Semantic search
From vexing uncertainty to intellectual humility
A philosopher with schizophrenia wrote a harrowing account of how he experiences schizophrenia. And I wonder if some of the lessons are true for everyone, and what that means for society.
- "It’s definite belief, not certainty, that allows me to get along. It’s not that certainty, or something like it, never matters. If you are fixing dinner for me I’ll try to be clear about the eggplant allergy [...] But most of the time, just having a definite, if unconfirmed and possibly false, belief about the situation is fine. It allows one to get along.
- "I think of this attitude as a kind of “intellectual humility” because although I do care about truth—and as a consequence of caring about truth, I do form beliefs about what is true—I no longer agonize about whether my judgments are wrong. For me, living relatively free from debilitating anxiety is incompatible with relentless pursuit of truth. Instead, I need clear beliefs and a willingness to change them when circumstances and evidence demand, without worrying about, or getting upset about, being wrong. This attitude has made life better and has made the “near-collapses” much rarer."
(first published on Facebook March 13, 2024)
Feeding the cat
Every morning, I lovingly and carefully scoop out every single morsel of meat from the tin of wet food for our cat. And then he eats a tenth of it.
Dolly Parton's What's up?
Dolly Parton is an amazing person. On "Rockstar", her latest album, she covered a great number of songs, with amazing collaborators, often the original interpreters or writers. In her cover of "What's up?", a song I really love, with Linda Perry, she changed a few lines of the lyrics, as one often does when covering, to make a song their own.
Instead of "Twenty-five years and my life is still...", she's singing "All of these years and my life is still..." - and makes total sense, because unlike Linda Perry she wasn't 25 when she wrote it, she was 77 when she recorded it.
Instead of "I take a deep breath and I get real high", Dolly takes "a deep breath and wonders why", and it makes sense, because, hey, it's Dolly Parton.
But here's the line that hurts, right there when the song reaches its high point:
- "And I pray,
- Oh my God do I pray!
- I pray every. single. day.
- for a revolution!"
She changed one letter in the last word:
- "for a resolution"
And it just breaks my heart. Because it feels so weak. Because it seems to betray the song. Because it seems to betray everything. And also because I might agree with her, and that feels like betrayal too.
Views on the US economy 2024
By most metrics, the American economy is doing well. But the perception of the American economy is much weaker than its actual strength. This seems to finally slowly break up a bit, and people are realizing that things are actually not that bad.
Here's an article that tries to explain it: because of high interest rates, credit is expensive, including credit card debt, and if someone is buying a home now.
But if you go beyond the anecdotes as this essay does, and look at the actual data, you will find something else: it is a very partisan thing.
For Democrats we find that it depends. Basically, the more you fit to the dominant group - the richer you are, the older, the better educated, the "whiter", the "maler" - the better your view of the economy.
For Republicans we don't find any such differentiation. Everyone is negative about it, across the board. Their perception of the economic situation are crassly different from the perception of their Democratic peers.
Libertarian cities
I usually try to contain my "Schadenfreude", but reading this article made it really difficult to do so. It starts with the story of Rio Verde Foothills and its lack of water supply after it was intentionally built to circumvent zoning regulations regarding water supply, and lists a few other examples, such as
- "Grafton, New Hampshire. It’s a tiny town that was taken over by libertarians who moved there en masse to create their vision of heaven on earth. They voted themselves into power, slashed taxes and cut the town’s already minuscule budget to the bone. Journalist Matthew Hongoltz-Hetling recounts what happened next:
- 'Grafton was a poor town to begin with, but with tax revenue dropping even as its population expanded, things got steadily worse. Potholes multiplied, domestic disputes proliferated, violent crime spiked, and town workers started going without heat. ...'
- Then the town was taken over by bears."
The article is worth reading:
The Wikipedia article is even more damning:
- "Grafton is an active hub for Libertarians as part of the Free Town Project, an offshoot of the Free State Project. Grafton's appeal as a favorable destination was due to its absence of zoning laws and a very low property tax rate. Grafton was the focus of a movement begun by members of the Free State Project that sought to encourage libertarians to move to the town. After a rash of lawsuits from Free Towners, an influx of sex offenders, an increase of crime, problems with bold local bears, and the first murders in the town's history, the Libertarian project ended in 2016."
Get Morse code from text
On Wikifunctions we have a function that translates text to Morse code. Go ahead, try it out.
I am stating that mostly in order to see if we can get Google to index the function pages on Wikifunctions, because we initially accidentally had them all set to not be indexed.
Playing around with Aliquot
- Warning! Very technical, not particularly insightful, and overly long post about hacking, discrete mathematics, and rabbit holes. I don't think that anything here is novel, others have done more comprehensive work, and found out more interesting stuff. This is not research, I am just playing around.
Ernest Davis is a NYU professor, author of many publications (including “Rebooting AI” with Gary Marcus) and a friend on Facebook. Two days ago he posted about Aliquot sequences, and that it is yet unknown how they behave.
What is an Aliquot sequence? Given a number, take all its proper divisors, and add them up. That’s the next number in the sequence.
It seems that most of these either lead to 0 or end in a repeating pattern. But it may also be that they just keep on going indefinitely. We don’t know if there is any starting number for which that is the case. But the smallest candidate for that is 276.
So far, we know the first 2,145 steps for the Aliquot sequence starting at 276. That results in a number with 214 digits. We don’t know the successor of that number.
I was curious. I know that I wouldn’t be able to figure this out quickly, or, probably ever, because I simply don’t have enough skills in discrete mathematics (it’s not my field), but I wanted to figure out how much progress I can make with little effort. So I coded something up.
Anyone who really wanted to make a crack on this problem would probably choose C. Or, on the other side of the spectrum, Mathematica, but I don’t have a license and I am lazy. So I chose JavaScript. There were two hunches for going with JavaScript instead of my usual first language, Python, which would pay off later, but I will reveal them later in this post.
So, my first implementation was very naïve (source code). The function that calculates the next step in the Aliquot sequence is usually called s in the literature, so I kept that name:
const divisors = (integer) => {
const result = []
for(let i = BigInt(1); i < integer; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
const sum = x => x.reduce( (partialSum, i) => partialSum + i, BigInt(0) )
const s = (integer) => sum(divisors(integer))
I went for BigInt, not integer, because Ernest said that the 2,145th step had 214 digits, and the standard integer numbers in JavaScript stop being exact before we reach 16 digits (at 9,007,199,254,740,991, to be exact), so I chose BigInt, which supports arbitrary long integer numbers.
The first 30 steps ran each under a second on my one decade old 4 core Mac occupying one of the cores, reaching 8 digits, but then already the 36th step took longer than a minute - and we only had 10 digits so far. Worrying about the limits of integers turned out to be a bit preliminary: With this approach I would probably not reach that limit in a lifetime.
I dropped BigInt and just used the normal integers (source code). That gave me 10x-40x speedup! Now the first 33 steps were faster than a second, reaching 9 digits, and it took until the 45th step with 10 digits to be the first one to take longer than a minute. Unsurprisingly, a constant factor speedup wouldn’t do the trick here, we’re fighting against an exponential problem after all.
It was time to make the code less naïve (source code), and the first idea was to not check every number smaller than the target integer whether it divides (line 3 above), but only up to half of the target integer.
const divisors = (integer) => {
const result = []
const half = integer / 2
for(let i = 1; i <= half; i++) {
if(integer % i == 0) result.push(i)
}
return result
}
Tiny change. And exactly the expected impact: it ran double as fast. Now the first 34 steps ran under one second each (9 digits), and the first one to take longer than a minute was the 48th step (11 digits).
Checking until half of the target seemed still excessive. After all, for factorization we only need to check until the square root. That should be a more than constant speedup. And once we have all the factors, we should be able to quickly reconstruct all the divisors. Now this is the point where I have to admit that I have a cold or something, and the code for creating the divisors from the factors is probably overly convoluted and slow, but you know what? It doesn’t matter. The only thing that matters will be the speed of the factorization.
So my next step (source code) was a combination of a still quite naïve approach to factorization, with another function that recreates all the divisors.
const factorize = (integer) => {
const result = [ 1 ]
let i = 2
let product = 1
let rest = integer
let limit = Math.ceil(Math.sqrt(integer))
while (i <= limit) {
if (rest % i == 0) {
result.push(i)
product *= i
rest = integer / product
limit = Math.ceil(Math.sqrt(rest))
} else {
i++
}
}
result.push(rest)
return result
}
const divisors = (integer) => {
const result = [ 1 ]
const inner = (integer, list) => {
result.push(integer)
if (list.length === 0) {
return [ integer ]
}
const in_results = [ integer ]
const in_factors = inner(list[0], list.slice(1))
for (const f of in_factors) {
result.push(integer*f)
result.push(f)
in_results.push(integer*f)
in_results.push(f)
}
return in_results
}
const list = factorize(integer)
inner(list[0], list.slice(1))
const im = [...new Set(result)].sort((a, b) => a - b)
return im.slice(0, im.length-1)
}
That made a big difference! The first 102 steps all were faster than a second, reaching 20 digits! That’s more than 100x speedup! And then, after step 116, the thing crashed.
Remember, integer only does well until 16 digits. The numbers were just too big for the standard integer type. So, back to BigInt. The availability of BigInt in JavaScript was my first hunch for choosing JavaScript (although that would have worked just fine in Python 3 as well). And that led to two surprises.
