Semantic search
Katherine Maher to step down from Wikimedia Foundation
Today Katherine Maher announced that she is stepping down as the CEO of the Wikimedia Foundation in April.
Thank you for everything!
Keynote at SMWCon Fall 2020
I have the honor of being the invited keynote for the SMWCon Fall 2020. I am going to talk "From Semantic MediaWiki to Abstract Wikipedia", discussing fifteen years of Semantic MediaWiki, how it all started, where we are now - crossing Freebase, DBpedia, Wikidata - and now leading to Wikifunctions and Abstract Wikipedia. But, more importantly, how Semantic MediaWiki, over all these years, still holds up and what its unique value is.
Page about the talk on the official conference site: https://www.semantic-mediawiki.org/wiki/SMWCon_Fall_2020/Keynote:_From_Semantic_Wikipedia_to_Abstract_Wikipedia
Keynote at Web Conference 2021
Today, I have the honor to give a keynote at the WWW Confe... sorry, the Web Conference 2021 in Ljubljana (and in the whole world). It's the 30th Web Conference!
Join Jure Leskovec, Evelyne Viegas, Marko Grobelnik, Stan Matwin and myself!
I am going to talk about how Abstract Wikipedia and Wikifunctions aims to contribute to Knowledge Equity. Register here for free:
Update: the talk can now be watched on VideoLectures:
Knowledge Graph Conference 2019, Day 1
On Tuesday, May 7, began the first Knowledge Graph Conference. Organized by François Scharffe and his colleagues at Columbia University, it was located in New York City. The conference goes for two days, and aims at a much more industry-oriented crowd than conferences such as ISWC. And it reflected very prominently in the speaker line-up: especially finance was very well represented (no surprise, with Wall Street being just downtown).
Speakers and participants from Goldman Sachs, Capital One, Wells Fargo, Mastercard, Bank of America, and others were in the room, but also from companies in other industries, such as Astra Zeneca, Amazon, Uber, or AirBnB. The speakers and participants were rather open about their work, often listing numbers of triples and entities (which really is a weird metric to cite, but since it is readily available it is often expected to be stated), and these were usually in the billions. More interesting than the sheer size of their respective KGs were their use cases, and particularly in finance it was often ensuring compliance to insider trading rules and similar regulations.
I presented Wikidata and the idea of an Abstract Wikipedia as going beyond what a Knowledge Graph can easily express. I had the feeling the presentation was well received - it was obvious that many people in the audience were already fully aware of Wikidata and are actively using it or planning to use it. For others, particularly the SPARQL endpoint with its powerful visualization capabilities and the federated queries, and the external identifiers in Wikidata, and the approach to references for the claims in Wikidata were perceived as highlights. The proposal of an Abstract Wikipedia was very warmly received, and it was the first time no one called it out as a crazy idea. I guess the audience was very friendly, despite New York's reputation.
A second set of speakers were offering technologies and services - and I guess I belong to this second set by speaking about Wikidata - and among them were people like Juan Sequeda of Capsenta, who gave an extremely engaging and well-substantiated talk on how to bridge the chasm towards more KG adoption; Pierre Haren of Causality Link, who offered an interesting personal history through KR land from LISP to Causal Graphs; Dieter Fensel of OnLim, who had a a number of really good points on the relation between intelligent assistants and their dialogue systems and KGs; Neo4J, Eccenca, Diffbot.
A highlight for me was the astute and frequent observation by a number of the speakers from the first set that the most challenging problems with Knowledge Graphs were rarely technical. I guess graph serving systems and cloud infrastructure have improved so much that we don't have to worry about these parts anymore unless you are doing crazy big graphs. The most frequently mentioned problems were social and organizational. Since Knowledge Graphs often pulled data sources from many different parts of an organization together, with a common semantics, they trigger feelings of territoriality. Who gets to define the common ontology? What if the data a team provides has problems or is used carelessly, who's at fault? What if others benefit from our data more than we did even though we put all the effort in to clean it up? How do we get recognized for our work? Organizational questions were often about a lack of understanding, especially among engineers, for fundamental Knowledge Graph principles, and a lack of enthusiasm in the management chain - especially when the costs are being estimated and the social problems mentioned before become apparent. One particularly visible moment was when Bethany Sehon from Capital One was asked about the major challenges to standardizing vocabularies - and her first answer was basically "egos".
All speakers talked about the huge benefits they reaped from using Knowledge Graphs (such as detecting likely cliques of potential insider trading that later indeed got convicted) - but then again, this is to be expected since conference participation is self-selecting, and we wouldn't hear of failures in such a setting.
I had a great day at the inaugural Knowledge Graph Conference, and am sad that I have to miss the second day. Thanks to François Scharffe for organizing the conference, and thanks to the sponsors, OntoText, Collibra, and TigerGraph.
For more, see:
Knowledge Graph Technology and Applications 2019
Last week, on May 13, the Knowledge Graph Technology and Applications workshop happened, co-located with the Web Conference 2019 (formerly known as WWW), in San Francisco. I was invited to give the opening talk, and talked about the limits of Knowledge Graph technologies when trying to express knowledge. The talk resonated well.
Just like in last week's KGC, the breadth of KG users is impressive: NASA uses KGs to support air traffic management, Uber talks about the potential for their massive virtual KG over 200,000 schemas, LinkedIn, Alibaba, IBM, Genentech, etc. I found particularly interesting that Microsoft has not one, but at least four large Knowledge Graphs: the generic Knowledge Graph Satori; an Academic Graph for science, papers, citations; the Enterprise Graph (mostly LinkedIn), with companies, positions, schools, employees and executives; and the Work graph about documents, conference rooms, meetings, etc. All in all, they boasted more than a trillion triples (why is it not a single graph? No idea).
Unlike last week, the focus was less on sharing experiences when working with Knowledge Graphs, but more on academic work, such as query answering, mixing embeddings with KGs, scaling, mapping ontologies, etc. Given that it is co-located with the Web Conference, this seems unsurprising.
One interesting point that was raised was the question of common sense: can we, and how can we use a knowledge graph to represent common sense? How can we say that a box of chocolate may fit in the trunk of a car, but a piano would not? Are KGs the right representation for that? The question remained unanswered, but lingered through the panel and some QnA sessions.
The workshop was very well visited - it got the second largest room of the day, and the room didn’t feel empty, but I have a hard time estimating how many people where there (about 100-150?). The audience was engaged.
The connection with the Web was often rather tenuous, unless one thinks of KGs as inherently associated with the Web (maybe because they often could use Semantic Web standards? But also often they don’t). On the other side it is a good outlet within the Web Conference for the Semantic Web crowd and to make them mingle more with the KG crowd, I did see a few people brought together into a room that often have been separated, and I was able to point a few academic researchers to enterprise employees that would benefit from each other.
Thanks to Ying Ding from the Indiana University and the other organizers for organizing the workshop, and for all the discussion and insights it generated!
Update: corrected that Uber talked about the potential of their knowledge graph, not about their realized knowledge graph. Thanks to Joshua Shivanier for the correction! Also added a paragraph on common sense.
Languages with the best lexicographic data coverage in Wikidata 2023
Languages with the best coverage as of the end of 2023
- English 92.9%
- Spanish 91.3%
- Bokmal 89.1%
- Swedish 88.9%
- French 86.9%
- Danish 86.9%
- Latin 85.8%
- Italian 82.9%
- Estonian 81.2%
- Nynorsk 80.2%
- German 79.5%
- Basque 75.9%
- Portuguese 74.8%
- Malay 73.1%
- Panjabi 71.0%
- Slovak 67.8%
- Breton 67.3%
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data.
The list contains all languages where the data covers more than two thirds of the selected corpus.
Last Unicorn dreamcast
One thing my sister and I were doing from time to time was to think, if the Last Unicorn was remade as a live action movie, who would we cast in the different roles? It is sad to see how many of our dreamcast have since died: our favorite Prince Lir was Heath Ledger, and King Haggard, unsurprisingly, Christopher Lee.
Since I was reading the book with Little One, and now watched the movie again (for the 120th time or so), I was again going through my current dreamcast. Here we go.
- Lady Amalthea - Anna Taylor-Joy
- Schmendrick - Zach Braff, Donald Glover
- Molly Grue - Mia Farrow
- Prince Lir - Owen Wilson, no, getting too old; Liam Hemsworth? Chloe Moretz would be an interesting choice
- King Haggard - Anthony Hopkins, Jack Nicholson
Since it is en vogue, I also asked Bard and ChatGPT. Here's Bard:
- Jeff Bridges as Schmendrick the Magician
- Mia Farrow as Molly Grue
- Angela Lansbury as the Unicorn
- Daryl Hannah as Filidor
- Jeff Goldblum as Schmendrick's sidekick, Bungle
- Peter Dinklage as the Red Bull
- Uma Thurman as Mommy Fortuna
- Alan Rickman as King Haggard
OK, Alan Rickman is a great choice, but unfortunately dead. Uma Thurman as Mommy Fortuna is weird. Peter Dinklage as the Red Bull... why does the Red Bull need to be cast at all? Who are Bungle and Filidor? Angela Lansbury as the Unicorn / Lady Amalthea is... not the right choice. Also dead. Mia Farrow and Jeff Bridges are too obvious choices given their roles in the cast of the animation movie, also Angela Lansbury is from the original cast. I would give Bard a D for that answer.
