥʇ sɐʍ ʇı ˙ǝʌıɟ
(poƃ)ɟoǝuo ƃuıɯnsqns sn ʎq pǝlıɐʇuǝ sı ʇɐɥʍ sʞsɐ ʇı ʎllɐɔısɐq ˙ʇıɥ ɹǝpuoʍ ʇıɥ ǝuo 5991 ǝɥʇ 'sn ɟo ǝuo sɐʍ poƃ ɟı ʇɐɥʍ ˙xıs
pɐq ǝlƃuıs ʇıɥ ǝɥʇ uı "pɐq s,oɥʍ" ƃuıʞsɐ 'uosʞɔɐɾ lǝɐɥɔıɯ ˙uǝʌǝs
ɔıƃol lɐpoɯ ɯoɹɟ ɹoʇɐɹǝdo ʎılıqıssod ǝɥʇ sı puoɯɐıp ǝɥʇ ˙"ǝɯ ǝʌɐs oʇ ǝuo ǝɥʇ ǝɹ,noʎ ǝqʎɐɯ" ǝuıl ǝɥʇ sɐɥ ʇı ˙sısɐo ʎq 'llɐʍɹǝpuoʍ ˙ʇɥƃıǝ
˙ooʇ ǝuo ǝɹɐ noʎ ǝɹǝɥʍ ǝɯıʇ ɐ sı ǝɹǝɥʇ ǝqʎɐɯ puɐ ˙(ǝɯ ʇou ǝɹɐ sɹǝɥʇo ǝsoɥʇ puɐ 'sɹǝɯɐǝɹp ɹǝɥʇo ǝɹɐ ǝɹǝɥʇ) ǝuo ʎluo ǝɥʇ ʇou ɯɐ ı ʇnq ˙ɹǝɯɐǝɹp ɐ ɯɐ ı" ˙ǝuıƃɐɯı 'uıɐƃɐ uouuǝl uɥoɾ ˙ǝuıu
(ǝlɔɐɹo ǝɥʇ sʇǝǝɯ ǝɥ ǝɹoɟǝq ʇsnɾ oǝu oʇ ƃuıʞɐǝds pıʞ oɥɔʎsd ǝɥʇ) xıɹʇɐɯ ǝıʌoɯ ǝɥʇ ɯoɹɟ ǝʇonb ssɐlɔ ˙uoods ou sı ǝɹǝɥʇ ˙uǝʇ
ʎǝuoɯ ǝɯos sʇǝƃ puǝıɹɟ sıɥ os ƃuıʎl ʎlqɐqoɹd sɐʍ ǝɥ ʇnq 'puǝıɹɟ ɐ oʇ sɔıɹʎl ǝɥʇ pǝʇnqıɹʇʇɐ ʎǝlɹɐɯ ˙"ʎɹɔ ʇou" sʍolloɟ "uɐɯoʍ ʇou" ɯoɹɟ ˙uǝʌǝlǝ
ǝod uɐllɐ ɹɐƃpǝ ʎq '"uǝʌɐɹ ǝɥʇ" ɯoɹɟ ɥʇonb ˙ǝɹoɯɹǝʌǝu :ɹo ˙ǝɯıʇ ou sı ǝɹǝɥʇ ˙ǝʌlǝʍʇ
Power in California
It is wonderful to live in the Bay Area, where the future is being invented.
Sure, we might not have a reliable power supply, but hey, we have an app that connects people with dogs who don't want to pick up their poop with people who are desperate enough to do this shit.
Another example how the capitalism that we currently live failed massively: last year, PG&E was found responsible for killing people and destroying a whole city. Now they really want to play it safe, and switch off the power for millions of people. And they say this will go on for a decade. So in 2029 when we're supposed to have AIs, self-driving cars, and self-tieing Nikes, there will be cities in California that will get their power shut off for days when there is a hot wind for an afternoon.
Why? Because the money that should have gone into, that was already earmarked for, making the power infrastructure more resilient and safe went into bonus payments for executives (that sounds so cliché!). They tried to externalize the cost of an aging power infrastructure - the cost being literally the life and homes of people. And when told not to, they put millions of people in the dark.
This is so awfully on the nose that there is no need for metaphors.
San Francisco offered to buy the local power grid, to put it into public hands. But PG&E refused that offer of several billion dollars.
So if you live in an area that has a well working power infrastructure, appreciate it.
Prediction coming true
I saw my post from seven years ago, where I said that I really like Facebook and Google+, but I want a space where I have more control about my content so it doesn't just disappear. "Facebook and Google+ -- maybe they won't disappear in a year. But what about ten?"
And there we go, Google+ is closing in a few days.
I downloaded my data from there (as well as my data from Facebook and Twitter), to see if there is anything to be salvaged from that, but I doubt it.