First, sorting arrays with BigInts is different from sorting arrays with integers. Well, I find already sorting arrays of integers a bit weird in JavaScript. If you don’t specify otherwise it sorts numbers lexicographically, instead of by value:
[ 10, 2, 1 ].sort() == [ 1, 10, 2 ]
You need to provide a custom sorting function in order to sort the numbers by value, e.g.
[ 10, 2, 1 ].sort((a, b) => a-b) == [ 1, 2, 10 ]
The same custom sorting functions won’t work for BigInt, though. The custom function for sorting requires an integer result, not a BigInt. We can write something like this:
.sort((a, b) => (a < b)?-1:((a > b)?1:0))
The second surprise was that BigInt doesn’t have a square root function in the standard library. So I need to write one. Well, Newton is quickly implemented, or copy and pasted (source code).
Now, with switching to BigInt, we get the expected slowdown. The first 92 steps run faster than a second, reaching 19 digits, and then the first step to take longer than a minute is step 119, with 22 digits.
Also, the actual sequences started indeed diverging, due to the inaccuracy of large JavaScript integer: step 83 resulted in 23,762,659,088,671,304 using integers, but 23,762,659,088,671,300 using BigInt. And whereas that looks like a tiny difference on only the last digit, the number for the 84th step showed already what a big difference that makes: 20,792,326,702,587,410 with integers, and 35,168,735,451,235,260 with BigInt. The two sequences went entirely off.
What was also very evident is that at this point some numbers took a long time, and others were very quick. This is what you would expect from a more sophisticated approach to factorization, that it depends on the number and size of the factors. For example, calculating step 126 required to factorize the number 169,306,878,754,562,576,009,556, leading to 282,178,131,257,604,293,349,484, and that took more than 2 hours with that script on my machine. But then in Step 128 the result 552,686,316,482,422,494,409,324 was calculated from 346,582,424,991,772,739,637,140 in less than a second.
At that point I also started taking some of the numbers, and googled them, surfacing a Japanese blog post from ten years ago that posted the first 492 numbers, and also confirming that the 450th of these numbers corresponds to a published source. I compared the list with my numbers and was happy to see they corresponded so far. But I guesstimated I would not in a lifetime reach 492 steps, never mind the actual 2,145.
But that’s OK. Some things just need to be let rest.
That’s also when I realized that I was overly optimistic because I simply misread the number of steps that have been already calculated when reading the original post: I thought it was about 200-something steps, not 2,000-something steps. Or else I would have never started this. But now, thanks to the sunk cost fallacy, I wanted to push it just a bit further.
I took the biggest number that was posted on that blog post, 111,953,269,160,850,453,359,599,437,882,515,033,017,844,320,410,912, and let the algorithm work on that. No point in calculating steps 129, which is how far I have come, through step 492, if someone else already did that work.
While the computer was computing, I leisurely looked for libraries for fast factorization, but I told myself that no way am I going to install some scientific C library for this. And indeed, I found a few, such as the msieve project. Unsurprising, it was in C. But I also found a Website, CrypTool-Online with msieve on the Web (that’s pretty much one of the use cases I hope Wikifunctions will also support rather soonish). And there, I could not only run the numbers I already calculated locally, getting results in subsecond speed which took minutes and hours on my machine, but also the largest number from the Japanese website was factorized in seconds.
That just shows how much better a good library is than my naïve approach. I was slightly annoyed and challenged by the fact how much faster it is. Probably also runs on some fast machine in the cloud. Pretty brave to put a site like that up, and potentially have other people profit from the factorization of large numbers for, e.g. Bitcoin mining on your hardware.
The site is fortunately Open Source, and when I checked the source code I was surprised, delighted, and I understood why they would make it available through a Website: they don’t factorize the number in the cloud, but on the edge, in your browser! If someone uses a lot of resources, they don’t mind: it’s their own resources!
They took the msieve C library and compiled it to WebAssembly. And now I was intrigued. That’s something that’s useful for my work too, to better understand WebAssembly, as we use that in Wikifunctions too, although for now server side. So I rationalized, why not see if I can get that run on Node.
It was a bit of guessing and hacking. The JavaScript binding was written to be used in the browser, and the binary was supposed to be loaded through fetch. I guessed a few modifications, replacing fetch with Node’s FS, and managed to run it in Node. The hacks are terrible, but again, it doesn’t really matter as long as the factorization would speed up.
And after a bit of trying and experimenting, I got it running (source code). And that was my second hunch for choosing JavaScript: it had a great integration for using WebAssembly, and I figured it might come in handy to replace the JavaScript based solution. And now indeed, the factorization was happening in WebAssembly. I didn’t need to install any C libraries, no special environments, no nothing. I just could run Node, and it worked. I am absolutely positive there are is cleaner code out there, and I am sure I mismanaged that code terribly, but I got it to run. At the first run I found that it added an overhead of 4-5 milliseconds on each step, making the first few steps much slower than with pure JavaScript. That was a moment of disappointment.
But then: the first 129 steps, which I was waiting hours and hours to run, zoomed by before I could even look. Less than a minute, and all the 492 steps published on the Japanese blog post were done, allowing me to use them for reference and compare for correctness so far. The overhead was irrelevant, even across the 2,000 steps the overhead wouldn’t amount to more than 10 seconds.
The first step that took longer than a second was step 596, working on a 58 digit number. All the first 595 steps took less than a second each. The first step that took more than a minute, was step 751, a 76 digit number, taking 62 seconds, factorizing 3,846,326,269,123,604,249,534,537,245,589,642,779,527,836,356,985,238,147,044,691,944,551,978,095,188. The next step was done in 33 milliseconds.
The first 822 steps took an hour. Step 856 was reached after two hours, so that’s another 34 steps in the second hour. Unexpectedly, things slowed down again. Using faster machines, modern architectures, GPUs, TPUs, potentially better algorithms, such as CADO-NFS or GGNFS, all of that could speed that up by a lot, but I am happy how far I’ve gotten with, uhm, little effort. After 10 hours, we had 943 steps and a 92 digit number, 20 hours to get to step 978 and 95 digits. My goal was to reach step 1,000, and then publish this post and call it a day. By then, a number of steps already took more than an hour to compute. I hit step 1000 after about 28 and a half hours, a 96 digit number: 162,153,732,827,197,136,033,622,501,266,547,937,307,383,348,339,794,415,105,550,785,151,682,352,044,744,095,241,669,373,141,578.
I rationalize this all through “I had fun” and “I learned something about JavaScript, Node, and WebAssembly that will be useful for my job too”. But really, it was just one of these rabbit holes that I love to dive in. And if you read this post so far, you seem to be similarly inclined. Thanks for reading, and I hope I didn’t steal too much of your time.
I also posted a list of all the numbers I calculated so far, because I couldn’t find that list on the Web, and I found the list I found helpful. Maybe it will be useful for something. I doubt it. (P.S.: the list was already on the Web, I just wasn't looking careful enough. Both, OEIS and FactorDB have the full list.)
I don’t think any of the lessons here are surprising:
- for many problems a naïve algorithm will take you to a good start, and might be sufficient
- but never fight against an exponential algorithm that gets big enough, with constant speedups such as faster hardware. It’s a losing proposition
- But hey, first wait if it gets big enough! Many problems with exponential complexity are perfectly solvable with naïve approaches if the problem stays small enough
- better algorithms really make a difference
- use existing libraries!
- advancing research is hard
- WebAssembly is really cool and you should learn more about it
- the state of WebAssembly out there can still be wacky, and sometimes you need to hack around to get things to work
In the meantime I played a bit with other numbers (thanks to having a 4 core computer!), and I will wager one ambitious hypothesis: if 276 diverges, so does 276,276, 276,276,276, 276,276,276,276, etc., all the way to 276,276,276,276,276,276,276,276,276, i.e. 9 times "276".
I know that 10 times "276" converges after 300 steps, but I have tested all the other "lexical multiples" of 276, and reached 70 digit numbers after hundreds of steps. For 276,276 I pushed it further, reaching 96 digits at step 640. (And for at least 276,276 we should already know the current best answer, because the Wikipedia article states that all the numbers under one million have been calculated, and only about 9,000 have an unclear fate. We should be able to check if 276,276 is one of those, which I didn't come around to yet).
Again, this is not research, but just fooling around. If you want actual systematic research, the Wikipedia article has a number of great links.
Thank you for reading so far!
P.S.: Now that I played around, I started following some of the links, and wow, there's a whole community with great tools and infrastructure having fun about Aliquot sequences and prime numbers doing this for decades. This is extremely fascinating.
The Surrounding Sea
Explore the ocean of words in which we all are swimming, day in day out. A site that allows you to browse through the lexicographic data in Wikidata along four dimensions:
- alphabetical, like in a good old fashioned dictionary
- through translations and synonyms
- where does this word come from, and where did it go
- narrower and wider words, describing a hierarchy of meanings
Wikidata contains over 1.2 million lexicographic entries, but you will see the many gaps when exploring the sea of words. Please join us in charting out more of the world of words.
Happy 23rd birthday to Wikipedia and the movement it started!