ChatGPT says:
- Unicorn - Saoirse Ronan or Emma Watson
- Schmendrick - Timothee Chalamet or Eddie Redmayne
- Molly Grue - Meryl Streep or Helen Mirren
- King Haggard - Ian McKellen or Christopher Lee (if he were still alive)
- Prince Lir - Tom Holland or Ansel Elgort
- Mommy Fortuna - Tilda Swinton or Cate Blanchett
Not even close to my choice, but heck, those are good choices. Molly Grue and Mommy Fortuna seem both a bit over-cast. Prince Lir and Schmendrick are pretty brilliant choices. I am not particularly impressed by Emma Watson for Lady Amalthea, I could see Saoirse Ronan work.
I'd give a B+ to ChatGPT.
I feel like ChatGPT seems to go for actors and actresses that are popular with the crowd who likes The Last Unicorn? Not the worst choice.
I followed up with Bard to see who Bungle and Filidor are, because they don't appear neither in the book nor in the movie, if I remember correctly. So, "Bungle is a red unicorn who is Schmendrick's sidekick in the novel The Last Unicorn. He is a clumsy and incompetent unicorn, but he is also a loyal and brave friend. Bungle is played by Jeff Goldblum in the 1982 animated film adaptation of the novel." And "Filidor is a bard in the novel The Last Unicorn. He is a wandering minstrel who travels the land singing songs and telling stories. Filidor is a wise and kind-hearted man, and he is always willing to help those in need. He is played by Daryl Hannah in the 1982 animated film adaptation of the novel." That's entirely a fabrication.
Lexical masks in JSON
We have released lexical masks as ShEx files before, schemata for lexicographic forms that can be used to validate whether the data is complete.
We saw that it was quite challenging to turn these ShEx files into forms for entering the data, such as Lucas Werkmeister’s Lexeme Forms. So we adapted our approach slightly to publish JSON files that keep the structures in an easier to parse and understand format, and to also provide a script that translates these JSON files into ShEx Entity Schemas.
Furthermore, we published more masks for more languages and parts of speech than before.
Full documentation can be found on wiki: https://www.wikidata.org/wiki/Wikidata:Lexical_Masks#Paper
Background can be found in the paper: https://www.aclweb.org/anthology/2020.lrec-1.372/
Thanks Bruno, Saran, and Daniel for your great work!
Libertarian cities
I usually try to contain my "Schadenfreude", but reading this article made it really difficult to do so. It starts with the story of Rio Verde Foothills and its lack of water supply after it was intentionally built to circumvent zoning regulations regarding water supply, and lists a few other examples, such as
- "Grafton, New Hampshire. It’s a tiny town that was taken over by libertarians who moved there en masse to create their vision of heaven on earth. They voted themselves into power, slashed taxes and cut the town’s already minuscule budget to the bone. Journalist Matthew Hongoltz-Hetling recounts what happened next:
- 'Grafton was a poor town to begin with, but with tax revenue dropping even as its population expanded, things got steadily worse. Potholes multiplied, domestic disputes proliferated, violent crime spiked, and town workers started going without heat. ...'
- Then the town was taken over by bears."
The article is worth reading:
The Wikipedia article is even more damning:
- "Grafton is an active hub for Libertarians as part of the Free Town Project, an offshoot of the Free State Project. Grafton's appeal as a favorable destination was due to its absence of zoning laws and a very low property tax rate. Grafton was the focus of a movement begun by members of the Free State Project that sought to encourage libertarians to move to the town. After a rash of lawsuits from Free Towners, an influx of sex offenders, an increase of crime, problems with bold local bears, and the first murders in the town's history, the Libertarian project ended in 2016."
Lion King 2019
Wow. The new version of the Lion King is technically brilliant, and story-wise mostly unnecessary (but see below for an exception). It is a mostly beat-for-beat retelling of the 1994 animated version. The graphics are breathtaking, and they show how far computer-generated imagery has come. For a measly million dollar per minute of film you can get a photorealistic animal movies. Because of the photorealism, it also loses some of the charm and the emotions that the animated version carried - in the original the animals were much more anthropomorphic, and the dancing was much more exaggerated, which the new version gave up. This is most noticeable in the song scene for "I can't wait to be king", which used to be a psychedelic, color shifted sequence with elephants and tapirs and giraffes stacked upon each other, replaced by a much more realistic sequence full of animals and fast cuts that simply looks amazing (I never was a big fan of the psychedelic music scenes that were so frequent in many animated movies, so I consider this a clear win).
I want to focus on the main change, and it is about Scar. I know the 1994 movie by heart, and Scar is its iconic villain, one of the villains that formed my understanding of a great villain. So why would the largest change be about Scar, changing him profoundly for this movie? How risky a choice in a movie that partly recreates whole sequences shot by shot?
There was one major criticism about Scar, and that is that he played with stereotypical tropes of gay grumpy men, frustrated, denied, uninterested in what the world is offering him, unable to take what he wants, effeminate, full of cliches.
That Scar is gone, replaced by a much more physically threatening scar, one that whose philosophy in life is that the strongest should take what they want. Chiwetel Ejiofor's voice for Scar is scary, threatening, strong, dominant, menacing. I am sure that some people won't like him, as the original Scar was also a brilliant villain, but this leads immediately to my big criticism of the original movie: if Scar was only half as effing intelligent as shown, why did he do such a miserable job in leading the Pride Lands? If he was so much smarter than Mufasa, why did the thriving Pride Lands turn into a wasteland, threatening the subsistence of Scar and his allies?
The answer in the original movie is clear: it's the absolutist identification of country and ruler. Mufasa was good, therefore the Pride Lands were doing well. When Scar takes over, they become a wasteland. When Simba takes over, in the next few shots, they start blooming again. Good people, good intentions, good outcomes. As simple as that.
The new movie changes that profoundly - and in a very smart way. The storytellers at Disney really know what they're doing! Instead of following the simple equation given above, they make it an explicit philosophical choice in leadership. This time around, the whole Circle of Life thing, is not just an Act One lesson, but is the major difference between Mufasa and Scar. Mufasa describes a great king as searching for what they can give. Scar is about might is right, and about the strongest taking whatever they want. This is why he overhunts and allows overhunting. This is why the Pride Lands become a wasteland. Now the decline of the Pride Lands make sense, and also why the return of Simba and his different style as a king would make a difference. The Circle of Life now became important for the whole movie, at the same time tying with the reinterpretation of Scar, and also explaining the difference in outcome.
You can probably tell, but I am quite amazed at this feat in storytelling. They took a beloved story and managed to improve it.
Unfortunately, the new Scar also means that the song Be Prepared doesn't really work as it used to, and thus the song also got shortened and very much changed in a movie that became much longer otherwise. I am not surprised, they even wanted to remove it, and now I understand why (even though back then I grumbled about it). They also removed the Leni Riefenstahl imaginary from the new version which was there in the original one, which I find regrettable, but obviously necessary given the rest of the movie.
A few minor notes.
The voice acting was a mixed bag. Beyonce was surprisingly bland (speaking, her singing was beautiful), and so was John Oliver (singing, his speaking was perfect). I just listened again to I can't wait to be king, and John Oliver just sounds so much less emotional than Rowan Atkinson. Pity.
Another beautiful scene was the scene were Rafiki receives the massage that Simba is still alive. In the original, this was a short transition of Simba ruffling up some flowers, and the wind takes them to Rafiki, he smells them, and realizes it is Simba. Now the scene is much more elaborate, funnier, and is reminiscent of Walt Disney's animal movies, which is a beautiful nod to the company founder. Simba's hair travels with the wind, birds, a Giraffe, an ant, and more, until it finally reaches the Shaman's home.
One of my best laughs was also due to another smart change: in Hakuna Matata, when they retell Pumbaa's story (with an incredibly cute little baby Pumbaa), Pumbaa laments that all his friends leaving him got him "unhearted, every time that he farted", and immediately complaining to Timon as to why he didn't stop him singing it - a play on the original's joke, where Timon interjects Pumbaa before he finishes the line with "Pumbaa! Not in front of the kids.", looking right at the camera and breaking the fourth wall.
Another great change was to give the Hyenas a bit more character - the interactions between the Hyena who wasn't much into personal space and the other who rather was, were really amusing. Unlike with the original version the differences in the looks of the Hyenas are harder to make out, and so giving them more personality is a great choice.
All in all, I really loved this version. Seeing it on the big screen pays off for the amazing imagery that really shines on a large canvas. I also love the original, and the original will always have a special place in my heart, but this is a wonderful tribute to a brilliant movie with an exceptional story.
Little One's first GIF
Little One made her first GIF!

Little Richard and James Brown
When Little Richard started becoming more famous, he already had signed up for a number of gigs but was then getting much better opportunities coming in. He was worried about his reputation, so he did not want to cancel the previous agreed gigs, but also did not want to miss the new opportunities. Instead he sent a different singer who was introduced as Little Richard, because most concert goers back then did not know how Little Richard exactly looked like.
The stand-in was James Brown, who at this point was unknown, and who later had a huge career, becoming an inaugural inductee to the Rock and Roll Hall of Fame - two years before Little Richard.
(I am learning a lot from and am enjoying Andrew Hickey's brilliant podcast "A History of Rock and Roll in 500 Songs")
Live from ICAIL
"Your work remindes me a lot of abduction, but I can't find you mention it in the paper..."
"Well, it's actually in the title."
Long John and Average Joe
You may know about Long John Silver. But who's the longest John? Here's the answer according to Wikidata: https://w.wiki/4dFL
What about your Average Joe? Here's the answer about the most average Joe, based on all the Joes in Wikidata: https://w.wiki/4dFR
Note, the average height of a Joe in Wikidata is 1,86cm or 6'1", which is quite a bit higher than the average height in the population. A data collection and coverage issue: it is much more likely to have the height for a basketball player than for an author in Wikidata.