Productivity pro tip
- make a list of all things you need to do
- keep that list roughly in order of priority, particularly on the first 3-5 items (lower on the list it doesn't matter that much)
- procrastinate the whole day from doing the number 1 item by doing the number 2 to 5 items
Progress in lexicographic data in Wikidata 2023
Here are some highlights of the progress in lexicographic data in Wikidata in 2023
- Greek jumped from 0% to 45% right away
- Panjabi jumped right away from 0% to 71% (but on an admittedly small corpus)
- Italian made a huge jump from 52% to 82% by increasing the number of forms from 9,000 to 286,000
- Turkish jumped from 0.9% to 22%
- Sindhi climbed from 15% to 25%
- Farsi climbed from 15% to 24% increasing the number of forms from 4,000 to 33,000
- Western Panjabi climbed from 36.9% to 47.9%
- Hindi climbed from 49.9% to 65.9%
- Breton increased from 56% to 67%
- Croatian increased from 40% to 45%
- Dutch went from 20% to 29%
- French from 82.9% to 86.9%, mostly by dealing better with apostrophes in the analysis
- Nynorsk pushed from 75% to 80% by increasing the number of forms from 18,000 to 68,000
- Danish from 83.9% to 86.9% by increasing the number of forms in Wikidata from 65,000 to 170,000
- German from 76% to 79% by increasing the number of forms in Wikidata from 90,000 to 200,000
- Spanish pushed from 88% to 91% by increasing the number of forms from 280,000 to 430,000
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data. Note that every percent more gets much more difficult than the previous one: an increase from 1% to 2% usually needs much much less work than from 91% to 92%.
RDF in Mozilla 2
I read last week Brendan Eich's post on Mozilla 2, where he said that with Moz2 they hope that they can "get rid of RDF, which seems to be the main source of "Mozilla ugliness"". Danny Ayers commented on this, saying that RDF "should be nurtured not ditched."
Well, RDF in Mozilla always was crappy, and it was based on a pre-1999-standard RDF. No one ever took up the task -- remind you, it's open source -- to dive into the RDF inside Mozilla and repair and polish it, make it a) compatible to the 2004 RDF standard, (why didn't RDF get version numbers, by the way?) and b) clean up the code and make it faster.
My very first encounter with RDF was through Mozilla. I was diving into Mozilla as a platform for application development, which seemed like a very cool idea back then (maybe it still is, but Mozilla isn't really moving into this direction). RDF was prominent there: as an internal data structure for the developed applications. Let's repeat that: RDF, which was developed to allow the exchange of data on the web, was used within Mozilla as an internal data structure.
Surprisingly, they had performance issues. And the code was cluttered with URIs.
I still think it is an interesting idea. In last year's Scripting for the Semantic Web workshop I presented an idea on integrating semantic technologies tightly into your programming. Marian Babik and Ladislav Hluchy picked that idea up and expanded and implemented the work much better than I ever could.
It would be very interesting how this combination could really be put to work. An internal knowledge base for your app that is queried via SPARQL. Doesn't sound like the most performant idea. But then -- imagine not having one tool accessing that knowledge base. But rather a system architecture with a number of tools accessing that knowledge base. Adding data to existing data. Imagine just firing up a newly installed Adressbook, and -- shazam! -- all your data is available. You don't like it anymore? Switch back. No changes lost. Everything is just views.
But then again, didn't the DB guys try to do the same? Yes, maybe. But with semantic web technology, shouldn't it be easier to do it, because it is meant to integrate?
Just thinking. Would love to see a set of tools based on a plugabble knowledge base. I'm afraid, performance would suck. I hope we will see.
RDF is not just for dreamers
Sometimes I stumble upon posts that leave me wonder, what actually do people think about the whole Semantic Web idea, and about standards like RDF, OWL and the like. Do you think academia people went out and purposefully made them complicated? That they don't want them to get used?
Christopher St. John wrote down some nice experience with using RDF for logging. And he was pretty astonished that "RDF can actually be a pretty nifty tool if you don't let it go to your head. And it worked great."
And then: "Using RDF doesn't actually add anything I couldn't have done before, but it does mean I get to take advantage of tons of existing tools and expertise." Well, that's pretty much the point of standards. And the point of the whole Semantic Web idea. There won't be anything you will be able to do later, that you're not able to do today! You know, assembler was pretty turing-complete already. But having your data in standard formats helps you. "You can buy a book on RDF, but you're never going to buy a book on whatever internal debug format you come up with"
Stop being surprised that some things on the Semantic Web work. And don't expect miracles either.
RIP Christopher Alexander
RIP Christopher Alexander, the probably most widely read actual architect in all of computer science. His work, particularly his book "A Pattern Language" was popularized, among others, by the Gang of Four and Design Pattern work, and is frequently read and cited in Future of Programming and UX circles for the idea that everyone should be able to create, but in order to enable them, they need patterns that make creation possible. His work inspired Ward Cunningham when developing wikis and Will Wright when developing that most ungamelike of games, Sim City. Alexander died on March 17, 2022 at the age of 85.