Das Mädchen Doch
Sie sagten ihrer Mutter
Kinder werde sie nie haben
Und als sie geboren wurde
Nannte ihre Mutter sie
Doch
Sie sagten sie sei schwach
Und klein und krank
Und dass sie nicht
Lange zu leben habe
Doch
Ihre Mutter hoffte
Das sie in einer Welt aufwuchs
In der alle gleich behandelt wurden
Aber leider
Doch
Sie sagten Mathe und Autos
Seien nichts für Mädchen
Dass sie sich interessiert
Für Puppen und für Kleidung
Doch
Sie sagten die Welt
Ist wie sie ist
Und sie zu ändern
Sei nichts für kleine kranke Mädchen
Doch
Sie sagten gut dass Du darüber sprachst
Wir sollten darüber nachdenken
Lass uns jetzt darüber debattieren
Und wir (nicht Du) entscheiden dann
Doch
Sie sagten man kann nicht alles haben
Man muss sich entscheiden
Aber so selbstsüchtig
Ich meine, keine Kinder zu wollen
Doch
Sie sagten sie sei unanständig
So ein Leben sei nicht richtig
Benannten sie mit unanständigen Worten
Was sie sich denn erlaube
Doch
Sie sagten das geht doch nicht
So ein Leben sei kein Leben
Das ist jetzt schon sehr anders
Das ist nicht einfach nur Neid
Doch
Sie sagten wir sind halt nicht so
Und wollen auch nicht so sein
Wir sind glücklich wie wir sind
Und deswegen darfst du glücklich nicht sein
Doch
Languages with the best lexicographic data coverage in Wikidata 2023
Languages with the best coverage as of the end of 2023
- English 92.9%
- Spanish 91.3%
- Bokmal 89.1%
- Swedish 88.9%
- French 86.9%
- Danish 86.9%
- Latin 85.8%
- Italian 82.9%
- Estonian 81.2%
- Nynorsk 80.2%
- German 79.5%
- Basque 75.9%
- Portuguese 74.8%
- Malay 73.1%
- Panjabi 71.0%
- Slovak 67.8%
- Breton 67.3%
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data.
The list contains all languages where the data covers more than two thirds of the selected corpus.
Progress in lexicographic data in Wikidata 2023
Here are some highlights of the progress in lexicographic data in Wikidata in 2023
- Greek jumped from 0% to 45% right away
- Panjabi jumped right away from 0% to 71% (but on an admittedly small corpus)
- Italian made a huge jump from 52% to 82% by increasing the number of forms from 9,000 to 286,000
- Turkish jumped from 0.9% to 22%
- Sindhi climbed from 15% to 25%
- Farsi climbed from 15% to 24% increasing the number of forms from 4,000 to 33,000
- Western Panjabi climbed from 36.9% to 47.9%
- Hindi climbed from 49.9% to 65.9%
- Breton increased from 56% to 67%
- Croatian increased from 40% to 45%
- Dutch went from 20% to 29%
- French from 82.9% to 86.9%, mostly by dealing better with apostrophes in the analysis
- Nynorsk pushed from 75% to 80% by increasing the number of forms from 18,000 to 68,000
- Danish from 83.9% to 86.9% by increasing the number of forms in Wikidata from 65,000 to 170,000
- German from 76% to 79% by increasing the number of forms in Wikidata from 90,000 to 200,000
- Spanish pushed from 88% to 91% by increasing the number of forms from 280,000 to 430,000
What does the coverage mean? Given a text (usually Wikipedia in that language, but in some cases a corpus from the Leipzig Corpora Collection), how many of the occurrences in that text are already represented as forms in Wikidata's lexicographic data. Note that every percent more gets much more difficult than the previous one: an increase from 1% to 2% usually needs much much less work than from 91% to 92%.
RIP Niklaus Wirth
RIP Niklaus Wirth;
BEGIN
I don't think there's a person who created more programming languages that I used than Wirth: Pascal, Modula, and Oberon; maybe Guy Steele, depending on what you count;
Wirth is also famous for Wirth's law: software becomes slower more rapidly than hardware becomes faster;
He received the 1984 Turing Award, and had an asteroid named after him in 1999; Wirth died at the age of 89;
END.
Wikidata lexicographic data coverage for Croatian in 2023
Last year, I published ambitious goals for the coverage of lexicographic data for Croatian in Wikidata. My self-proclaimed goal was widely missed: I wanted to go from 40% coverage to 60% -- instead, thanks to the help of contributors, we reached 45%.
We grew from 3,124 forms to 4,115, i.e. almost a thousand new forms, or about 31%. The coverage grew from around 11 million tokens to about 13 million tokens in the Croatian Wikipedia, or, as said, from 40% to 45%. The covered forms grew from 1.4% to 1.9%, which illustrates neatly the increased difficulty to reach more coverage (thanks to Zipf's law): last year, we increased covered forms by 1%, which translated to an overall coverage increase of occurrences by 35%. This year, although we increased the covered forms by another 0.5%, we only got an overall coverage increase of occurrences by 5%.
But some of my energy was diverted from adding more lexicographic data to adding functions that help with adding and checking lexicographic data. We launched a new project, Wikifunctions, that can hold functions. There, we collected functions to create the regular forms for Croatian nouns. All nouns are now covered.
I think that's still a great achievement and progress. Sure, we didn't meet the 60%, but the functions helped a lot to get to the 45%, and they will continue to benefit us 2024 too. Again, I want to declare some goals, at least for myself, but not as ambitious with regards to coverage: the goal for 2024 is to reach 50% coverage of Croatian, and in addition, I would love us to have Lexeme forms available for verbs and adjectives, not only for nouns, (for verbs, Ivi404 did most of the work already), and maybe even have functions ready for adjectives.
Star Trek's 32nd century
I like Star Trek for the cool technology, which has inspired plenty of people to work eg on "the Star Trek computer". I love Star Trek for the utopian society of plenty they sketch in the 23rd and 24th century.
I claim it is because of the laziness of the writing: they don't keep that utopia up.
When I heard about Discovery going to the 32nd century, I was excited about the wonders they would dream up. The new technology. The society. The culture. The breakthroughs.
With regards to that, it was a massive let down. Extremely disappointing.
Finding God through Information Theory
I found that surprising: Luciano Floridi, one of the most-cited living philosophers, started studying information theory because young Floridi, still Catholic, concluded that God's manifestation to humanity must be an information process. He wanted to understand God's manifestation through the lens of information.
He didn't get far in answering that question, but he did become the leading expert in the Philosophy of Information, and an expert in Digital Ethics (and also, since then, an agnostic).
Post scriptum: The more I think about it, the more I like the idea. Information theory is not even one of these vague, empirical disciplines such as Physics, but more like Mathematics and Logics, and thus unavoidable. Any information exchange, i.e. communication, must follow its rules. Therefore the manifestation of God, i.e. the way God chooses to communicate themselves to us, must also follow information theory. So this should lead to some necessary conditions on the shape of such a manifestation.
It's a bright idea. I am not surprised it didn't go anywhere, but I still like the idea.
Could have at least engendered a novel Proof for the Existence of God. They have certainly come from more surprising corners.
Source: https://philosophy.fireside.fm/1
More about Luciano Flordi on Wikipedia.
Little One's first GIF
Little One made her first GIF!

Moving to Germany
We are moving to Germany. It was a long and difficult decision process.
Is it the right decision? Who knows. These kinds of decisions are rarely right or wrong, but just are.
What about your job? I am thankful to the Wikimedia Foundation for allowing me to move and keep my position. The work on Abstract Wikipedia and Wikifunctions is not done yet, and I will continue to lead the realization of this project.
Don’t we like it in California? We love so many things about California and the US, and the US has been really good to us. Both my wife and I grew here in our careers, we both learned valuable skills, and met interesting people, some of whom became friends, and who I hope to continue to keep in touch. Particularly my time at Google was also financially a boon. And it also gave me the freedom to prepare for the Abstract Wikipedia project, and to get to know so many experts in their field and work together with them, to have the project criticized and go through several iterations until nothing seems obviously wrong with it. There is no place like the Bay Area in the world of Tech. It was comparably easy to have meetings with folks at Google, Facebook, Wikimedia, LinkedIn, Amazon, Stanford, Berkeley, or to have one of the many startups reach out for a quick chat. It is, in many ways, a magical place, and no other place we may move to will come even close to it with regards to its proximity to tech.
And then there’s the wonderful weather in the Bay Area and the breathtaking nature of California. It never gets really hot, it never gets really cold. The sun is shining almost every day, rain is scarce (too scarce), and we never have to drive on icy streets or shovel snow. If we want snow, we can just drive up to the Sierras. If we want heat, drive inland. We can see the largest trees in the world, walk through the literal forests of Endor, we can hike hills and mountains, and we can walk miles and miles along the sand beaches of the Pacific Ocean. California is beautiful.
Oh, and the food and the produce! Don’t get me started on Berkeley Bowl and its selection of fruits and vegetables. Of the figs in their far too short season, of the dry-farmed Early Girl tomatoes and their explosion of taste, of the juicy and rich cherries we picked every year to carry pounds and pounds home, and to eat as many while picking, the huge diversity of restaurants in various states from authentic to fusion, but most of them with delicious options and more dishes to try than time to do it.