Just two silly queries for Wikidata, which are nice ways to show off the data set and what one can do with the SPARQL query endpoint. Especially the latter one shows off a rather interesting and complex SPARQL query.
Machine Learning and Metrology
There are many, many papers in machine learning these days. And this paper, taking a step back, and thinking about how researchers measure their results and how good a specific type of benchmarks even can be - crowdsourced golden sets. It brings a convincing example based on word similarity, using terminology and concepts from metrology, to show how many results that have been reported are actually not supported by the golden set, because the resolution of the golden set is actually insufficient. So there might be no improvement at all, and that new architecture might just be noise.
I think this paper is really worth the time of people in the research field. Written by Chris Welty, Lora Aroyo, and Praveen Paritosh.
Mail problems
The last two days my mail account had trouble. If you could not send something to me, sorry! Now it should work again.
Since it is hard to guess who tried to eMail me in the last two days (I guess three persons right), I hope to reach some this way.
Major bill for US National Parks passed
Good news: the US Senate has passed a bipartisan large Public Lands Bill, which will provide billions right now and continued sustained funding for National Parks.
There a number of interesting and good parts about this, besides the obvious that National Parks are being funded better and predictably:
- the main reason why this passed and was made was that the Evangelical movement in the US is increasingly reckoning that Pro-Life also means Pro-Environment, and this really helped with making this bill a reality. This is major as it could set the US on a path to become a more sane nation regarding environmental policies. If this could also extend to global warming, that would be wonderful, but let's for now be thankful for any momentum in this direction.
- the sustained funding comes from oil and gas operations, which has a certain satisfying irony to it. I expect this part to backfire a bit somehow, but I don't know how yet.
- Even though this is a political move by Republicans in order to safe two of their Senators this fall, many Democrats supported it because the substance of the bill is good. Let's build on this momentum of bipartisanship.
- This has nothing to do with the pandemic, for once, but was in work for a long time. So all of the reasons above are true even without the pandemic.
Map of current Wikidata edits
It starts entirely black and then listens to Wikidata edits. Every time an item with a coordinate is edited, a blue dot in the corresponding place is made. So slowly, over time, you get a more and more complete map of Wikidata items.
If you open the developer console, you can get links and names of the items being displayed.
The whole page is less than a hundred lines of JavaScript and HTML, and it runs entirely in the browser. It uses the Wikimedia Stream API and the Wikidata API, and has no code dependencies. Might be fun to take a look if you're so inclined.
https://github.com/vrandezo/wikidata-edit-map/blob/main/index.html
Markus Krötzsch ISWC 2022 keynote
A brilliant keynote by Markus Krötzsch for this year's ISWC.
"The era of standard semantics has ended"
Yes, yes! 100%! That idea was in the air for a long time, but Markus really captured it in clear and precise language.
This talk is a great birthday present for Wikidata's ten year anniversary tomorrow. The Wikidata community had over the last years defined numerous little pockets of semantics for various use cases, shared SPARQL queries to capture some of those, identified constraints and reasoning patterns and shared those. And Wikidata connecting to thousands of external knowledge bases and authorities, each with their own constraints - only feasible since we can, in a much more fine grained way, use the semantics we need for a given context. The same's true for the billions of Schema.org triples out there, and how they can be brought together.
The middle part of the talk goes into theory, but make sure to listen to the passionate summary at 59:40, where he emphasises shared understanding, that knowledge is human, and the importance of community.
"Why have people ever started to share ontologies? What made people collaborate in this way?" Because knowledge is human. Because knowledge is often more valuable when it is shared. The data available on the Web of linked data, including Wikidata, Data Commons, Schema.org, can be used in many, many ways. It provides a common foundation of knowledge that enables many things. We are far away from using it to its potential.
A remark on triples, because I am still thinking too much about them: yes to Markus's comments: "The world is not triples, but we make it triples. We break down the world into triples, but we don't know how to rebuild it. What people model should follow the technical format is wrong, it should be the other way around" (rough quotes)
At 1:17:56, Markus calls back our discussions of the Wikidata data model in 2012. I remember how he was strongly advocating for more standard semantics (as he says), and I was pushing for more flexible knowledge representations. It's great to see the synthesis in this talk.
May 2019 talks
I am honored to give the following three invited talks in the next few weeks:
- Knowledge Graph Conference, Columbia University, New York, May 7, 2019
- Workshop on Knowledge Graph Technology and Applications, co-located with The Web Conference in San Francisco, May 13, 2019
- Wiki Workshop 2019, co-located with The Web Conference in San Francisco, May 14, 2019
The topics will all be on Wikidata, how the Wikipedias use it, and the Abstract Wikipedia idea.
Maybe the hottest conference ever
The Wikipedia Hacking Days are over. We have been visiting Siggraph, we had a tour through the MIT Media Lab, some of the people around were Brion Vibber (Wikimedia's CTO), Ward Cunningham (the guy who invented wikis), Dan Bricklin (the guy who invented spreadsheets), Aaron Swartz (a web wunderkind, he wrote the RSS specs at 14), Jimbo Wales (the guy who made Wikipedia happen), and many other people. We have been working at the One Laptop per Child offices, the office to easily the coolest project of the world.
During our stay at the Hacking Days, we had the chance to meet up with the local IBM Semantic Web dev staff and Elias Torres, who showed us the fabulous work they are doing right now on the Semantic Web technology stack (never before rapid application deployment was so rapid). And we also met up with the Simile project people, where we talked about connecting their stuff like Longwell and Timeline to the Semantic MediaWiki. We actually tried Timeline out on the ISWC2006 conference page, and the RDF worked out of the box, giving us a timeline of the workshop deadlines. Yay!
Today started Wikimania2006 at the Harvard Law School. was not only a keynote by Lawrence Lessig, as great as expected, but also our panel on the Semantic Wikipedia. We had an unexpected guest (who didn't get introduced, so most people didn't even realize he was there), Tim Berners-Lee, probably still jetlagged from a trip to Malaysia. The session was received well, and Brion said, that he sees us on the way of getting the extension into Wikipedia proper. Way cool. And we got bug reports from Sir Timbl again.
And there are still two days to go. If you're around and like to meet, drop a note.
Trust me — it all sounds like a dream to me.
Meat Loaf
"But it was long ago
And it was far away
Oh God, it seemed so very far
And if life is just a highway
Then the soul is just a car
And objects in the rear view mirror may appear closer than they are."
Bat out of Hell II: Back into Hell was the first album I really listened to, over and over again. Where I translated the songs to better understand them. Paradise by the Dashboard Light is just a fun song. He was in cult classic movies such as The Rocky Horror Picture Show, Fight Club, and Wayne's World.
Many of the words we should remember him for are by Jim Steinman, who died last year and wrote many of the lyrics that became famous as Meat Loaf's songs. Some of Meat Loaf's own words better not be remembered.
Rock in Peace, Meat Loaf! You have arrived at your destination.
Meeting opportunities
I read in an interview in Focus (German) with Andreas Weigend, he says that publishing his travel arrangements in his blog helped him meet interesting people and allow for unexpected opportunities. I actually noticed the same thing when I wrote about coming to Wikimania this summer. And those were great meetings!
So, now, here are the places I will be in the next weeks.
- Oct 18-Oct 20, Madrid: SEKT meeting
- Oct 22-Oct 26, Milton Keynes (passing through London): Talk at KMi Podium, Open University, on Semantic MediaWiki. There's a webcast! Subscribe, if you like.
- Oct 30-Nov 3, Montpellier: ODBASE, and especially OntoContent. Having a talk there on Unit testing for ontologies.
- Nov 5-Nov 13, Athens, Georgia: ISWC and OWLED
- Nov 15-Nov 17, Ipswich: SEKT meeting
- Nov 27-Dec 1, Vienna: Keynote at Semantics on Semantic Wikipedia
- Dec 13-17, Ljubljana: SEKT meeting
- Dec 30-Jan 10, Mumbai and Pune: the travel is private, but this doesn't mean at all we may not meet for work if you're around that part of the world
Just mail me if you'd like to meet.
Milk consumption in China
Quiet disappointed by The Guardian. Here's a (rather) interesting article on the history of milk consumption in China. But the whole article is trying to paint how catastrophic this development might be: the Chinese are trying to triple their intake in milk! That means more cows! That's bad because cows fart us into a hot house!
The argumentation is solid - more cows are indeed problematic. But blaming it on milk consumption in China? Let's take a look at a few numbers omitted from the article, or stuffed into the very last paragraph.
- On average, a European consumes six times as much milk as a Chinese. So, even if China achieves its goal and triples average milk consumption, they will drink only half as much as a European.
- Europe has double the number of dairy cows than China has.
- China is planning to increase their milk output by 300% but only increase resources for that by 30% according to the article. I have no idea how that works, but sounds like a great deal to me.
- And why are we even talking about dairy cows? The number of beef cows in the US or in Europe each outnumber the dairy cows by a fair amount (unsurprisingly - a cow produces quite a lot of milk over a longer time, whereas its meat production is limited to a single event)
- There are about 13 million dairy cows in China. The US have more than 94 million cattle, Brazil has more than 211 million, world wide it's more than 1.4 billion - but hey, it's the Chinese milk cows that are the problem.
Maybe the problem can be located more firmly in the consumption habits of people in the US and in Europe than the "unquenchable thirst of China".
The article is still interesting for a number of other reasons.