RIP Niklaus Wirth
RIP Niklaus Wirth;
BEGIN
I don't think there's a person who created more programming languages that I used than Wirth: Pascal, Modula, and Oberon; maybe Guy Steele, depending on what you count;
Wirth is also famous for Wirth's law: software becomes slower more rapidly than hardware becomes faster;
He received the 1984 Turing Award, and had an asteroid named after him in 1999; Wirth died at the age of 89;
END.
RIP Steve Wilhite
RIP Steve Wilhite, who worked on CompuServe chat for decades and was the lead of the CompuServe team that developed the GIF format, which is still widely used, and which made the World Wide Web a much more colorful and dynamic place by having a format that allowed for animations. Wilhite incorrectly insisted on GIF being pronounced Jif. Wilhite died on March 14, 2022 at the age of 74.
Rainbows end
Rainbows end.
The book, written in 2006, was set in 2025 in San Diego. Its author, Vernor Vinge, died yesterday, March 20, 2024, in nearby La Jolla, at the age of 79. He is probably best known for popularizing the concept of the Technological Singularity, but I found many other of his ideas far more fascinating.
Rainbows end explores themes such as shared realities, digital surveillance, and the digitisation of the world, years before Marc Andreessen proclaimed that "software is eating the word", describing it much more colorfully and rich than Andreessen ever did.
His other work that I enjoyed is True Names, discussing anonymity and pseudonymity on the Web. A version of the book was published with essays by Marvin Minsky, Danny Hillis, and others. who were inspired by True Names.
His Science Fiction was in a rare genre, which I love to read more about: mostly non-dystopian, in the nearby future, hard sci-fi, and yet, imaginative, exploring novel technologies and their implications on individuals and society.
Rainbows end.
Released dlpconvert
There's so much to do right now here, and even much, much more I'd like to do - and thus I'm getting a bit late on my announcements. Finally, here we go: dlpconvert is released in a 0.5 version.
You probably think: what is dlpconvert? dlpconvert is able to convert ontologies, that are within the dlp-fragment, from one syntax - namely the OWL XML Presentation Syntax- into another, here Datalog. Thus you can just take your ontology, convert it and then use the result as your program in your Prolog-engine. Isn't that cool?
Well, it would be much cooler if it were stronger tested, and if it could read some more common syntaxes like RDF/XML-Serialisation of OWL ontologies, but both is on the way. As for testing I would hope that you may test a bit - as for the serialisation, it should be available pretty soon.
dlpconvert is based totally on KAON2 for the reduction of the ontology.
I will write more as soon as I have more time.
Research visit
So, I have arrived for my very first longer research visit. I am staying at the Laboratory of Applied Ontologies in Rome. I have never been to Rome before, and all my type of non-work experience I'll chat about in my regular blog, in German. Here I'll stick to Semantic Stuff and such.
So, if you are nearby and would like to meet -- give me a note! I am staying in Rome up to the WWW, i.e. up to May 20th. The plan is to work on my dissertation topic, Ontology Evaluation, especially in the wake of the EON2006 workshop, but that's not all it seems. People are interested in and knowledge about Semantic Wikis as well. So there will be quite a lot stuff happening in the next few weeks -- I'm excited about it all.
Who knows what will happen? If my plan works out, at the end of the stay we will have a common framework for Ontology Evaluation. And I am not talking about this paper frameworks -- you know, that are presented in papers with titles starting "Towards a..." or "A framework for...". No, but real software, stuff you can download, and play with.
Restarting, 2019 edition
I had neglected Simia for too long - there were five entries in the last decade. A combination of events lead me to pour some effort back into it - and so I want to use this chance to restart it, once again.
Until this weekend, Simia was still running on a 2007 version of Semantic MediaWiki and MediaWiki - which probably helped with Simia getting hacked a year or two ago. Now it is up to date with a current version, and I am trying to consolidate what is already there with some content I had created in other places.
Also, life has been happening. If you have been following me on Facebook (that link only works if you're logged in), you have probably seen some of that. I married, got a child, changed jobs, and moved. I will certainly catch up on this too, but there is no point in doing that all in one huge mega-post. Given that I am thinking about starting a new project just these days, this might be the perfect outlet to accompany that.
I make no promises with regards to the quality of Simia, or the frequency of entries. What I would really love recreate would be a space that is as interesting and fun for as my Facebook wall was, before I stopped engaging there earlier this year - but since you cannot even create comments here, I have to figure out how to make this even remotely possible. For now, suggestions on Twitter or Facebook are welcome. And no, moving to WordPress or another platform is hardly an option, as I really want to stay with Semantic MediaWiki - but pointers to interesting MediaWiki extensions are definitely welcome!