And not just the fruits and vegetables are locally sourced: be it computers from Apple, phones from Google, the social media from Facebook or Twitter, the wonderful platform enabling the Wikimedia communities, be it cars from Tesla, be it movies from Pixar, the startups, the clouds, the AIs: so. many. things. are local. And every concert tour will pass by in the Bay Area. In the last year we saw so many concerts here, it was amazing. That’s a place the tours don’t skip.
Finally: in California, because so many people are not from here, we felt more like we belong just as well as everyone else, than anywhere else. Our family is quite a little mix, with passports from three continents. Our daughter has no simple roots. Being us is likely easier in the United States than in any of the European nation states with their millenia of identity. After a few years I felt like an American. In Germany, although it treated me well, after thirty years I still was an Ausländer.
As said, it is a unique place. I love it. It is a privilege and an amazing experience to have spent one decade of my life here.
Why are we moving? In short, guns and the inadequate social system.
In the last two years alone, we had four close-ish encounters with people wielding guns (not always around home). And we are not in a bad neighborhood, on the contrary. This is by all statistics one of the safest neighborhoods you will find in the East Bay or the City.
We are too worried to let the kid walk around by herself or even with friends. This is such a huge difference to how I grew up, and such a huge difference to when we spent the summer in Croatia, and she and other kids were off by themselves to explore and play. Here, there was not a single time she went to the playground or visited a friend by herself, or that one of her friends visited our house by themselves.
But even if she is not alone: going to the City with the kid? There are so many places there I want to avoid. Be it around the city hall, be it in the beautiful central library, be it on Market Street or even just on the subway or the subway stations: too often we have to be careful to avoid human excrement, too often we are confronted with people who are obviously in need of help, and too often I feel my fight or flight reflexes kicking in.
All of this is just the visible effect of a much larger problem, one that we in the Bay Area in particular, but as Americans in general should be ashamed of not improving: the huge disparity between rich and poor, the difficult conditions that many people live in. It is a shame that so many people who are in dire need of professional help live on the streets instead of receiving mental health care, that there are literal tent cities in the Bay Area, while the area is also the home of hundreds of thousands of millionaires and more than sixty billionaires - more than the UK, France, or Switzerland. It is a shame that so many people have to work two or more jobs in order to pay their rent and feed themselves and their children, while the median income exceeds $10,000 a month. It is a shame that this country, which calls itself the richest and most powerful and most advanced country in the world, will let its school children go hungry. Is “school lunch debt” a thing anywhere else in the world? Is “medical bankruptcy” a thing anywhere else in the world? Where else are college debts such a persistent social issue?
The combination of the easy availability of guns and the inadequate social system leads to a large amount of avoidable violence and to tens of thousands of seemingly avoidable deaths. And they lead to millions of people unnecessarily struggling and being denied a fair chance to fulfill their potential.
And the main problem, after a decade living here, is not where we are, but the trajectory of change we are seeing. I don’t have hope that there will be a major reduction in gun violence in the coming decade, on the contrary. I don’t have hope for any changes that will lead to the Bay Area and the US spreading the riches and gains it is amassing substantially more fairly amongst its population, on the contrary. Even the glacial development in self-driving cars seems breezy compared to the progress towards killing fewer of our children or sharing our profits a little bit more fairly.
After the 1996 Port Arthur shooting, Australia established restrictions on the use of automatic and semi-automatic weapons, created a gun buyback program that removed 650,000 guns from circulation, a national gun registry, and a waiting period for firearms sales. They chose so.
After the 2019 Christchurch shooting, New Zealand passed restrictions on semi-automatic weapons and a buyback program removed 50,000 guns. They chose so.
After the shootings earlier this year in Belgrade, Serbia introduced stricter laws and an amnesty for illegal weapons and ammunition if surrendered, leading to more than 75,000 guns being removed. They chose so.
I don’t want to list the events in the US. There are too many of them. And did any of them lead to changes? We choose not to.
We can easily afford to let basically everyone in the US live a decent life and help those that need it the most. We can easily afford to let no kid be hungry. We can easily afford to let every kid have a great education. We choose not to.
I don’t want my kid to grow up in a society where we make such choices.
I could go on and rant about the Republican party, about Trump possibly winning 2024, about our taxes supporting and financing wars in places where they shouldn’t, about xenophobia and racism, about reproductive rights, trans rights, and so much more. But unfortunately many of these topics are often not significantly better elsewhere either.
When are we moving? We plan to stay here until the school year is over, and aim to have moved before the next school year starts. So in the summer of ‘24.
Where are we moving? I am going back to my place of birth, Stuttgart. We considered a few options, and Stuttgart led overall due to the combination of proximity to family, school system compatibility for the kid, a time zone that works well for the Abstract Wikipedia team, language requirements, low legal hurdles of moving there, and the cost of living we expect. Like every place it also comes with challenges. Don’t get me started on the taste of tomatoes or peaches.
What other places did we consider? We considered many other places, and we traveled to quite a few of them to check them out. We loved each and every one of them. We particularly loved Auckland due to our family there and the weather, we loved the beautiful city of Barcelona for its food and culture, we loved Dublin, London, Zürich, Berlin, Vienna, Split. We started making a large spreadsheet with pros and contras in many categories, but in the end the decision was a gut decision. Thanks to everyone who talked with us and from whom we learned a lot about those places!
Being able to even consider moving to these places is a privilege. And we understand that and are thankful for having this privilege. Some of these places would have been harder to move for us due to immigration regulation, others are easy thanks to our background. But if you are thinking of moving, and are worried about certain aspects, feel free to reach out and discuss. I am happy to offer my experience and perspective.
Is there something you can help with? If you want to meet up with us while we are still in the US, it would be good to do so timely. We are expecting to sell the house quite a bit sooner, and then we won’t be able to host guests easily. I am also looking forward to reconnecting with people in Europe after the move. Finally, if you know someone who is interested in a well updated 3 bedroom house with a surprisingly large attic that can be used as a proper hobby space, and with a top walkability index in south Berkeley, point them our way.
Also, experiences and advice regarding moving from the US to Germany are welcome. Last time we moved the other way, and we didn’t have that much to move, and Google was generously organizing most of what needed to be done. This time it’s all on us. How to get a container and get it loaded? How to ship it to Germany? Where to store it while we are looking for a new home? How to move the cat? How to make sure all goes well with the new school? When to sell the house and where to live afterwards? How to find the right place in Germany? What are the legal hurdles to expect? How will taxes work? So many questions we will need to answer in the coming months. Wish us luck for 2024.
We also accept good wishes and encouraging words. And I am very much looking forward to seeing some of you again next year!
Sam Altman and the veil of ignorance
(This is not about Altman having been removed as CEO of OpenAI)
During the APEC forum on Thursday, Sam Altman has been cited to having said the following thing: "Four times now in the history of OpenAI—the most recent time was just in the last couple of weeks—I’ve gotten to be in the room when we push the veil of ignorance back and the frontier of discovery forward. And getting to do that is like the professional honor of a lifetime."
He meant that as an uplifting quote to describe how awesome his company and their achievements are.
I find it deeply worrying. Why?
The "veil of ignorance" (also known as the original position) is a thought experiment introduced by John Rawls, one of the leading American moral and political philosophers of the 20th century. The goal is to think about the fairness of a society or a social system without you knowing where in the system you end up: are you on top or at the bottom? What are your skills, your talents? Who are your friends? Do you have disabilities? What is your gender, your family history?
The whole point is to *not* push the veil of ignorance back, otherwise you'll create an unfair system. It is a good tool to think about the coming disruptions by AI technology.
The fact that he's using that specific term but is obviously entirely oblivious to its meaning tells us that there was a path that term took, probably from someone working on ethics to then-CEO Altman, and that someone didn't listen. The meaning was lost, and the beautiful phrase was entirely repurposed.
Given that's coming from the then-CEO of the company that claims and insists on, again and again (without substantial proof) that they are doing all this for the greater benefit of all humanity, that are, despite their name, increasingly closing their results, making public scrutiny increasingly difficult if not impossible - well, I find that worrying. The quote indicates that they have no idea about a basic tool towards evaluating fairness, even worse, have heard about it - but they have not listened or comprehended.
Babel
Strong recommendation for "Babel" by R.F. Kuang. It's a speculative fiction story set in 1830s Oxford with an, as far as I can tell, novel premise: one can cast spells (although they don't call it spells but it's just science in this world) by using two words that translate into each other, and the semantic difference between the two words - because no translation is perfect - is the effect of the spell. But the effect can only be achieved if you have a speaker who's fluent enough in both languages to have a native understanding of the difference.
One example would be the French parcelle and the English parcel, both meaning package, but the French still carries some of the former "to split into parts", with the effect that packages are lighter and easier to transport for the Royal Mail.
The story remains comfortable for the first half of the volume, with beautiful world building, character drawing, and the tranquil academic life of Oxford students, but then it suddenly picks up speed, and we can experience the events unfold with a merciless speed. The end is just in the right place, and it leaves me to yearn to revisit this world and the desire to learn what happened next.
The volume discusses some heavy topics - colonialism, dependency on technology, fairness, what is allowed in a revolution, the "neutrality" of science - and while we are still in the first half of the volume, it feels very on the nose, very theoretical - but that changes dramatically as we swing into the second half of the volume, and suddenly all these theoretical discussions become very immediate. Which does remind me of student life, where discussions about different political systems and abstract notions of justice are just as prevalent and as consequence-free as they seem to be here, at first.