MinCardinality
More on the Unique Name Assumption (UNA), because Andrew answered on it, with further arguments. He quotes Paul: " The initial problem was cardinality and OWL Flight attempts to solve the problem with cardinality. Paul put it succinctly: "So what is the point of statements with the owl:minCardinality predicate? They can't ever be false, so they don't tell you anything! It's kind of like a belt and braces when your belt is unbreakable." "
Again I disagree, this time to Paul: the minimal cardinality axiom does make sense. For what, they ask - well, for saying that there is a minimal cardinality on this relation. Yeah, you are right: this is an axiom which hardly can lead to an inconsisten ontology. But so what? You nevertheless can cut down the number of possible models with it and get more information out of the ontology.
"I would agree - this was my main problem - how do you explain to Joe (and Andrew) that all his CDs are the same rather than different."
That's turning around the argument. If the reasoner would claim that all of Joes CDs are the same, he would be doing a grave mistake. But so would he if he would claim that all are different: the point is, he just doesn't know. Without having someone to state sameness or difference explicitly, well, you can't know.
"I did comment that the resolution, local unique names using AllDifferent, didn't actually seem to solve the problem well enough (without consideration for scalability for example)."
I am not sure why that should be. It seems that Andrew would be happy if there was a file-wide switch claiming "If I use different URIs here I mean different objects. This file makes the UNA." These files would easily be translated to standard OWL files, but there would be less clutter inside (actually, everything that would need to be done is adding an axiom of allDifferent with all the names of the file).
"I have a feeling that context is a better solution to this problem (that might just be my golden hammer though)."
I don't understand this one, maybe Andrew will elaborate a bit on this.
If you imagine an environment with axioms floating around, from repository to repository, being crawled, collected, filtered, mapped and combined, you must not make the Unique Name Assumption. If you remain in your own personal knowledge base, you can embrace UNA. And everything you need between is one more axiom.
Is it that bad?
Molly Holzschlag (1963-2023)
May her memory be a blessing.
She taught the Web to many, and she fought for the Web of many.
More FOAF
Wow, I never can't get enough FOAF :) Besides my Nodix-FOAF file the AIFB Portal now also offers a FOAF export for all the people at the AIFB (using URIs for the people besides the mailbox SHA1-Sum as identifiers. Hah! FOAFers won't like that, but TimBL told us to do it this way in Galway a few weeks ago).
If you point your smushers at the FOAFs, I wonder if you can also compile the SWRC-output into it, as they use the same URI? And can you also, by adding my own FOAF from Nodix, that I am the same person? Anyone dare's to try? :)
It's a pity Morten's FOAF explorer is down, I'd really like to try it out and browse. Isn't there something similar out there?
A tidbit more on that is also posted on the AIFB blog, but from a different point of view.
Mother philosophy
I should start to write some content on this blog soon, but actually I am still impressed with this technology I am learning here every day...
When the FOIS2004 was approaching, an Italian newspapers published this under the heading "Philosophy - finally useful for something" (or so, my Italian is based on a autodidactic half day course). I found this funny, and totally untrue.
Philosophy always had the bad luck, that every time a certain aspect of it provoced wider attention, this aspect became a discipline of its own. Physics, geometry and mathematics are the classical examples, later on theology, linguistics, anthropology, and then, in the 20th century, logic went this way too. It's like philosophy being the big incubator for new disciplines (you can see that still in the anglo-american tradition of almost all doctors actually being Ph.D.s, philosophical doctors.
Thus this misconception becomes understandable. Now, let's look around - what's the next discipline being born from philosophy? Will it be business ethics? Will it be the philosophy of science, being renamed as scientific managment?
My guess is: due to the fast growing area of the Semantic Web, it will be ontology. Today, the Wikipedia already made two articles on it, ontologies in philosophy and ontologies in computer science. This trend will gain momentum, and even though applied ontology will always feed from the fundamental work done from Socrates until today, it will become a full-fledged discipline of its own.
Moving to Germany
We are moving to Germany. It was a long and difficult decision process.
Is it the right decision? Who knows. These kinds of decisions are rarely right or wrong, but just are.
What about your job? I am thankful to the Wikimedia Foundation for allowing me to move and keep my position. The work on Abstract Wikipedia and Wikifunctions is not done yet, and I will continue to lead the realization of this project.
Don’t we like it in California? We love so many things about California and the US, and the US has been really good to us. Both my wife and I grew here in our careers, we both learned valuable skills, and met interesting people, some of whom became friends, and who I hope to continue to keep in touch. Particularly my time at Google was also financially a boon. And it also gave me the freedom to prepare for the Abstract Wikipedia project, and to get to know so many experts in their field and work together with them, to have the project criticized and go through several iterations until nothing seems obviously wrong with it. There is no place like the Bay Area in the world of Tech. It was comparably easy to have meetings with folks at Google, Facebook, Wikimedia, LinkedIn, Amazon, Stanford, Berkeley, or to have one of the many startups reach out for a quick chat. It is, in many ways, a magical place, and no other place we may move to will come even close to it with regards to its proximity to tech.
And then there’s the wonderful weather in the Bay Area and the breathtaking nature of California. It never gets really hot, it never gets really cold. The sun is shining almost every day, rain is scarce (too scarce), and we never have to drive on icy streets or shovel snow. If we want snow, we can just drive up to the Sierras. If we want heat, drive inland. We can see the largest trees in the world, walk through the literal forests of Endor, we can hike hills and mountains, and we can walk miles and miles along the sand beaches of the Pacific Ocean. California is beautiful.
Oh, and the food and the produce! Don’t get me started on Berkeley Bowl and its selection of fruits and vegetables. Of the figs in their far too short season, of the dry-farmed Early Girl tomatoes and their explosion of taste, of the juicy and rich cherries we picked every year to carry pounds and pounds home, and to eat as many while picking, the huge diversity of restaurants in various states from authentic to fusion, but most of them with delicious options and more dishes to try than time to do it.
And not just the fruits and vegetables are locally sourced: be it computers from Apple, phones from Google, the social media from Facebook or Twitter, the wonderful platform enabling the Wikimedia communities, be it cars from Tesla, be it movies from Pixar, the startups, the clouds, the AIs: so. many. things. are local. And every concert tour will pass by in the Bay Area. In the last year we saw so many concerts here, it was amazing. That’s a place the tours don’t skip.
Finally: in California, because so many people are not from here, we felt more like we belong just as well as everyone else, than anywhere else. Our family is quite a little mix, with passports from three continents. Our daughter has no simple roots. Being us is likely easier in the United States than in any of the European nation states with their millenia of identity. After a few years I felt like an American. In Germany, although it treated me well, after thirty years I still was an Ausländer.
As said, it is a unique place. I love it. It is a privilege and an amazing experience to have spent one decade of my life here.
Why are we moving? In short, guns and the inadequate social system.
In the last two years alone, we had four close-ish encounters with people wielding guns (not always around home). And we are not in a bad neighborhood, on the contrary. This is by all statistics one of the safest neighborhoods you will find in the East Bay or the City.
We are too worried to let the kid walk around by herself or even with friends. This is such a huge difference to how I grew up, and such a huge difference to when we spent the summer in Croatia, and she and other kids were off by themselves to explore and play. Here, there was not a single time she went to the playground or visited a friend by herself, or that one of her friends visited our house by themselves.
But even if she is not alone: going to the City with the kid? There are so many places there I want to avoid. Be it around the city hall, be it in the beautiful central library, be it on Market Street or even just on the subway or the subway stations: too often we have to be careful to avoid human excrement, too often we are confronted with people who are obviously in need of help, and too often I feel my fight or flight reflexes kicking in.
All of this is just the visible effect of a much larger problem, one that we in the Bay Area in particular, but as Americans in general should be ashamed of not improving: the huge disparity between rich and poor, the difficult conditions that many people live in. It is a shame that so many people who are in dire need of professional help live on the streets instead of receiving mental health care, that there are literal tent cities in the Bay Area, while the area is also the home of hundreds of thousands of millionaires and more than sixty billionaires - more than the UK, France, or Switzerland. It is a shame that so many people have to work two or more jobs in order to pay their rent and feed themselves and their children, while the median income exceeds $10,000 a month. It is a shame that this country, which calls itself the richest and most powerful and most advanced country in the world, will let its school children go hungry. Is “school lunch debt” a thing anywhere else in the world? Is “medical bankruptcy” a thing anywhere else in the world? Where else are college debts such a persistent social issue?
The combination of the easy availability of guns and the inadequate social system leads to a large amount of avoidable violence and to tens of thousands of seemingly avoidable deaths. And they lead to millions of people unnecessarily struggling and being denied a fair chance to fulfill their potential.
And the main problem, after a decade living here, is not where we are, but the trajectory of change we are seeing. I don’t have hope that there will be a major reduction in gun violence in the coming decade, on the contrary. I don’t have hope for any changes that will lead to the Bay Area and the US spreading the riches and gains it is amassing substantially more fairly amongst its population, on the contrary. Even the glacial development in self-driving cars seems breezy compared to the progress towards killing fewer of our children or sharing our profits a little bit more fairly.
After the 1996 Port Arthur shooting, Australia established restrictions on the use of automatic and semi-automatic weapons, created a gun buyback program that removed 650,000 guns from circulation, a national gun registry, and a waiting period for firearms sales. They chose so.
After the 2019 Christchurch shooting, New Zealand passed restrictions on semi-automatic weapons and a buyback program removed 50,000 guns. They chose so.
After the shootings earlier this year in Belgrade, Serbia introduced stricter laws and an amnesty for illegal weapons and ammunition if surrendered, leading to more than 75,000 guns being removed. They chose so.
I don’t want to list the events in the US. There are too many of them. And did any of them lead to changes? We choose not to.
We can easily afford to let basically everyone in the US live a decent life and help those that need it the most. We can easily afford to let no kid be hungry. We can easily afford to let every kid have a great education. We choose not to.