Running out of text
Many of the available text corpora have by now been used for training language models. One untapped corpus so far have been our private messages and emails.
How fortunate that none of the companies that train large language models have access to humongous logs of private chats and emails, often larger than any other corpus for many languages.
How fortunate that those who do have well working ethic boards established, who would make sure that such requests are evaluated.
How fortunate that we have laws in place to protect our privacy.
How fortunate that when new models are published also the corpora are being published on which the models are being trained.
What? Your telling me, "Open"AI is keeping the training corpus for GPT-4 secret? The company closely associated with Microsoft, who own Skype, Office, Hotmail? The same Microsoft who just fired an ethics team? Why would all that be worrisome?
P.S.: To make it clear: I don't think that OpenAI has used private chat logs and emails as training data for GPT-4. But by not disclosing their corpora, they might be checking if they can get away with not being transparent, so that maybe next time they might do it. No one would know, right? And no one would stop them. And hey, if it improves the metrics...
SSSW Day 1
Today's invited speaker was Frank von Harmelen, co-editor of the OWL standard and author of the Semantic Web Primer. His talk was on fundamental research challenges generated by the Semantic Web (or: two dozen Ph.D. topics in a single talk). He had the idea after he was asked one day in the cafeteria "Hey Frank, whazzup in the Semantic Web?"
In the tradition of Immanuel Kant's four famous questions on philosophy, Frank posed the four big research challenges:
- Where does the metadata come from?
- Where do the ontologies come form?
- What to do with the many different ontologies?
- Where's the Web in the Semantic Web?
He derived many research questions that arise when you bring results from other fields (like databases, natural language, machine learning, information retrieval or knowledge engineering) to the Semantic Web and not just change the buzzwords, but take the implications that come along with the Semantic Web seriously.
Some more notes:
- What is the semantic equivalent to a 404? How should a reasoner handle the lack of referential integrity?
- Inference can be cheaper than lookup on the web.
- Today OWL lite would probably have become more like OWL DLP, but they didn't know better than
The other talks were given by Asun Gómez-Pérez on Ontological Engineering, and Sean Bechhofer on Knowledge Representation Languages for the SemWeb, pretty good stuff by the people who wrote the book. I just wonder if it was too fast for the people who didn't know about it already, and too repeting for the others, but well, that's always the problem with these kind of things.
The hands-on session later was interesting: we had to understand several OWL ontologies and explain certain inferences, and Natasha Noy helped us with the new Protégé 3.1. It was harder than I thought quite some times. And finally Aldo Gangemi was giving us some exercises with knowledge representation design patterns, based on DOLCE. This was hard stuff...
Wow, this was a lot of namedropping. The social programme (we were hiking today) around the summer school, and the talks with the peers are sometimes even more interesting than the actual summer school programme itself, but this probably won't be too interesting for most of you, and it's getting late as well, so I just call it a day.
SSSW Day 2
Natasha Noy gave the first talk today, providing a general overview on Mapping and Alignment algorithms and tools. Even though I was not too interested in the topic, she really caught my interest with a good and clean and structured talk. Thank for that! After, Steffen Staab continued, elaborating on the QOM approach to ontology mapping, having some really funny slides, but, as this work was mostly developed in Karlsruhe I already knew it. I liked his appeal for more tools that are just downloadable and usable, without having to fight for hours or days just to create the right environment for them. I totally agree on that!
The last talk of the day was from Aldo Gangemi on Ontology Evaluation. As I consider making this the theme of my PhD-thesis - well, I am almost decided on that - I was really looking forward to his talk. Although it was partially hard to follow, because he covered quite a broad approach to this topic, there have been numerous interesting ideas and a nice bibliography. Much to work on. I especially didn't yet see the structural measures he presented applied to the Semantic Web. Not knowing any literature on them, I am still afraid, that they actually fail [SSSW Day 1|Frank's requirements from yesterday]]: not just to be taken from graph theory, but rather to have the full implications of the Semantic Web paradigm been applied to them and thought through. Well, if no one did that yet, there's some obvious work left for me ;)
The hands-on-sessions today were quite stressy, but nevertheless interesting. First, we had to powerconstruct ontologies about different domains of traveling: little groups of four persons working on a flight agency ontology, a car rental service ontology and a hotel ontology. Afterwards, we had to integrate them. Each exercise had to be done in half a hour. We pretty much failed miserably in both, but we surely encountered many problems - which was the actual goal: in OWL DL you can't even concatenate strings. How much data intefration can you do then?
The second hands-on-session was on evaluationg three ontologies. It was quite interesting, although I really think that many of these things can happen automatically (I will work on this in the next two weeks, I hope). But the discussion afterwards was quite revealing, as it showed how differently people think about some quite fundamental issues, the importance they give to structural measures compared to the functional ones. Or, differently said: the question is, is a crappy ontology on a given domain better than a good ontology that doesn't cover your domain of interest? (The question sounds strange to you? To me as well, but well...)