The book was recommended by the Lingthusiasm podcast, which is how I found it.
I came for the linguistic premise, but I stayed for the characters and their fates in a colonial world.
Existential crises
I think the likelihood of AI killing all humans is bigger than the likelihood of climate change killing all humans.
Nevertheless I think that we should worry and act much more about climate change than about AI.
Allow me to explain.
Both AI and climate change will, in this century, force changes to basically every aspect of the lives of basically every single person on the planet. Some people may benefit, some may not. The impact of both will be drastic and irreversible. I expect the year 2100 to look very different from 2000.
Climate change will lead to billions of people to suffer, and to many deaths. It will destroy the current livelihoods of many millions of people. Many people will be forced to leave their homes, not because they want to, but because they have to in order to survive. Richer countries with sufficient infrastructure to deal with the direct impact of a changed climate will have to decide how to deal with the millions of people who want to live and who want their children not to die. We will see suffering on a scale never seen before, simply because there have never been this many humans on the planet.
But it won't be an existential threat to humanity (the word humanity has at least two meanings: 1) the species as a whole, and 2) certain values we associate with humans. Unfortunately, I only refer to the first meaning. The second meaning will most certainly face a threat). Humanity will survive, without a doubt. There are enough resources, there are enough rich and powerful people, to allow millions of us to shelter away from the most life threatening consequences of climate change. Millions will survive for sure. Potentially at the costs of many millions lives and the suffering of billions. Whole food chains, whole ecosystems may collapse. Whole countries may be abandoned. But humanity will survive.
What about AI? I believe that AI can be a huge boon. It may allow for much more prosperity, if we spread out the gains widely. It can remove a lot of toil from the life of many people. It can make many people more effective and productive. But history has shown that we're not exactly great at sharing gains widely. AI will lead to disruptions in many economic sectors. If we're not careful (and we likely aren't) it might lead to many people suffering from poverty. None of these pose an existential threat to humanity.
But there are outlandish scenarios which I think might have a tiny chance of becoming true and which can kill every human. Even a full blown Terminator scenario where drones hunt every human because the AI has decided that extermination is the right step. Or, much simpler, that in our idiocy we let AI supervise some of our gigantic nuclear arsenal, and that goes wrong. But again, I merely think these possible, but not in the slightest likely. An asteroid hitting Earth and killing most of us is likelier if you ask my gut.
Killing all humans is a high bar. It is an important bar for so called long-termists, who may posit that the death of four or five billion people isn't significant enough to worry about, just a bump in the long term. They'd say that they want to focus on what's truly important. I find that reasoning understandable, but morally indefensible.
In summary: there are currently too many resources devoted to thinking about the threat of AI as an existential crisis. We should focus on the short term effect of AI and aim to avoid as many of the negative effects as possible and to share the spoils of the positive effects. We're likely to end up with socializing the negative effects, particularly amongst the weakest members of society, and privatizing the benefits. That's bad.
We really need to devote more resources towards avoiding climate change as far as still possible, and towards shielding people and the environment from the negative effects of climate change. I am afraid we're failing at that. And that will cause far more negative impact in the course of this century than any AI will.
Wikidata crossed 2 billion edits
The Wikidata community edited Wikidata 2 billion times!
Wikidata is, to the best of my knowledge, the first and only wiki to cross 2 billion edits (the second most edited one being English Wikipedia with 1.18 billion edits).
Edit Nr 2,000,000,000 was adding the first person plural future of the Italian verb 'grugnire' (to grunt) by user Luca.favorido.
Wikidata also celebrated 11 years since launch with the hybrid WikidataCon 2023 in Taipei last weekend.
It took from 2012 to 2019 to get the first billion, and from 2019 to now for the second. As they say, the first billion is the hardest.
That the two billionth edit happens right on the Birthday is a nice surprise.
The letter Đ
The letter Đ was introduced to Serbo-Croatian by Đuro Daničić, according to Wikipedia. I found that highly amusing, that he introduced the letter that is the first letter in his name.
Wikipedia also claims that he was born Đorđe Popović, and all I can think of is "nah, that can't be right".
That would be like Jebediah Springfield who was born in a cabin that he helped build.
Pastir Loda
Vladimir Nazor is likely the most famous author from the island of Brač, the island my parents are from. His most acclaimed book seems to be Pastir Loda, Loda the Shepherd. It tells the story of a satyr that, through accidents and storms, was stranded on the island of Brač, and how he lived on Brač for the next almost two thousand years.
It is difficult to find many of his works, they are often out of print. And there isn't much available online, either. Since Nazor died in 1949, his works are in the public domain. I acquired a copy of Pastir Loda from an antique book shop in Zagreb, which I then forwarded to a friend in Denmark who has a book scanner, and who scanned the book so I can make the PDF available now.
The book is written in Croatian. There is a German translation, but that won't get into the public domain until 2043 (the translator lived until 1972), and according to WorldCat there is a Czech translation, and according to Wikipedia a Hungarian translation. For both I don't know who the translator is, and so I don't know the copyright status of these translations. I also don't know if the book has ever been translated to other languages.
I wish to find the time to upload and transcribe the content on Wikisource, and then maybe even do a translation of it into English. For now I upload the book to archive.org, and I also make it available on my own Website. I want to upload it to Wikimedia Commons, but I immediately stumbled upon the first issue, that it seems that to upload it to Commons the book needs to be published before 1928 and the author has to be dead for more than 70 years (I think that should be an or). I am checking on Commons if I can upload it or not.
Until then, here's the Download:
F in Croatian
I was writing some checks to find errors in the lexical data in Wikidata for Croatian, and one of the things I tried was to check whether the letters in the words are all part of the Croatian alphabet. But instead of just taking a list, or writing down from memory, I looked at the data, and added letter after letter. And then I was surprised to find that the letter "f" only appears in loanwords. And I look it up in the Croatian Encyclopedia and it simply states that "f" is not a letter of the old slavic language.
I was mindblown. I speak this language since I can remember, and i didn't notice that there is no "f" but in loanwords. And "f" seems like such a fundamental sound! But no, wrong!
If you speak a slavic language, do you have the letter "f"?
Do you hear the people sing?
"Do you hear the people sing, singing the song of angry men..."
Yesterday, a London performance of Les Miserables was interrupted by protesters raising awareness about climate change.
The audience booed.
It seems the audience was unhappy about having to experience protests and unrest during the performance of protests and unrest they wanted to enjoy.
The hypocrisy is rich in this one, but a very well engineered and expected one. But I guess only with the luxury of being detached from the actual event one can afford to enjoy the hypocrisy. I assume that for many people attending a West End London production of Les Miserables aims to be a proper highlight of the year, if not more. It's something that children gift their parents for the 30th wedding anniversary. It may be the reason for a trip to London. In addition, attending a performance like this is an escapist act, that you don't want interrupted with the problems of the real world. And given that it is a life performance, it seems disrespectful to the cast, to the artists, who pour their lives into their roles.
On the other side, the existential dread about climate change, and the insufficient actions by world leaders seem to demand increasingly bolder action and more attention. We are teaching our kids that they should act if something is not right. And we are telling them about the predictions for climate change. And then we are surprised if they try to do something? The message that climate change will be extremely disruptive to our lives and that we need to act much more decisively has obviously not yet been understood by enough people. And we, humanity, our leaders, elected or not, are most certainly not yet doing enough to try to prevent or at least mitigate the effects of climate change that are starting to roll over us.
It would be good, but admittedly unlikely, if both sides could appreciate the other more. Maybe the audience might be a bit appreciative of seeing the people sing the song of angry men in real. And maybe the protesters could choose their targets a bit more wisely. Why choose art? There are more disruptive targets if you were to protest the oil industry than a performance of Les Miserables. To be honest, if i were working for the oil industry, this is exactly the kind of actions I would be setting up. And with people who are actually into the cause. That way I can ensure that people will talk about interrupted theater productions and defaced paintings, instead of again having the hottest year in history, of floods, heatwaves, hurricanes, and the thousands of people who already died due to climate change induced catastrophes - and the billions more whose life will be turned upside down.
Immortal relationships
I saw a beautiful meme yesterday that said that from the perspective of a cat or dog, humans are like elves who live for five hundred years and yet aren't afraid to bond with them for their whole life. And it is depicted as beautiful and wholesome.
It's so different from all those stories of immortals, think of Vampires or Highlander or the Sandman, where the immortals get bitter, or live in misery and loss, or become aloof and uncaring about human lives and their short life spans, and where it hurts them more than it does them good.
There seem to be more stories exploring the friendship of immortals with short-lived creatures, be it in Rings of Power with the relationship of Elrond and Durin, be it the relation of Star Trek's Zora with the crew of the Discovery or especially with Craft in the short movie Calypso, or between the Eternal Sersi and Dane Whitman. All these relations seem to be depicted more positively and less tragic.
In my opinion that's a good thing. It highlights the good parts in us that we should aspire to. It shows us what we can be, based in a very common perception, the relationship to our cats and dogs. Stories are magic, in it's truest sense. Stories have an influence on the world, they help us understand the world, imagine the impact we can have, explore us who we can be. That's why I'm happy to see these more positive takes on that trope compared to the tragic takes of the past.