I don’t want my kid to grow up in a society where we make such choices.
I could go on and rant about the Republican party, about Trump possibly winning 2024, about our taxes supporting and financing wars in places where they shouldn’t, about xenophobia and racism, about reproductive rights, trans rights, and so much more. But unfortunately many of these topics are often not significantly better elsewhere either.
When are we moving? We plan to stay here until the school year is over, and aim to have moved before the next school year starts. So in the summer of ‘24.
Where are we moving? I am going back to my place of birth, Stuttgart. We considered a few options, and Stuttgart led overall due to the combination of proximity to family, school system compatibility for the kid, a time zone that works well for the Abstract Wikipedia team, language requirements, low legal hurdles of moving there, and the cost of living we expect. Like every place it also comes with challenges. Don’t get me started on the taste of tomatoes or peaches.
What other places did we consider? We considered many other places, and we traveled to quite a few of them to check them out. We loved each and every one of them. We particularly loved Auckland due to our family there and the weather, we loved the beautiful city of Barcelona for its food and culture, we loved Dublin, London, Zürich, Berlin, Vienna, Split. We started making a large spreadsheet with pros and contras in many categories, but in the end the decision was a gut decision. Thanks to everyone who talked with us and from whom we learned a lot about those places!
Being able to even consider moving to these places is a privilege. And we understand that and are thankful for having this privilege. Some of these places would have been harder to move for us due to immigration regulation, others are easy thanks to our background. But if you are thinking of moving, and are worried about certain aspects, feel free to reach out and discuss. I am happy to offer my experience and perspective.
Is there something you can help with? If you want to meet up with us while we are still in the US, it would be good to do so timely. We are expecting to sell the house quite a bit sooner, and then we won’t be able to host guests easily. I am also looking forward to reconnecting with people in Europe after the move. Finally, if you know someone who is interested in a well updated 3 bedroom house with a surprisingly large attic that can be used as a proper hobby space, and with a top walkability index in south Berkeley, point them our way.
Also, experiences and advice regarding moving from the US to Germany are welcome. Last time we moved the other way, and we didn’t have that much to move, and Google was generously organizing most of what needed to be done. This time it’s all on us. How to get a container and get it loaded? How to ship it to Germany? Where to store it while we are looking for a new home? How to move the cat? How to make sure all goes well with the new school? When to sell the house and where to live afterwards? How to find the right place in Germany? What are the legal hurdles to expect? How will taxes work? So many questions we will need to answer in the coming months. Wish us luck for 2024.
We also accept good wishes and encouraging words. And I am very much looking forward to seeing some of you again next year!
Mulan
I was surprised when Disney made the decision to sell Mulan on Disney+. So if you wanted to watch Mulan, you not only have to buy it, so far so good, but you have to join their subscription service first. The price for Mulan is $30 in the US, additionally to the monthly fee of streaming, $7. So the $30 don't buy you Mulan, but allow you to watch it if you keep up your subscription.
Additionally, on December 4 the movie becomes free for everyone with a Disney+ subscription.
I thought, that's a weird pricing model. Who'd pay that much money for streaming the movie a few weeks earlier? I know, it will be very long weeks due to the world being so 2020, but still. Money is tight for many people. Also, the movie had very mixed reviews and a number of controversies attached to it.
According to the linked report, Disney really knows what they're doing. 30% of subscribers bought the early streaming privilege! Disney made hundreds of millions in extra profit within three first few days (money they really will be thankful for right now given their business with the cruise ships and theme parks and movies this year).
The most interesting part is how this will affect the movie industry. Compare to Tenet - which was reviewed much better and which was the hope to revive the moribund US cinema industry, but made less than $30M - which also needs to be shared with the theaters and had much more distribution costs. Disney keeps a much larger share of the $30 for Mulan than Tenet makes for its production company.
The lesson from Mulan and Trolls 2, which also did much better than I would ever have predicted, for the production companies experimenting with novel pricing models, could be disastrous for theaters.
I think we're going to see even more experimentation with pricing models. If the new Bond movie and/or the new Marvel movie should be pulled from cinemas, this might also be the end of cinemas as we know them.
I don't know how the industry will change, but the swing is from AMC to Netflix, with the producers being caught in between. The pandemic massively accelerated this transition, as it did so many others.
My Erdös Number
After reading a post by Ora and one by Tim Finin, I tried to figure my own Erdös Number out. First, taking Ora's path, I came up with an Erdös of 7:
Paul Erdös - Stephan Hedeniemi - Robert Tarjan - David Karger - Lynn Stein - Jim Hendler - Steffen Staab - Denny Vrandečić
But then I looked more, and with Tim's path I could cut it down to 6:
Paul Erdös - Aviczir Fraenkl - Yaacov Yesha - Yelena Yesha - Tim Finin - Steffen Staab - Denny Vrandečić
The point that unnerved me most was that the data was actually there. Not only a subscription-only database for mathematical papers (why the heck is the metadata subscription only?), but there's DBLP, there's the list of Erdös 1 and 2 people on the Erdös Number project, there's Flink, and still, I couldn't mash up the data. This syntactic web sucks.
The only idea that brought me further - without spending even more time with that - was a Google search for "my erdös number" "semantic web", in the hope to find some collegues in my field that already have found and published their own Erdös number. And yep, this worked quite fine, and showed me two further, totally disjunctive paths to the one above:
Paul Erdös - Charles J. Coulborn - A. E. Brouwer - Peter van Emde Boas - Zhsisheng Huang - Peter Haase - Denny Vrandečić
and
Paul Erdös - Menachem Magidor - Karl Schlechta - Franz Baader - Ian Horrocks - Sean Bechhofer - Denny Vrandečić
So that's and Erdös of 6 on at least 3 totally different paths. Nice.
What surprises me - isn't this scenario obviously a great training project for the Semantic Web? Far easier than Flink, I suppose, and still interesting for a wider audience as well, like Mathematicians and Noble Laureates? (Oh, OK, not them, they get covered manually here).
Update
I wrote the post quite a time ago. A colleague of mine notified me in the meantime that I have a Erdös of only 4 by the following path:
Paul Erdös - E. Rodney Canfield - Guo-Quiang Zhang - Markus Krötzsch - Denny Vrandečić
Wow. It's the social web that gave the best answer.
2019 Update
Another update, after more than a dozen years: I was informed that I have now an Erdös number of 3 by the following path:
Paul Erdös - Anthony B. Evans - Pascal Hitzler - Denny Vrandečić
I would be very surprised if this post requires any further updates.
My horoscope for today
Here's my horoscope for today:
You may be overly concerned with how your current job prevents you from reaching your long-term goals. The Sun's entry into your 9th House of Big Ideas can work against your efficiency by distracting you with philosophical discussions about the purpose of life. These conversations may be fun, but they should be kept to a minimum until you finish your work.
How the heck did they know??
Need help with SQL
But I have no time to write it down... I will sketch my problem, and hopefully get an answer (I've started this blog in the morning, and now I need to close it, cause I have to leave).
Imagine I have following table (a triple store):
| Subject | Predicate | Object |
|---|---|---|
| Adam | yahoo im | adam@net |
| Adam | skye | adam |
| Berta | skype | berta |
How do I make a query that returns me the following table:
| Subject | o1 | o2 |
|---|---|---|
| Adam | adam@net | adam |
| Berta | - | berta |
The problems are the default value in the middle lower cell. The rest works (as maybe seen in the Semantic Mediawiki code, file includes/SMW_InlineQueries.php -- note that the CVS is not up to date for now, because SourceForge's CVS is down for days!)
It should work in general, with as many columns as I like on the answer table (based on the predicates in the first one).
Oh, and if you solved this -- or have an idea -- it would be nice if it worked with MySQL 4.0, i.e. without Subqueries.
Any ideas?
New OWL tools
The KAON2 OWL Tools get more diverse and interesting. Besides the simple axiom and entity counter and dumper, the not so simple dlpconverter, and the syntactic transformer from XML/RDF to OWL/XML and back, you now also have a filter (want to extract only the subClassOf-Relations out of your ontology? Take filter), diff and merge (for some basic syntactic work with ontologies), satisfiable (which checks if the ontology can have a satisfying model), deo (turning SHOIN-ontologies in SHIN-ontologies by weakening, should be sound, but naturally not complete) and ded (removes some domain-related axioms, but it seems this one is still buggy).
I certainly hope this toolbox will still grow a bit. If you have any suggestions or ideas, feel free to mail me or comment here.
New home in Emeryville
Our new (temporary home) is the City of Emeryville. Emeryville has a population of almost 13,000 people. The apartment complex we live in has about 400 units, and I estimate that they have about 2 people on average in each. Assuming that about 90% of the apartments are occupied, this single apartment complex would constitute between 5 and 10% of the population of the whole city.
New people at Yahoo and Google
Vint Cerf starts working at Google, Dave Becket moves to Yahoo. Both like the Semantic Web (Vint said so in a German interview with c't, and I probably don't have to remind you about Daves accomplishments).
I'm sure, Yahoo got Dave because of his knowledge about the Semantic Web. And I wonder if Google got Vint out of the same reason? Somehow, I doubt it.
New tagline is my New Year's resolution
I just changed the tagline of this blog. The old one was rather, hmm, boring:
"Discovering the Semantic Web, Ontology Engineering and related technologies, and trying to understand these amazing ideas - and maybe sharing an idea or two... "
The new one is at the same time my new year's resolution for 2006.
"Kicking the Semantic Web's butt to reality"
'nuff said, got work to do.