Pitily I had to miss today's social special event, a football match between the students of the Summer School. Instead I had a very interesting chat with a colleague from the UPM, who came here for a talk, and who also wants to make her PhD in Ontology Evaluation, Mari Carmen Suárez de Figueroa. Interesting times are lying ahead.
SSSW Day 3
Yeah, sure, the Summer School for the Semantic Web is over for quite a while now, and here I started to blog about it daily, and didn't manage to get over the first three days. Let's face it: it was too much! The program was so dense, the social events so enjoyable, I couldn't even spare half an hour a day to continue the blogging. Now I want to recap some of my notes and memories I have of the second half of the Summer School. My bad memory be damned - if you want to correct something feel free to do so.
This day's invited speaker was Roberto Basili of the University of Rome. He sketched the huge field of natural language processing, and although he illustrated the possible interactions between lexical knowledge bases and ontologies, he nevertheless made a strong distinction between these two. Words are not concepts. "The name should have no value for defining a concept." This is like "Don't look into URIs" for HLT-people. He made a very interesting point: abductions will become very important in the Semantic Web, as they model human thinking patterns much closer than strict deduction does. Up until this day I was quite against abductions, I discussed this issue very stubbornly in Granada. But Roberto made me aware of a slightly different viewpoint: just sell abductive resolutions as suggestions, as proposals to the user - et voilà, the world is a better place! I will have to think abou this a bit more some day, but he did made me think.
The theoretical sessions and workshops today were packed and strenuos: we jumped from annotations to Semantic Web Services and back again. Fabio Ciravegna of the University of Sheffield's NLP-Group, who created tools like Armadillo and GATE, gave us a thorough introduction to annotations for the Semantic Web and the usage of Human Language Technologies in order to enhance this task. He admitted that many of the tools are still quite unhandy, but he tried to make a point by saying: "No one writes HTML today anymore with a text editor like Emacs or Notepad... or do you?"
All students raised their hands. Yes, we do! "Well, in the real world at least they don't..."
He also made some critical comments on the developments of the Semantic Web: the technologies being developed right now allow for a today unknown ability of collecting and combining data. Does this mean, our technologies actually require a better world? One with no secrets, privacy and spam, because there is no need for such ideas? Is metadata just adding hay to the haystak instead of really finding the needle?
John Domingue's Talk on Semantic Web (Web) Services was a deep and profound introduction to the field, and especially to the IRS system developed by the KMi at Open University. He was defending WSMO valiantly, but due to time constraints pitily skipped the comparison with OWL-S. But he motivated the need for Semantic Web Services and sketched a possible solution.
The day ended in Cercedilla, where we besieged a local disco. I guess the people were hiding, "watch it, them nerds are coming!" ;) The music surprisingly old - they had those funny vinyl albums - but heck, Frank Sinatra is never outdated. But the 80s certainly are...
SSSW Day 4
This day no theoretical talks, but instead two invited speakers - and much social programme, with a lunch at a swimming pool and a dinner in Segovia. Segovia is a beautiful town, with a huge, real, still standing roman aqueduct. Stunning. And there I ate the best pork ever! The aqueduct survived the huge earthquake of Lisbon of 1755, although houses around it crumbled and broke. This is, because it is built without any mortar - just stone over stone. So the stones could swing and move slightly, and the construction survived.
Made me think of loosely coupled systems. I probably had too much computer science the last few days.
The talks were very different today: first was Mike Woolridge of the University of Liverpool. He talked about Multiagent Systems in the past, the present and the future. He identified five trends in computing: Ubiquity, Interconnection, Intelligence, Delegation and Human-orientation.
His view on intelligence was very interesting: it is about the complexity of tasks that we are able to automate and delegate to computers. He quoted John Alan Robertson - the guy who invented resolution calculus, a professor of philosophy - as exclaiming "This is Artificial Intelligence!", when he saw a presentation of the FORTRAN compiler at a conference. I guess the point was, don't mind about becoming as intelligent as humans, just mind at getting closer.
"The fact that humans were in control of cars - our grandchildren will be quite uncomfortable with this idea."
The second talk was returning to the Semantic Web in a very pragmatic way: how to make money with it? Richard Benjamins of iSOCO just flew in from Amsterdam where he was at the SEKT meeting, and he brought promising news about the developing market for Semantic Web technologies. Mike Woolridge was criticizing Richard's optimistic projections and noted that he also, about ten years ago, spent a lot of energy and money into the growing Multiagent market - and lost most of it. It was an interesting discussion - Richard being the believer, Mike the sceptic, and a lot of young people betting a few years worth of life on the ideas presented by the first one...