(I don't know if any of this is true. I think it would require at least some work to actually capture instances of such stories, classify and tally them, to see if that really is the case. I'm not claiming I've done that groundwork, but just capture an observation that I'd like to be true, but can't really vouch for it.)
Molly Holzschlag (1963-2023)
May her memory be a blessing.
She taught the Web to many, and she fought for the Web of many.
Doug Lenat (1950-2023)
When I started studying computer science, one of the initiation rites was to read the Jargon File. I stumbled when I read the entry on the microlenat:
microlenat: The unit of bogosity. Abbreviated μL, named after Douglas Lenat. Like the farad it is considered far too large a unit for practical use, so bogosity is usually expressed in microlenats.
I had not heard of Douglas Lenat then. English being my third language, I wasn’t sure what bogosity is. So I tried to learn a bit more to understand it, and I read a bit about Cyc and Eurisko, but since I just started computer science, my mind wasn’t really ready for things such as knowledge representation and common sense reasoning. I had enough on my plate struggling with resistors, electronegativity, and fourier transformations. Looking back, it is ironic that none of these played a particular role in my future, but knowledge representation sure did.
It took me almost ten years to come back to Cyc and Lenat’s work. I was then studying ontological engineering, a term that according to Wikipedia was coined by Lenat, a fact I wasn’t aware of at that time. I was working with RDF, which was co-developed by Guha, who has worked with Lenat at Cycorp, a fact I wasn’t aware of at that time. I was trying to solve problems that Lenat had tackled decades previously, a fact I wasn’t aware of at that time.
I got to know Cyc through OpenCyc and Cyc Europe, led by Michael Witbrock. I only met Doug Lenat a decade later when I was at Google.
Doug’s aspirations and ambitions had numerous people react with rolling eyes and sneering comments, as can be seen in the entry in the Jargon File. And whereas I might have absorbed similar thoughts as well, they also inspired me. I worked with a few people who told me “consider yourself lucky if you have a dozen people reading your paper, that’s the impact you will likely have”, but I never found that a remotely satisfactory idea. Then there were people like Doug, who shouted out “let’s solve common sense!”, and stormed ahead trying to do so.
His optimism and his bias to action, his can-do attitude, surely influenced me profoundly in choosing my own way forward. Not only once did I feel like I was channeling Lenat when I was talking about knowledge bases that anyone can edit, about libraries of functions anyone can use, or about abstract representations of natural language texts. And as ambitious as these projects have been called, they all carefully avoid the incomparably more ambitious goals Doug had his eyes set on.
And Doug didn’t do it from the comfort of a tenured academic position, but he bet his career and house on it, he founded a company, and kept it running for four decades. I was always saddened that Cyc was kept behind closed doors, and I hope that this will not hinder the impact and legacy it might have, but I understand that this was the magic juice that kept the company running.
One of Doug’s systems, Eurisko, became an inspiration and namesake for an AI system that played the role of the monster of the week in a first season episode of the X-Files, a fact I wasn’t aware of until now. Doug was a founder and advisory member of the TTI/Vanguard series of meetings, to which I was invited to present an early version of Abstract Wikipedia, a fact I wasn’t aware of until now. And I am sure there are more facts about Doug and his work and how it reverberated with mine that I am unaware of still.
Doug was a person ahead of their time, a person who lived, worked on and saw a future about knowledge that is creative, optimistic and inspiring. I do not know if we will ever reach that future, but I do know that Doug Lenat and his work will always be a beacon on our journey forward. Doug Lenat died yesterday in Austin, Texas, two weeks shy of his 73rd birthday, after a battle with cancer.
To state it in CycL, the language Cyc is written in:
(#$dateOfDeath #$DougLenat "2023-08-31")
(#$restInPeace #$DougLenat)
Butter
So, I went to the store with Little One today, and couldn't find the butter.
I ask the person at the cheese stand, who points me to the burrata. Tasty, but not what I'm looking for. I ask again and he sends me to the bread section.
I can't find it at the bread section, so I ask the person at the pastries stand where the butter is. She points me to the bagels. I say no, butter. She says, ah, there, pointing to the bathrooms. I'm getting exasperated, and I ask again. She points back to the cheeses with the burrata. I try again. She gets a colleague, and soon they both look confused.
Finally my daughter chimes in, asking for the butter. They immediately point her to the right place and we finally get the butter.
I haven't been so frustrated about my English pronunciation since I tried to buy a thermometer.
The Jones Brothers
The two Jones brothers never got along, but both were too stubborn to leave the family estate. They built out two entrances to the estate, one from the south, near Jefferson Avenue, and the newer, bigger one, closer to the historic downtown, and each brother chose to use one of the entrances exclusively, in order to avoid the other and their family. To the confusion of the local folk (but to the open enjoyment of the high school's grammar teacher, who was, surprisingly for his role, a descriptivist), they named the western gate the Jones' gate, and the southern one the Jones's gate, and the brothers earnestly thought that that settled it.
It didn't.
The Future of Knowledge Graphs in a World of Large Language Models
The Knowledge Graph Conference 2023 in New York City invited me for a keynote on May 11, 2023. Given that basically all conversations these days are about large language models, I have given a talk about my understanding on how knowledge graphs and large language models go together.
After the conference, I did a recording of the talk, giving it one more time, in order to improve the quality of the recording. The talk had gotten more than 10,000 views on YouTube so far, which, for me, is totally astonishing.
I forgot to link it here, so here we go finally:
Hot Skull
I watched Hot Skull on Netflix, a Turkish Science Fiction dystopic series. I knew there was only one season, and no further seasons were planned, so I was expecting that the story would be resolved - but alas, I was wrong. And the book the show is based on is only available in Turkish, so I wouldn't know of a way to figure out how the story end.
The premise is that there is a "semantic virus", a disease that makes people 'jabber', to talk without meaning (but syntactically correct), and to be unable to convey or process any meaning anymore (not through words, and very limited through acts). They seem also to loose the ability to participate in most parts of society, but they still take care of eating, notice wounds or if their loved ones are in distress, etc. Jabbering is contagious, if you hear someone jabber, you start jabbering as well, jabberers cannot stop talking, and it quickly became a global pandemic. So they are somehow zombieish, but not entirely, raising questions about them still being human, their rights, etc. The hero of the story is a linguist.
Unfortunately, the story revolves around the (global? national?) institution that tries to bring the pandemic under control, and which has taken over a lot of power (which echoes some of the conspiracy theories of the COVID pandemic), and the fact that this institution is not interested in finding a cure (because going back to the former world would require them to give back the power they gained). The world has slid into economic chaos, e.g. getting chocolate becomes really hard, there seems to be only little international cooperation and transportation going on, but there seems to be enough food (at least in Istanbul, where the story is located). Information about what happened in the rest of the world is rare, but everyone seems affected.
I really enjoyed the very few and rare moments where they explored the semantic virus and what it does to people. Some of them are heart-wrenching, some of them are interesting, and in the end we get indications that there is a yet unknown mystery surrounding the disease. I hope the book at least resolves that, as we will probably never learn how the Netflix show was meant to end. The dystopic parts about a failing society, the whole plot about an "organization taking over the world and secretly fighting a cure", and the resistance to that organization, is tired, not particularly well told, standard dystopic fare.
The story is told very slowly and meanders leisurely. I really like the 'turkishness' shining through in the production: Turkish names, characters eating simit, drinking raki, Istanbul as a (underutilized) background, the respect for elders, this is all very well meshed into the sci-fi story.
No clear recommendation to watch, mostly because the story is unfinished, and there is simply not enough payoff for the lengthy and slow eight episodes. I was curious about the premise, and still would like to know how the story ends, what the authors intended, but it is frustrating that I might never learn.
The right to work
I've been a friend of Universal Basic Income for thirty years, but in the last twenty years, I have growing reservations about it, and many questions. This article about an experiment with a right to work was the first text in a while I read on it that substantially impacted my thinking on this (text is in German). I recommend reading it.
Work is not just a source of money, but for many also a source of meaning, pride, structure, motivation, social connections. Having voluntary access to work seems to be one major component that is necessary on a societal level, in addition to a universal basic income that allows that everyone can live in dignity. Note: I think work should be widely construed. If someone has something that fills that need, that's work. Raising children, taking care of a garden, writing a book, refining piano skills, creating art, taking care of others, taking care of yourself, all these easily count as work in my book.
I wish we were willing and able to experiment with different ways of structuring society as we are willing and able to experiment with technology. We deployed the Internet to the world without worrying about the long term consequences, but we're cautious about giving everyone enough money to not be hungry. That's just broken. I was always disappointed about the fact that sociology and politics as studied and taught by academia were mostly descriptive and not constructive endeavors.
Wikidata - The Making of
Markus Krötzsch, Lydia Pintscher and I wrote a paper on the history of Wikidata. We published it in the History of the Web track at The Web Conference 2023 in Austin, Texas (what used to be called the WWW conference). This spun out of the Ten years of Wikidata post I published here.