New versions: owlrdf2owlxml, dlpconvert
New versions of owlrdf2owlxml and dlpconvert are out.
owlrdf2owlxml got renamed, as it was formerly known as rdf2owlxml. But as a colleague pointed out, this name can easily be misunderstood, meaning to transform arbitrarily RDF to OWL. It doesn't do that, it only transforms OWL to OWL, from RDF/XML-serialisation to XML Presentation Syntax. And it seems to work quite stable, it can even transform the famous wine ontology. Version 0.4 out now.
dlpconvert lost a lot of its bugs. And as most of you were feeding RDF/XML to it, well, now you can do it officially (listen to the users), too. It reads both syntaxes, and creates a Prolog program out of your ontology. Version 0.7 is out.
They are both based on KAON2, the Karlsruhe Ontology Infrastructure module, written by Boris Motik. My little tools are just wrapped around KAON2 and using its functionality. To be honest, I'm thinking of writing quite a number of little tools like this, who offer different functionality, thus providing you with a nice toolkit to handle ontologies efficiently. I don't lack ideas right now, it's just I' m not sure that there's interest in this.
Well, maybe I should just start and we'll see...
By the way, both tools are not only available as web services, but you may also download them as command line tools from their respective websites and play around it on your PC. That's a bit more comfortable than using a browser as your operating system.
No April Fool's day
This year, I am going to skip April Fool's day.
I am not being glib, but quite literal.
We are taking flight NZ7 starting on the evening of March 31 in San Francisco, flying over the Pacific Ocean, and will arrive on April 2 in the early morning in Auckland, New Zealand.
Even if one actually follows the flight route and overlays it over the timezone map, it looks very much like we are not going to spend more than a few dozen minutes, or at most a few hours, in April 1, if all goes according to plan.
Looking forward to it!
Here's the flight data of a previous NZ7 flight, from Sunday: https://flightaware.com/live/flight/ANZ7/history/20230327/0410Z/KSFO/NZAA/tracklog
Here are the timezones (but it's Northern winter time). Would be nice to overlay the two maps: 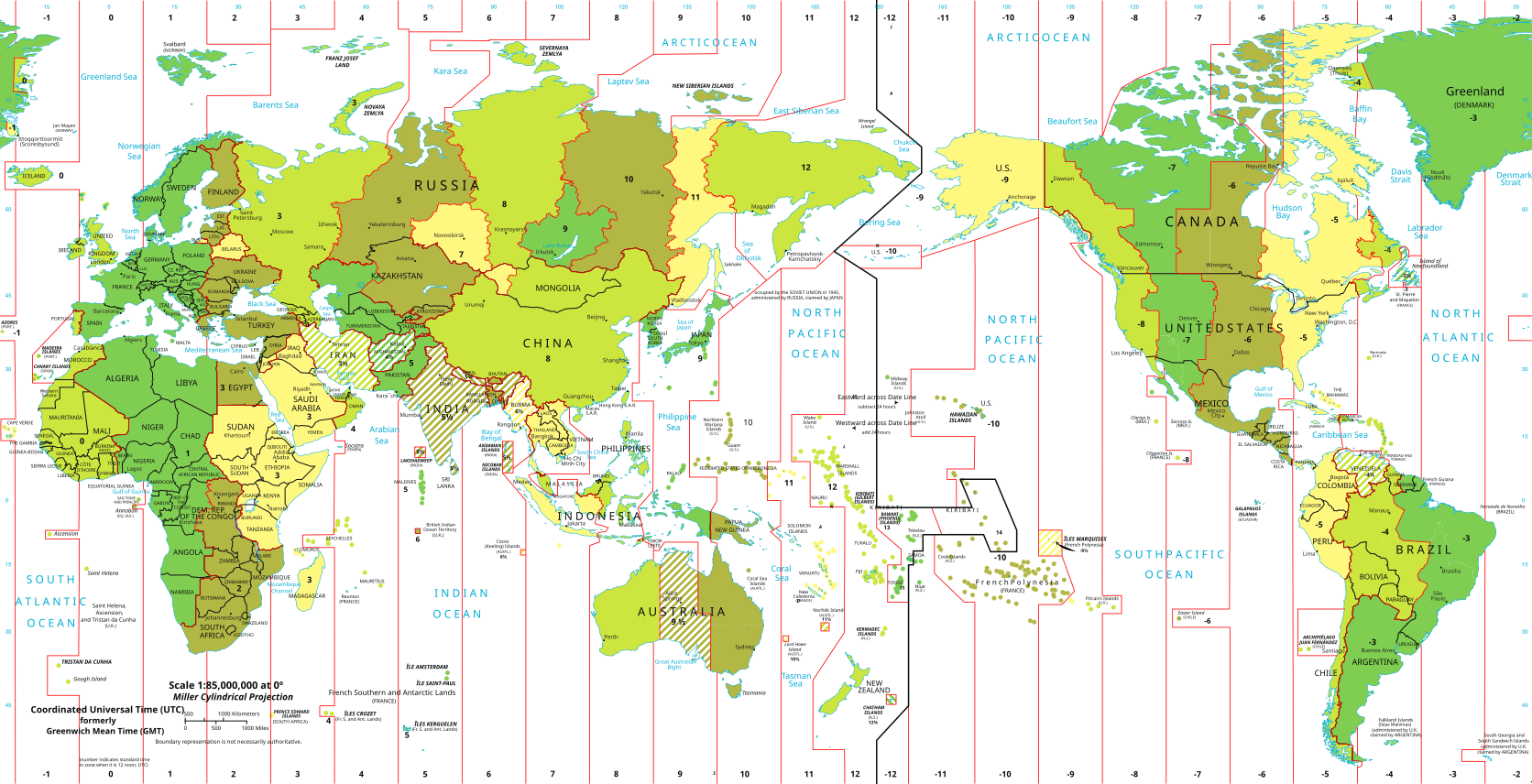
Where's Wikifunctions when it's needed?
The question seems to be twofold: how often do we cross the dateline, and how close are we to local time midnight while crossing the dateline. For a perfect date miss one would need to cross the dateline exactly once, at a 24 hour difference, as close as possible to local midnight.
Normbrunnenflasche
It's a pity there's no English Wikipedia article about this marvellous thing that exemplifies Germany so beautifully and quintessentially: the Normbrunnenflasche.
I was wondering the other day why in Germany sparkling water is being sold in 0.7l bottles and not in 1l or 2l or whatever, like in the US (when it's sold here at all, but that's another story).
Germany had a lot of small local producers and companies. To counter the advantages of the Coca Cola Company pressing in the German market, in 1969 a conference of representatives of the local companies decided to introduce a bottle design they all would use. This decision followed a half year competition and discussion on what this bottle should look like.
Every company would use the same bottle for sparkling water and other carbonated drinks, and so no matter which one you bought, the empty bottle would afterwards be routed to the closest participating company, not back home, therefore reducing transport costs and increasing competitiveness against Coca Cola.
The bottle is full of smart features. The 0.7l were chosen to ensure that the drink remained carbonated until the last sip, because larger bottles would last longer and thus gradually loose carbonization.
The form and the little pearls outside were chosen for improved grip, but also to symbolize the sparkles of the carbonization.
The metal screw cap was the real innovation there, useful for drinks that could increase pressure due to the carbonization.
And finally two slightly thicker bands along the lower half of the bottle that would, while being rerouted for another usage, slowly get more opaque due to mechanical pressure, thus indicating how well used the individual bottle was, so they could be taken out of service in time before breaking at the customer.
The bottles were reused an average of fifty times, their boxes an average of hundred times. More than five billion of them have been brought into circulation in the fifty years since their adoption, for an estimated quarter of a trillion fillings.
Northern Arizona
Last week we had a wonderful trip through Northern Arizona.
Itinerary: starting in Phoenix going Northeast through Tonto National Forest towards Winslow. In Tonto, we met our first surprise, which would become a recurring pattern: whereas we expected Arizona in April to be hot, and we were prepared for hot, it had some really cold spells, and we were not prepared for cold. We started in the Sonoran Desert, surrounded by cacti and sun, but one and a half hours later in Tonto, we were driving through a veritable snow storm, but fortunately, just as it was getting worrisome, we crossed the ridge and started descending towards Winslow to the North.
The Colorado Plateau on the other side of the ridge was then pleasant and warm, and the next days we traveled through and visited the Petrified Forest, Monument Valley, Horseshoe Bend, Antelope Canyon, and more.
After that we headed for the Grand Canyon, but temperatures dropped so low, and we didn't have the right outfit for that, we stayed less than a day there, most of it huddled in the hotel room. Still, the views we got were just amazing, and throwing snowballs was an unexpected fun exercise.
Our last stop took us to Sedona, where we were again welcomed with amazing views. The rocks and formations all had in common that they dramatically changed with the movement of the sun, or with us moving around, and the views were always fresh.
Numbers: Our trip took us about 950 miles / 1500 kilometeres of driving, and I was happy that it was a good Jeep for this trip. The difference in altitude went from 1000 feet / 330 meters in Phoenix up to 8000 feet / 2400 meters driving through Coconino. Temperatures ranged from 86° F / 30° C to 20° F / -7° C.
What I learned again is how big this country is. And how beautiful.
Surprises: One thing that surprised me was how hidden the Canyons can be. Well, you can't hide Grand Canyon, but it is easy to pass by Antelope Canyon and not realizing it is there. Because it is just a cut in the plateau.
I also was surprised about how flat and wide the land is. I have mostly lived in areas where you had mountains or at least hills nearby, but the Colorado Plateau has large wide swaths of flat land. "Once the land was as plane as a pancake".
I mentioned the biggest surprise already, which was how cold it got.