SSSW Day 5
Today (which is July 15th) just one talk. The rest of the day - beside the big dinner (oh well, yes, there was a phantastic dinner speech performed by Aldo Gangemi and prepared by Enrico and Asun if I understood it correctly, which was hilariously funny) and the disco - was available for work on the mini projects. But more about the mini projects in the next blog.
The talk was given by University of Manchester's Carol Goble (I like that website. It starts with the sentence "This web page is undergoing a major overhaul, and about time. This picture is 10 years old. the most recent ones are far too depressing to put on a web site." How many professors did you have that would have done this?). She gave a fun and nevertheless insightful talk about the Semantic Web and the Grid, describing the relationship between the two as a very long engagement. The grid is the old, grudgy, hard working groom, the Semantic Web the bride, being aesthetically pleasing and beautiful.
What is getting gridders excited? Flexible and extensible schemata, data fusion and reasoning. Sounds familiar? Yes, these are exactly the main features of Semantic Web technologies! The grid is not about accessing big computers (as most people think in the US, but they are a bit behind on this as well), it is about knowledge communities. But one thing is definitively lacking: scalability, people, scalability. They went to test a few Semantic Web technologies with a little data - 18 million triples. Every tool broke. The scalability lacks, even thought the ideas are great.
John Domingue pointed out, that scalability is not that much of a problem as it seems, because the TBoxes, where the actual reasoning will happen, will always remain relatively small. And the scalability issue with the ABoxes can be solved with classic database technology.
The grid offers real applications, real users, real problems. The Semantic Web offers a lot of solutions and discussions about the best solution - but lack surprisingly often an actual problem. So it is obvious that the two fit together very nicely. At the end, Carole described them as engaged, but not married yet.
At the end she quotes Trotsky: "Revolution is only possible when it becomes inevitable" (well, at least she claims it's Trosky, Google claims its Carole Goble, maybe someone has a source? - Wikiquote doesn't have it yet). The quote is in line with almost all speakers: the Semantic Web is not Revolution, it is Evolution, an extension of the current web.
Thanks for the talk, Carole!
SSSW Last Day
The Summer School on Ontological Engineering and the Semantic Web finished on Saturday, July 16th, and I can't remember having a more intense and packed week in years. I really enjoyed it - the tutorials, the invited talks, the workshops, the social events, the mini project - all of it was awesome. It's a pity that it's all over now.
Today, besides the farewells and thank yous and the party in Madrid with maybe half of the people, also saw the presentation of the mini projects. The mini projects where somewhat similar to the The Semantic Web In One Day we had last year - but without a real implementation. Groups of four or five people had to create a Semantic Web solution in only six hours (well, at least conceptually).
The results were interesting. All of them were well done and highlighted some promising use cases for the Semantic Web, where data integration will play an important role: going out in the evening, travelling, dating. I'd rather not consider too deeply if computer scientists are rather attacking an own itch here ;) I really enjoyed the Peer2Peer theater, where messages wandered through the whole class room in order to visualize the system. This was fun.
Our own mini project modelled the Summer School and the projects itself, capturing knowledge about the buildup of the groups and classifying them. We had to use not only quite complex OWL constructs, but also SWRL-rules - and we still had problems expressing a quite simple set of rules. Right now we are trying to write these experiences down in a paper, I will inform you here as soon as it is ready. Our legendary eternal struggle at the boundaries of sanity and Semantic Web technologies seemed to be impressive enough to have earned us a cool price. A clock.
Thanks to all organizers, tutors and invited speakers of the Summer School, thanks to all the students as well, for making it such a great week. Loved it, really. I hope to stay in touch with all of you and see you at some conference pretty soon!
SWAT4HCLS trip report
This week saw the 12th SWAT4HCLS event in Edinburgh, Scotland. It started with a day of tutorials and workshops on Monday, December 10th, on topics such as SPARQL, querying, ontology matching, and using Wikibase and Wikidata.
Conference presentations went on for two days, Tuesday and Wednesday. This included four keynotes, including mine on Wikidata, and how to move beyond Wikidata (presenting the ideas from my Abstract Wikipedia papers). The other three keynotes (as well as a number of the paper presentation) were all centered on the FAIR concept which I already saw being so prominent at the eScience conference earlier this year. FAIR as in Findable, Accessible, Interoperable, and Reusable publication of data. I am very happy to see these ideas spread out so prominently!
Birgitta König-Ries talked about how to use semantic technologies to manage FAIR data. Dov Greenbaum talked about how licenses interplay with data and what it means for FAIR data - personally, my personal favorite of the keynotes, because of my morbid fascination regarding licenses and intellectual property rights pertaining to data and knowledge. He actually confirmed my understanding of the area - that you can’t really use copyright for data, and thus the application of CC-BY or similar licenses to data would stand on shaky grounds in a court. The last keynote was by Helen Parkinson, who gave a great talk on the issues that come up when building vocabularies, including issues around over-ontologizing (and the siren call of just keeping on modeling) and others. She put the issues in parallel to the travels of Odysseus, which was delightful.