The open access paper is available here as HTML: dl.acm.org/doi/fullHtml/10.1145/3543873.3585579
Here as a PDF: dl.acm.org/doi/pdf/10.1145/3543873.3585579
Here on Wikisource, thanks to Mike Peel for reformatting: Wikisource: Wikidata - The Making Of
Here is a YouTube trailer for the talk: youtu.be/YxWs_BS31QE
And here is the full talk (recreated) on YouTube: youtu.be/P3-nklyrDx4
20 years of editing Wikipedia
Today it's been exactly twenty years since I made my first edit to Wikipedia. It was about the island of Brač, in the German Wikipedia.
Here is the version of the article I have created: Brač (as of May 11, 2003)
How much April 1st?
In my previous post, I was stating that I might miss April 1st entirely this year, and not as a joke, but quite literally. Here I am chronicling how that worked out. We were flying flight NZ7 from San Francisco to Auckland, starting on March 31st and landing on April 2nd, and here we look into far too much detail to see how much time the plane spent in April 1st during that 12 hours 46 minutes flight. There’s a map below to roughly follow the trip.
5:45 UTC / 22:45 31/3 local time / 37.62° N, 122.38° W / PDT / UTC-7
The flight started with taxiing for more than half an hour. We left the gate at 22:14 PDT time (doesn’t bode well), and liftoff was at 22:45 PDT.. So we had only about an hour of March left at local time. We were soon over the Pacific Ocean, as we would stay for basically the whole flight. Our starting point still had 1 hour 15 minutes left of March 31st, whereas our destination at this time was at 18:45 NZDT on April 1st, so still had 5 hours 15 minutes to go until April 2nd. Amusingly this would also be the night New Zealand switches from daylight saving time (NZDT) to standard time (NZST). Not the other way around, because the seasons are opposite in the southern hemisphere.
6:00 UTC / 23:00 31/3 local time / 37° N, 124° W / PDT / UTC-7
We are still well in the PDT / UTC-7 time zone, which, in general, goes to 127.5° W, so the local time is 23:00 PDT. We keep flying southwest.
6:27 UTC / 22:27 31/3 local time? / 34.7° N, 127.5° W / AKDT? / UTC-8?
About half an hour later, we reach the time zone border, moving out of PDT to AKDT, Alaska Daylight Time, but since Alaska is far away it is unclear whether daylight saving applies here. Also, at this point we are 200 miles (320 km) out on the water, and thus well out of the territorial waters of the US, which go for 12 nautical miles (that is, 14 miles or 22 km), so maybe the daylight saving time in Alaska does not apply and we are in international waters? One way or the other, we moved back in local time: it is suddenly either 22:27pm AKDT or even 21:27 UTC-9, depending on whether daylight saving time applies or not. For now, April 1 was pushed further back.
7:00 UTC / 23:00 31/3 local time? / 31.8° N, 131.3 W / AKDT? / UTC-8?
Half an hour later and midnight has reached San Francisco, and April 1st has started there. We were more than 600 miles or 1000 kilometers away from San Francisco, and in local time either at 23:00 AKDT or 22:00 UTC-9. We are still in March, and from here all the way to the Equator and then some, UTC-9 stretched to 142.5° W. We are continuing southwest.
8:00 UTC / 23:00 31/3 local time / 25.2° N, 136.8° W / GAMT / UTC-9
We are halfway between Hawaii and California. If we are indeed in AKDT, it would be midnight - but given that we are so far south, far closer to Hawaii, which does not have daylight saving time, and deep in international waters anyway, it is quite safe to assume that we really are in UTC-9. So local time is 23:00 UTC-9.
9:00 UTC / 0:00 4/1 local time / 17.7° N, 140.9° W / GAMT / UTC-9
There is no denying it, we are still more than a degree away from the safety of UTC-10, the Hawaiian time zone. It is midnight in our local time zone. We are in April 1st. Our plan has failed. But how long would we stay here?
9:32 UTC / 23:32 31/3 local time / 13.8° N, 142.5° W / HST / UTC-10
We have been in April 1st for 32 minutes. Now we cross from UTC-9 to UTC-10. We jump back from April to March, and it is now 23:32 local time. The 45 minutes of delayed take-off would have easily covered for this half hour of April 1st so far. The next goal is to move from UTC-10, but the border of UTC-10 is a bit irregular between Hawaii, Kiribati, and French Polynesia, looking like a hammerhead. In 1994, Kiribati pushed the Line Islands a day forward, in order to be able to claim to be the first ones into the new millennium.
10:00 UTC / 0:00 4/1 local time / 10° N, 144° W / HST / UTC-10
We are pretty deep in HST / UTC-10. It is again midnight local time, and again April 1st starts. How long will we stay there now? For the next two hours, the world will be in three different dates: in UTC-11, for example American Samoa, it is still March 31st. Here in UTC-10 it is April 1st, as it is in most of the world, from New Zealand to California, from Japan to Chile. But in UTC+14, on the Line Islands, 900 miles southwest, it is already April 2nd.
11:00 UTC / 1:00 4/1 local time / 3° N, 148° W / HST / UTC-10
We are somewhere east of the Line Islands. It is now midnight in New Zealand and April 1st has ended there. Even without the delayed start, we would now be solidly in April 1st local time.
11:24 UTC / 1:24 4/1 local time / 0° N, 150° W / HST / UTC-10
We just crossed the equator.
12:00 UTC / 2:00 4/2 local time / 3.7° S, 152.3° W / LINT / UTC+14
The international date line in this region does not go directly north-south, but goes one an angle, so without further calculation it is difficult to exactly say when we crossed the international date line, but it would be very close to this time. So we just went from 2am local time in HST / UTC-10 on April 1st to 2am local time in LINT / UTC+14 on April 2nd! This time, we have been in April 1st for a full two hours.
(Not for the first time, I wish Wikifunctions would already exist. I am pretty sure that taking a geocoordinate and returning the respective timezone will be a function that will be available there. There are a number of APIs out there, but none of which seem to provide a Web interface, and they all seem to require a key.)
12:44 UTC / 2:44 4/1 local time / 8° S, 156° W / HST / UTC-10
We just crossed the international date line again! Back from Line Island Time we move to French Polynesia, back from UTC+14 to UTC-10 again - which means it switches from 2:44 on April 2nd back to 2:44 on April 1st! For the third time, we go to April 1st - but for the first time we don’t enter it from March 31st, but from April 2nd! We just traveled back in time by a full day.
13:00 UTC / 3:00 4/1 local time / 9.6° S, 157.5° W / HST / UTC-10
We are passing between the Cook Islands and French Polynesia. In New Zealand, daylight saving time ends, and it switches from 3:00 local time in NZDT / UTC+13 to 2:00 local time in NZST / UTC+12. While we keep flying through the time zones, New Zealand declares itself to a different time zone.
14:00 UTC / 4:00 4/1 local time / 15.6° S, 164.5° W / HST / UTC-10
We are now “close” to the Cook Islands, which are associated with New Zealand. Unlike New Zealand, the Cook Islands do not observe daylight saving time, so at least one thing we don’t have to worry about. I find it surprising that the Cook Islands are not in UTC+14 but in UTC-10, considering they are in association with New Zealand. On the other side, making that flip would mean they would literally lose a day. Hmm. That could be one way to avoid an April 1st!
14:27 UTC / 3:27 4/1 local time / 18° S, 167° W / SST / UTC-11
We move from UTC-10 to UTC-11, from 4:27 back to 3:27am, from Cook Island Time to Samoa Standard Time. Which, by the way, is not the time zone in the independent state of Samoa, as they switched to UTC+13 in 2011. Also, all the maps on the UTC articles in Wikipedia (e.g. UTC-12) are out of date, because their maps are from 2008, not reflecting the change of Samoa.
15:00 UTC / 4:00 4/1 local time / 21.3° S, 170.3° W / SST / UTC-11
We are south of Niue and east of Tonga, still east of the international date line, in UTC-11. It is 4am local time (again, just as it was an hour ago). We will not make it to UTC-12, because there is no UTC-12 on these latitudes. The interesting thing about UTC-12 is that, even though no one lives in it, it is relevant for academics all around the world as it is the latest time zone, also called Anywhere-on-Earth, and thus relevant for paper submission deadlines.
15:23 UTC / 3:23 4/2 local time / 23.5° S, 172.5° W / NZST / UTC+12
We crossed the international date line again, for the third and final time for this trip! Which means we move from 4:23 am on April 1st local time in Samoa Standard Time to 3:23 am on April 2nd local time in NZST (New Zealand Standard Time). We have now reached our destination time zone.
16:34 UTC / 4:34 4/2 local time / 30° S, 180° W / NSZT / UTC+12
We just crossed from the Western into the Eastern Hemisphere. We are about halfway between New Zealand and Fiji.
17:54 UTC / 5:52 4/2 local time / 37° S, 174.8°W / NZST / UTC+12
We arrived in Auckland. It is 5:54 in the morning, on April 2nd. Back in San Francisco, it is 10:54 in the morning, on April 1st.