Towns: it was astonishing to see the difference between, on the one side, a town such as Page or Sedona and on the other side Winslow. All three have a similar population, but Page and Sedona felt vigorous, lively, clean, whereas Winslow felt as if it was on the decline, deserted, struggling.
The hotel we stayed in in Winslow, La Posada, was a beautiful, weird, unique jewel that I hesitate to flat-out recommend, it is too unusual for that, but that I still enjoyed experiencing. It is clearly very different from any other hotel I ever stayed in, full of history, and embracing themes of both suicide and hope, respectfully trying to grow with the native population, and aiming to revive the city's old town, and it is difficult to really capture the vibe it was sending out.
For pictures, I am afraid I am pointing to my Facebook posts, which should be visible without login:
- Scottsdale
- Palo Verde tree
- Desert Botanical Garden, Phoenix
- Desert to snowstorm
- Winslow
- La Posada hotel
- Petrified forest
- Monument valley
- Horseshoe bend
- Antelope canyon
- Grand canyon
- Sedona
OK
I often hear "don't go for the mediocre, go for the best!", or "I am the best, * the rest" and similar slogans. But striving for the best, for perfection, for excellence, is tiring in the best of times, never mind, forgive the cliché, in these unprecedented times.
Our brains are not wired for the best, we are not optimisers. We are naturally 'satisficers', we have evolved for the good-enough. For this insight, Herbert Simon received a Nobel prize, the only Turing Award winner to ever get one.
And yes, there are exceptional situations where only the best is good enough. But if good enough was good enough for a Turing-Award winning Nobel laureate, it is probably for most of us too.
It is OK to strive for OK. OK can sometimes be hard enough, to be honest.
May is mental health awareness month. Be kind to each other. And, I know it is even harder, be kind to yourself.
Here is OK in different ways. I hope it is OK.
Oké ఓకే ਓਕੇ オーケー ओके 👌 ওকে או. קיי. Окей أوكي Օքեյ O.K.
OWL 2.0
I posted this to the public OWL dev mailing list as a response to a question posed by Jim Hendler quite some while ago. I publish it here for easier reference.
Quite some while ago the question of OWL 2.0 was rised here, and I wrote already two long replies with a wishlist - but both were never sent and got lost in digital nirvana, one due to a hardware, the second due to a software failure. Well, let's hope this one passes finally through. That's why this answer is so late.
Sorry for the lengthy post. But I tried to structure it a bit and make it readable, so I hope you find some interesting stuff here. So, here is my wishlist.
- I would like yet another OWL language, call it OWL RDF or OWL Superlite, or whatever. This is like the subset of OWL Lite and RDFS. For this the difference between of owl:Class and rdf:Class needs to be somehow standardly solved. Why is this good? It makes moving from RDF to OWL easier, as it forces you to keep Individuals, Classes and Relations in different worlds, and forgets about some of the more sophisticated constructs of RDF(S) like lists, bags and such. This is a real beginners language, really easy to learn and implement.
- Defined Semantics for OWL FUll. It is unclear -- at least to me -- what some combinations of RDF(S)-Constructs and OWL DL-constructs are meant to mean.
- Add easy reification to OWL. I know, I know, making statements about statements is meant to be the root of all evil, but I find it pretty useful. If you like, just add another group of elements to OWL, statements, that are mutually disjoint from classes, instances and relations in OWL DL, but there's a sublanguage that enables us to speak about statements. Or else OWL will suck a lot in comparison to RDF(S) and RDF(S) + Rules will win, because you can't do a lot of the stuff you need to do, like saying what the source of a certain statement is, how reliable this source is, etc. Trust anyone? This is also needed to extend ontologies toward probabilistic, fuzzy or confidence-carrying models.
- I would love to be able to define syntactic sugar, like partitionOf (I think, this is from Asun's Book on Ontology Engineering). ((A, B, C) partitionOf D) means that every D is either an A or a B or a C, that every A, B or C is a D, and that A, B and C are mutually disjunct. So you can say this already, but it needs a lot of footwork. It would be nice to be able to define such shotcuts that lever upon the semantics of existing constructors.
- That said, another form of syntactic sugar - because again you can use existing OWL constructs to reach the same goal, but it is very strenuous to do so - would be to define UNA locally. Like either to say "all individuals in this ontology are mutually different" or "all individuals with this namespace are mutually different". I think, due to XML constraints the first one would be the weapon of choice.
- I would like to be able to have more ontologies in the same file. So you can use ontologies to group a number of axioms, and you also could use the name of this group to refer to it. Oh well, using the name of an ontology as an individual, what does this mean? Does it imply any further semantics? I would like to see this clarified. Is this like named graphs?
- The DOM has quite nicely partitioned itself in levels and modules. Why not OWL itself? So you could have like a level 2 ontology of mereological questions, and such stuff, all with well defined semantics, for the generic questions. I am not sure there are too many generic questions, but taxonomy is (already covered), mereology would be, and spatiotemporal and dynamic issues would be as well. Mind you, not everyone must use them, but many will need them. It would be fine to find stan dard answers to such generic questions.
- Procedural attachments would be a nice thing. Like have a a standardized possibilities to add pieces of code and have them executed by an appropriate execution environment on certain events or requests by the reasoner. Yes, I am totally aware of the implications on reasoning and decidability, but hey, you asked what people need, and did not ask for theoretical issues. Those you understand better.
- There are some ideas of others (which doesn't mean that the rest is necessarily original mine) I would like to see integrated, like a well-defined epistemic operator or streamlining the concrete domains to be more consistent with abstract domains, or to define domain and range _constraints_ on relations, and much more. Much of this stuff could be added optional in the sense of point 7.
- And not to forget that we have to integrate with rules later, and to finally have an OWL DL query language. One goal is to make it clear what OWL offers over simply adding rules atop of RDF and ignoring the ontology layer completely.
So, you see, this is quite a list, and it sure is not complete. Even if only two or three points were finally picked up I would be very happy :)
OWL luna, nicer latex, OWL/XML to Abstract Syntax, and more
After a long hiatus, due to some technical problems, finally I could create a new version of the owl tools. So, version 0.27 of the owl tools is now released. It works with the new version of KAON2, and includes six months of bug fixing, but also a number of new features that have introduced a whole new world of new, exciting bugs as well.
The owl latex support was improved greatly. Translation of an owl ontology is done now more careful, and the user can specify much more of the result than before.
A new tool is owl luna - luna like local unique name assumption. It adds an axiom to your ontology that states that all individuals are different from each other. Due to most ontology editors not allowing to do this automatically, here you find a nice maintenance tool to make your ontology much less ambiguous.
The translations of OWL/RDF to OWL/XML and back have been joined in one new tool, called owl syntax, that allows you to translate owl ontologies also to OWL Abstract Syntax, a much nicer syntax for owl ontologies.
owl dlpconvert has been extended as it now also serialzes it results as RuleML if you like. So you can just pipe your ontologies to RuleML.
So, the tools have both become sharper and more numerous, making your toolbelt to work with owl in daily life more usable. Get the new owl tools now. And if you peek into the source code, the code has underwent a major clean up, and you will also see the new features I am working on, that have to do with ontology evaluation and more.
Have fun with the tools! And send me your comments, wishes, critiques!
On the competence of conspiracists
“Look, I’ll be honest, if living in the US for the last five years has taught me anything is that any government assemblage large enough to try to control a big chunk of the human population would in no way be consistently competent enough to actually cover it up. Like, we would have found out in three months and it wouldn’t even have been because of some investigative reporter, it would have been because one of the lizards forgot to put on their human suit on day and accidentally went out to shop for a pint of milk and like, got caught in a tik-tok video.” -- Os Keyes, WikidataCon, Keynote "Questioning Wikidata"
One world. One web.
I am in Beijing at the opening of the WWW2008 conference. Like all WWWs I was before, it is amazing. The opening ceremony was preceded by a beautiful dance, combining tons of symbols. First a woman in a traditional Chinese dress, then eight dancers in astronaut uniforms, a big red flag with "Welcome to Beijing" on it (but not on the other side, when he came back), and then all of them together... beautiful.
Boris Motik's paper is a best paper candidate! Yay! Congratulations.
I rather listen to the keynote now :)
Blogging from my XO One.
Oscar winning families
Yesterday, when Jamie Lee Curtis won her Academy Award, I learned that both her parents were also nominated for Academy Awards. Which lead to the question: who else?
I asked Wikidata, which lists four others:
- Laura Dern
- Liza Minnelli
- Nora Ephron
- Sean Astin
Only one of them belongs to the even more exclusive club of people who won an Academy Award, and where both parents also did: Liza Minnelli, daughter of Vincente Minelli and Judy Garland.
Also interesting: List of Academy Award-winning families
Our four freedoms for our technology
(This is a draft. Comments are welcome. This is not meant as an attack on any person or company individually, but at certain practises that are becoming increasingly prevalent)
We are not allowed to use the devices we paid for in the ways we want. We are not allowed to use our own data in the way we want. We are only allowed to use them in the way the companies who created the devices and services allow us.
Sometimes these companies are nice and give us a lot of freedom in how to use the devices and data. But often they don’t. They close them down for all kinds of reasons. They may say it is for your protection and safety. They might admit it is for profit. They may say it is for legal reasons. But in the end, you are buying a device, or you are creating some data, and you are not allowed to use that device and that data in the way you want to, you are not allowed to be creative.