The conference talks and posters were really on spot on the topic of the conference: using semantic web technologies in the life sciences, health care, and related fields. It was a very satisfying experience to see so many applications of the technologies that Semantic Web researchers and developers have been creating over the years. My personal favorite was MetaStanza, web components that visualize SPARQL results in many different ways (a much needed update to SPARK, that Andreas Harth and I had developed almost a decade ago).
On Thursday, the conference closed with a Hackathon day, which I couldn’t attend unfortunately.
Thanks to the organizers for the event, and thanks again for the invitation to beautiful Edinburgh!
Other trip reports (send me more if you have them):
SWSA panel
Thursday, October 7, 2021, saw a panel of three founding members of the Semantic Web research community, who each have been my teachers and mentors over the years: Rudi Studer, Natasha Noy, and Jim Hendler. I loved watching the panel and enjoyed it thoroughly, also because it was just great to see all of them again.
There were many interesting insights and thoughts in this panel, too many to write them all down, but I want to mention a few.
It was interesting how much all panelists talked about creating the Semantic Web community, and how much of an intentional effort that was. Deciding that it needs a conference, a journal, an organization, setting those up, and their interactions. Seeing and fostering a sustainable research community grown out of an idea is a formidable and amazing effort. They all mentioned positively the diversity in the community, and that it was a conscious effort to work towards that. Rudi mentioned that the future challenge will be with ensuring that computer science students actually have Semantic Web technologies integrated into their standard curriculum.
They named a number of the successes that were influenced by the Semantic Web research work, such as Schema.org, the heavy use of SPARQL in supercomputing (I had no idea!), Wikidata (thanks for the shout out, Rudi!), and the development of scalable graph databases. Natasha raised the advantage of having common identifiers throughout an organization, i.e. that everyone refers to California the same way. They also named areas that remained elusive and that they expect to see progress in the coming years, Rudi in particular mentioned Agents and Common Sense, which was echoed by the other participants, and Jim mentioned Personal Knowledge Graphs. Jim mentioned he was surprised by the growing importance of unstructured data. Jim is also hoping for something akin to “procedural attachments” - you see some new data coming in, you perform this action (I would like to think that a little Wikifunctions goes a long way).
We need both, open knowledge graphs and closed knowledge graphs (think of your personal ones, but also the ones by companies).
The most important contribution so far and also well into the future was the idea of decentralization of semantics. To allow different stakeholders to work asynchronously and separately on parts of the semantics and yet share data. This also includes the decentralization of knowledge graphs, but also in the future we will encounter a world where semantics are increasingly brought together and yet decentralized.
One interesting anecdote was shared by Natasha. She was talking about a keynote by Guha (one of the few researchers who were namechecked in the panel, along with Tim Berners-Lee) at ISWC in Sydney 2013. How Guha was saying how simple the technology needs to be, and how there were many in the audience who were aghast and shocked by the talk. Now, eight years later and given her experience building Dataset Search, she appreciates the insights. If they have a discussion about a new property for longer than five minutes, they drop it. It’s too complicated, and people will use it wrong so often that the data cleanup will become expensive.
All of them shared the advice for researchers in their early career stage to work on topics that truly inspire them, on problems that are real and that they and others care about, and that if they do so, the results have the best chance to have impact. Think about problems you can explain to people not in your field, about “how can we use triples to save the world” - and not just about “hey, look, that problem that we solved with these other technologies previously, now we can also solve it with Semantic Web technologies”. This doesn’t really help anyone. Solve new problems. Solve real problems. And do what you are truly passionate about.
I enjoyed the panel, and can recommend everyone in the Semantic Web research area or any related, nearby research, to check it out. Thanks to the organizers for this talk (which is the first session in a series of talks that will continue with Ora Lassila early December).
Sam Altman and the veil of ignorance
(This is not about Altman having been removed as CEO of OpenAI)
During the APEC forum on Thursday, Sam Altman has been cited to having said the following thing: "Four times now in the history of OpenAI—the most recent time was just in the last couple of weeks—I’ve gotten to be in the room when we push the veil of ignorance back and the frontier of discovery forward. And getting to do that is like the professional honor of a lifetime."
He meant that as an uplifting quote to describe how awesome his company and their achievements are.
I find it deeply worrying. Why?
The "veil of ignorance" (also known as the original position) is a thought experiment introduced by John Rawls, one of the leading American moral and political philosophers of the 20th century. The goal is to think about the fairness of a society or a social system without you knowing where in the system you end up: are you on top or at the bottom? What are your skills, your talents? Who are your friends? Do you have disabilities? What is your gender, your family history?
The whole point is to *not* push the veil of ignorance back, otherwise you'll create an unfair system. It is a good tool to think about the coming disruptions by AI technology.
The fact that he's using that specific term but is obviously entirely oblivious to its meaning tells us that there was a path that term took, probably from someone working on ethics to then-CEO Altman, and that someone didn't listen. The meaning was lost, and the beautiful phrase was entirely repurposed.
Given that's coming from the then-CEO of the company that claims and insists on, again and again (without substantial proof) that they are doing all this for the greater benefit of all humanity, that are, despite their name, increasingly closing their results, making public scrutiny increasingly difficult if not impossible - well, I find that worrying. The quote indicates that they have no idea about a basic tool towards evaluating fairness, even worse, have heard about it - but they have not listened or comprehended.
San Francisco and Challenges
Time is running totally crazy on me in the last few weeks. Right now I am in San Francisco -- if you like to suggest a meeting, drop me a line.
The CKC Challenge is going on and well! If you didn't have the time yet, check it out! Everybody is speaking about how to foster communities for shared knowledge building, this challenge is actually doing it, and we hope to get some good numbers and figures out of it. An fun -- there is a mystery prize involved! Hope to see as many of you as possible at the CKC 2007 in a few days!
Yet another challenge with prizes is going on at Centiare. Believe it or not, you can actually make money with using a Semantic MediaWiki, wih the Centiare Prize 2007. Read more there.
Saturn the alligator
Today at work I learned about Saturn the alligator. Born to humble origins in 1936 in Mississippi, he moved to Berlin where he became acquainted with Hitler. After the bombing of the Berlin Zoo he wandered through the streets. British troops found him, gave him to the Soviets, where against all odds he survived a number of near death situations - among others he refused to eat for a year - and still lives today, in an enclosure sponsored by Lacoste.
I also went to Wikidata to improve the entry on Saturn. For that I needed to find the right property to express the connection between Saturn, and the Moscow Zoo, where he is held.
The following SPARQL query was helpful: https://w.wiki/7ga
It tells you which properties connect animals with zoos how often - and in the Query Helper UI it should be easy to change either types to figure out good candidates for the property you are looking for.
Semantic MediaWiki 0.6: Timeline support, ask pages, et al.
It has been quite a while since the last release of Semantic MediaWiki, but there was enormous work going into it. Huge thanks to all contributors, especially Markus, who has written the bulk of the new code, reworked much of the existing, and pulled together the contributions from the other coders, and the Simile team for their great Timeline code that we reused. (I lost overview, because the last few weeks have seen some travels and a lot of work, especially ISWC2006 and the final review of the SEKT project I am working on. I will blog on SEKT more as soon as some further steps are done).
So, what's new in the second Beta-release of the Semantic MediaWiki? Besides about 2.7 tons of code fixes, usability and performance improvements, we also have a number of neat new features. I will outline just four of them:
- Timeline support: you know SIMILE's Timeline tool? No? You should. It is like Google Maps for the fourth dimension. Take a look at the Timeline webpage to see some examples. Or at ontoworld's list of upcoming events. Yes, created dynamically out of the wiki data.
- Ask pages: the simple semantic search was too simple, you think? Now we finally have a semantic search we dare not to call simple. Based on the existing Ask Inline Queries, and actually making them also fully functional, the ask pages allow to dynamically query the wiki knowledge base. No more sandbox article editing to get your questions answered. Go for the semantic search, and build your ask queries there. And all retrievable via GET. Yes, you can link to custom made queries from everywhere!
- Service links: now all attributes can automatically link to further resources via the service links displayed in the fact box. Sounds abstract? It's not, it's rather a very powerful tool to weave the web tighter together: service links specify how to connect the attributes data to external services that use that data, for example, how to connect geographic coordinates with Yahoo maps, or ontologies with Swoogle, or movies with IMdb, or books with Amazon, or ... well, you can configure it yourself, so your imagination is the limit.
- Full RDF export: some people don't like pulling the RDF together from many different pages. Well, go and get the whole RDF export here. There is now a maintenance script included which can be used via a cron job (or manually) to create an RDF dump of the whole data inside the wiki. This is really useful for smaller wikis, and external tools can just take that data and try to use it. By the way, if you have an external tool and reuse the data, we would be happy if you tell us. We are really looking forward to more examples of reuse of data from a Semantic MediaWiki installation!
I am looking much forward to December, when I can finally join Markus again with the coding and testing. Thank you so very much for your support, interest, critical and encouraging remarks with regards to Semantic MediaWiki. Grab the code, update your installation, or take the chance and switch your wiki to Semantic MediaWiki.
Just a remark: my preferred way to install both MediaWiki and Semantic MediaWiki is to pull it directly from the SVN instead of taking the releases. It's actually less work and helps you tremendously in keeping up to date.