The companies don’t want you to think of the devices that you bought and the data that you created as your devices and your data. They want you to think of them as black boxes that offer you services they create for you. They don’t want you to think of a Ring doorbell as a camera, a microphone, a speaker, and a button, but they want you to think of it as providing safety. They don’t want you to think of the garage door opener as a motor and a bluetooth module and a wifi module, but as a garage door opening service, and the company wants to control how you are allowed to use that service. Companies like Chamberlain and SkyLink and Genie don’t allow you to write a tool to check on your garage door, and to close or open it, but they make deals with Google and Amazon and Apple in order to integrate these services into their digital assistants, so that you can use it in the way these companies have agreed on together, through the few paths these digital assistants are available. The digital assistant that you buy is not a microphone and a speaker and maybe a camera and maybe a screen that you buy and use as you want, but you buy a service that happens to have some technical ingredients. But you cannot use that screen to display what you want. Whether you can watch your Amazon Prime show on the screen of a Google Nest Hub depends on whether Amazon and Google have an agreement with each other, not on whether you have paid for access to Amazon Prime and you have paid for a Google Nest Hub. You cannot use that camera to take a picture. You cannot use that speaker to make it say something you want it to say. You cannot use the rich plethora of services on the Web, and you cannot use the many interesting services these digital assistants rely on, in novel and creative combinations.
These companies don’t want you to think of the data that you have created and that they have about you as your data. They don’t want you to think about this data at all. They just want you to use their services in the way they want you to use their services. On the devices they approve. They don’t want you to create other surfaces that are suited to the way you use your data. They don’t want you to decide on what you want to see in your feed. They don’t want you to be able to take a list of your friends and do something with it. They will say it is to protect privacy. They will say that it is for safety. That is why you cannot use the data you and your friends have created. They want to exactly control what you can and cannot do with the data you and your friends have created. They want to control how many ads you must see in order to be allowed to see your friends’ posts. They don't want anyone else to have the ability to provide you creative new interfaces to your feed. They don’t want you yourself the ability to look at your feed and do whatever you want with it.
Those are devices you paid for.
These are data you and your friends have created.
And more and more we are losing our freedom of using our devices and our data as we like.
It would be impossible to invent email today. It would be impossible to invent the telephone today. Both are protocols that allow everyone to communicate with anyone no matter what their email provider or their phone is. Try reading your friend’s Facebook feed on Instagram, or send a direct message from your Twitter account to someone on WhatsApp, or call your Skype contact on Facetime.
It would be impossible to launch the Web today - many companies don’t want you browsing the Web. They want you to be inside of your Facebook feed and consume your content there. They want you to be on your Twitter feed. They don’t want you to go to the Website of the New York Times and read an article there, they don’t want you to visit the Website of your friend and read their blog there. They want you to stay on their apps. Per default, they open Websites inside their app, and not in your browser, so you are always within their app. They don’t want you to experience the Web. The Web is dwindling and all the good things on it are being recut and rebundled within the apps and services of tech companies.
Increasingly, we are seeing more and more walls in the world. Already, it is becoming impossible to pay and watch certain movies and shows without buying into a full subscription in a service. We will likely see the day where you will need a specific device to watch a specific movie. Where the only way to watch a Disney+ exclusive movie is on a Disney+ tablet. You don’t think so? Think about how easy it is to get your Kindle books onto another Ebook reader. How do you enable a skill or capability available in Alexa on your Nest smart speaker? How can you search through the books that you bought and are in your digital library, besides by using a service provided by the company that allows you to search your digital library? When you buy a movie today on YouTube or on iMovies, what do you own? What are you left with when the companies behind these services close that service, or go out of business altogether?
Devices and content we pay for, data we and our friends create, should be ours to use in empowering and creative ways. Services and content should not be locked in with a certain device or subscription service. The bundling of services, content, devices, and locking up user data creates monopolies that stifle innovation and creativity. I am not asking to give away services or content or devices for free, I am asking to be allowed to pay for them and then use them as I see fit.
What can we do?
As far as I can tell, the solution, unfortunately, seems to be to ask for regulation. The market won’t solve it. The market doesn’t solve monopolies and oligopolies.
But don’t ask to regulate the tech giants individually. We don’t need a law that regulates Google and a law that regulates Apple and a law that regulates Amazon and a law to regulate Microsoft. We need laws to regulate devices, laws to regulate services, laws to regulate content, laws that regulate AI.
Don’t ask for Facebook to be broken up because you think Mark Zuckerberg is too rich and powerful. Breaking up Facebook, creating Baby Books, will ultimately make him and other Facebook shareholders richer than ever before. But breaking up Facebook will require the successor companies to work together on a protocol to collaborate. To share data. To be able to move from one service to another.
We need laws that require that every device we buy can be made fully ours. Yes, sure, Apple must still be allowed to provide us with the wonderful smooth User Experience we value Apple for. But we must also be able to access and share the data from the sensors in our devices that we have bought from them. We must be able to install and run software we have written or bought on the devices we paid for.
We need laws that require that our data is ours. We should be able to download our data from a service provider and use it as we like. We must be allowed to share with a friend the parts of our data we want to share with that friend. In real time, not in a dump download hours later. We must be able to take our social graph from one social service and move to a new service. The data must be sufficiently complete to allow for such a transfer, and not crippled.
We need laws that require that published content can be bought and used by us as we like. We should be able to store content on our hard disks. To lend it to a friend. To sell it. Anything I can legally do with a book I bought I must be able to legally do with a movie or piece of music I bought online. Just as with a book you are not allowed to give away the copies if the work you bought still enjoys copyright.
We need laws that require that services and capabilities are unbundled and made available to everyone. Particularly as technological progress with regards to AI, Quantum computing, and providing large amounts of compute becomes increasingly an exclusive domain for trillion dollar companies, we must enable other organizations and people to access these capabilities, or run the risk that sooner or later all and any innovation will be happening only in these few trillion dollar companies. Just because a company is really good at providing a specific service cheaply, it should not be allowed to unfairly gain advantage in all related areas and products and stifle competition and innovation. This company should still be allowed to use these capabilities in their products and services, but so should anyone else, fairly prized and accessible by everyone.
We want to unleash creativity and innovation. In our lifetimes we have seen the creation of technologies that would have been considered miracles and impossible just decades ago. These must belong to everybody. These must be available to everyone. There cannot be equity if all of these marvellous technologies can be only wielded by a few companies on the West coast of the United States. We must make them available to all the people of the world: the people of the Indian subcontinent, the people of Subsaharan Africa,the people of Latin America, and everyone else. They all should own the devices they paid for, the data they created, the content they paid for. They all should have access to the same digital services and capabilities that are available to the engineers at Amazon or Google or Microsoft. The universities and research centers of the world should be able to access the same devices and services and extend them with their novel and creative ideas. The scrappy engineers in Eastern Europe and India and Nigeria and Central Asia should be able to call the AI models trained by Google and Microsoft and use them in novel ways to run their devices and chip-powered cars and agricultural machines. We want a world of freedom, tinkering, where creativity and innovation are unleashed, and where everyone can contribute their ideas, their creativity, and where everyone can build their fortune.
Papaphobia
In a little knowledge engineering exercise, I was trying to add the causes of a phobia to the respective Wikidata items. There are currently about 160 phobias in Wikidata, and only a few listed in a structured way what they are afraid of. So I was going through them, trying to capture it in s a structured way. Here's a list of the current state:
Now, one of those phobias was the Papaphobia - the fear of the pope. Now, is that really a thing? I don't know. CDC does not seem to have an entry on it. On the Web, in the meantime, some pages have obviously taken to mining lists of phobias and creating advertising pages that "help" you with Papaphobia - such as this one:
This page is likely entirely auto-generated. I doubt it that they have "clients for papaphobia in 70+ countries", whom they helped "in complete discretion" within a single day! "People with severe fears and phobias like papaphobia (which is in fact the formal diagnostic term for papaphobia) are held prisoners by their phobias."
This site offers more, uhm, useful information.
"Group psychotherapy can also help where individuals share their experience and, in the process, understand and recover from their phobia." Really? There are enough cases that we can even set up a group therapy?
Now, maybe I am entirely off here - maybe, papaphobia is really a thing. With search in Scholar I couldn't find any medical sources (the term is mentioned in a number of sociological and historical works, to express general sentiments in a population or government against the authority of the pope, but I could not find any mentions of it in actual medical literature).
Now could those pages up there be benign cases of jokes? Or are they trying to scam people with promises to heal their actual fears, and they just didn't curate the list of fears sufficiently, because, really, you wouldn't find this page unless you actually search for this term?
And now what? Now what if we know these pages are made by scammers? Do we report them to the police? Do we send a tip to journalists? Or should we just do nothing, allowing them to scam people with actual fears? Well, by publishing this text, maybe I'll get a few people warned, but it won't reach the people it has to reach at the right time, unfortunately.
Also, was it always so hard to figure out what is real and what is not? Does papaphobia exist? Such a simple question. How should we deal with it on Wikidata? How many cases are there, if it exists? Did it get worse for people with papaphobia now that we have two people living who have been made pope?
My assumption now is that someone was basically working on a corpus, looking for words ending in -phobia, in order to generate a list of phobias. And then the term papaphobia from sociological and historical literature popped up, and it landed in some list, and was repeated in other places, etc., also because it is kind of a funny idea, and so a mixture of bad research and joking bubbled through, and rolled around on the Web for so long that it looks like it is actually a thing, to the point that there are now organizations who will gladly take your money (CTRN is not the only one) to treat you for papaphobia.
The world is weird.
Partial copyright for an AI generated work
Interesting development in US cases around copyright and AI: author Elisa Shupe asked for copyright registration on a book that was created with the help of generative AI. Shupe stated that not giving her registration would be disabilities discrimination, since she would not have been able to create her work otherwise. On appeal, her work was partially granted protection for the “selection, coordination, and arrangement of text generated by artificial intelligence”, without referral to the disability argument.