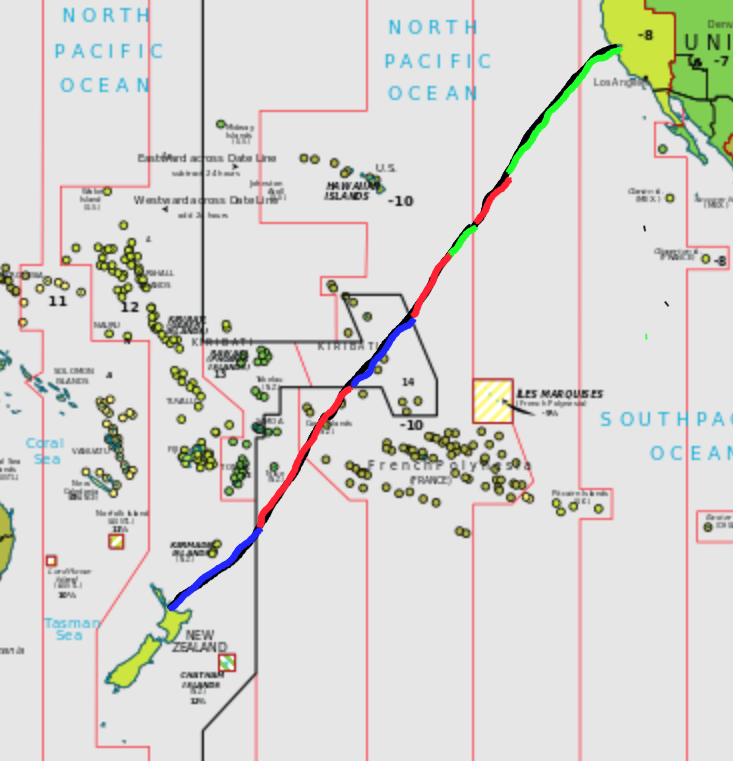
Green is March 31st, Red April 1st, Blue April 2nd, local times during the flight.
Basemap https://commons.wikimedia.org/wiki/File:Standard_time_zones_of_the_world_%282012%29_-_Pacific_Centered.svg CC-BY-SA by TimeZonesBoy, based on PD by CIA World Fact Book
{kind=link}
Postscript
Altogether, there was not one April 1st, but three stretches of April 1st: first, for 32 minutes before returning to March 31st, then for 2 hours again, then we switched to April 2nd for 44 minutes and returned to April 1st for a final 2 hours and 39 minutes. If I understand it correctly, and I might well not, as thinking about this causes a knot in my brain, the first stretch would have been avoidable with a timely start, the second could have been much shorter, but the third one would only be avoidable with a different and longer flight route, in order to stay West of the international time line, going south around Samoa.
In total, we spent 5 hours and 11 minutes in April 1st, in three separate stretches. Unless Alaskan daylight saving counts in the Northern Pacific, in which case it would be an hour more.
So, I might not have skipped April 1st entirely this year, but me and the other folks on the plane might well have had the shortest April 1st of anyone on the planet this year.
I totally geeked out on this essay. If you find errors, I would really appreciate corrections. Either in Mastodon, mas.to/@vrandecic, or on Twitter, @vrandecic. Email is the last resort, vrandecic@gmail.com (The map though is just a quick sketch)
One thing I was reminded of is, as Douglas Adams correctly stated, that writing about time travel really messes up your grammar.
The source for the flight data is here:
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA
- https://flightaware.com/live/flight/ANZ7/history/20230401/0510Z/KSFO/NZAA/tracklog
No April Fool's day
This year, I am going to skip April Fool's day.
I am not being glib, but quite literal.
We are taking flight NZ7 starting on the evening of March 31 in San Francisco, flying over the Pacific Ocean, and will arrive on April 2 in the early morning in Auckland, New Zealand.
Even if one actually follows the flight route and overlays it over the timezone map, it looks very much like we are not going to spend more than a few dozen minutes, or at most a few hours, in April 1, if all goes according to plan.
Looking forward to it!
Here's the flight data of a previous NZ7 flight, from Sunday: https://flightaware.com/live/flight/ANZ7/history/20230327/0410Z/KSFO/NZAA/tracklog
Here are the timezones (but it's Northern winter time). Would be nice to overlay the two maps: 
Where's Wikifunctions when it's needed?
The question seems to be twofold: how often do we cross the dateline, and how close are we to local time midnight while crossing the dateline. For a perfect date miss one would need to cross the dateline exactly once, at a 24 hour difference, as close as possible to local midnight.
Gordon Moore (1929-2023)
Gordon Moore was not only the co-founder of Intel and the namesake for Moore's law, the claim that every two years the number of components on a chip would double, he was also, together with his wife Betty Moore, one of the generous donors who made Wikidata possible. Gordon and Betty Moore were known for their philanthropy, and it is easy to find their names engraved at the universities, zoos, museums, and galleries in the Bay Area. Gordon Moore died today at the age of 94.
Thank you for enabling us to make Wikidata happen.
Last Unicorn dreamcast
One thing my sister and I were doing from time to time was to think, if the Last Unicorn was remade as a live action movie, who would we cast in the different roles? It is sad to see how many of our dreamcast have since died: our favorite Prince Lir was Heath Ledger, and King Haggard, unsurprisingly, Christopher Lee.
Since I was reading the book with Little One, and now watched the movie again (for the 120th time or so), I was again going through my current dreamcast. Here we go.
- Lady Amalthea - Anna Taylor-Joy
- Schmendrick - Zach Braff, Donald Glover
- Molly Grue - Mia Farrow
- Prince Lir - Owen Wilson, no, getting too old; Liam Hemsworth? Chloe Moretz would be an interesting choice
- King Haggard - Anthony Hopkins, Jack Nicholson
Since it is en vogue, I also asked Bard and ChatGPT. Here's Bard:
- Jeff Bridges as Schmendrick the Magician
- Mia Farrow as Molly Grue
- Angela Lansbury as the Unicorn
- Daryl Hannah as Filidor
- Jeff Goldblum as Schmendrick's sidekick, Bungle
- Peter Dinklage as the Red Bull
- Uma Thurman as Mommy Fortuna
- Alan Rickman as King Haggard
OK, Alan Rickman is a great choice, but unfortunately dead. Uma Thurman as Mommy Fortuna is weird. Peter Dinklage as the Red Bull... why does the Red Bull need to be cast at all? Who are Bungle and Filidor? Angela Lansbury as the Unicorn / Lady Amalthea is... not the right choice. Also dead. Mia Farrow and Jeff Bridges are too obvious choices given their roles in the cast of the animation movie, also Angela Lansbury is from the original cast. I would give Bard a D for that answer.
ChatGPT says:
- Unicorn - Saoirse Ronan or Emma Watson
- Schmendrick - Timothee Chalamet or Eddie Redmayne
- Molly Grue - Meryl Streep or Helen Mirren
- King Haggard - Ian McKellen or Christopher Lee (if he were still alive)
- Prince Lir - Tom Holland or Ansel Elgort
- Mommy Fortuna - Tilda Swinton or Cate Blanchett
Not even close to my choice, but heck, those are good choices. Molly Grue and Mommy Fortuna seem both a bit over-cast. Prince Lir and Schmendrick are pretty brilliant choices. I am not particularly impressed by Emma Watson for Lady Amalthea, I could see Saoirse Ronan work.
I'd give a B+ to ChatGPT.
I feel like ChatGPT seems to go for actors and actresses that are popular with the crowd who likes The Last Unicorn? Not the worst choice.
I followed up with Bard to see who Bungle and Filidor are, because they don't appear neither in the book nor in the movie, if I remember correctly. So, "Bungle is a red unicorn who is Schmendrick's sidekick in the novel The Last Unicorn. He is a clumsy and incompetent unicorn, but he is also a loyal and brave friend. Bungle is played by Jeff Goldblum in the 1982 animated film adaptation of the novel." And "Filidor is a bard in the novel The Last Unicorn. He is a wandering minstrel who travels the land singing songs and telling stories. Filidor is a wise and kind-hearted man, and he is always willing to help those in need. He is played by Daryl Hannah in the 1982 animated film adaptation of the novel." That's entirely a fabrication.
Running out of text
Many of the available text corpora have by now been used for training language models. One untapped corpus so far have been our private messages and emails.
How fortunate that none of the companies that train large language models have access to humongous logs of private chats and emails, often larger than any other corpus for many languages.
How fortunate that those who do have well working ethic boards established, who would make sure that such requests are evaluated.
How fortunate that we have laws in place to protect our privacy.
How fortunate that when new models are published also the corpora are being published on which the models are being trained.
What? Your telling me, "Open"AI is keeping the training corpus for GPT-4 secret? The company closely associated with Microsoft, who own Skype, Office, Hotmail? The same Microsoft who just fired an ethics team? Why would all that be worrisome?
P.S.: To make it clear: I don't think that OpenAI has used private chat logs and emails as training data for GPT-4. But by not disclosing their corpora, they might be checking if they can get away with not being transparent, so that maybe next time they might do it. No one would know, right? And no one would stop them. And hey, if it improves the metrics...
Oscar winning families
Yesterday, when Jamie Lee Curtis won her Academy Award, I learned that both her parents were also nominated for Academy Awards. Which lead to the question: who else?
I asked Wikidata, which lists four others:
- Laura Dern
- Liza Minnelli
- Nora Ephron
- Sean Astin
Only one of them belongs to the even more exclusive club of people who won an Academy Award, and where both parents also did: Liza Minnelli, daughter of Vincente Minelli and Judy Garland.
Also interesting: List of Academy Award-winning families
The place of birth of Ena Begović
I stumbled accidentally over a discrepancy regarding the place of birth of the Croatian actress Ena Begović, and noticed that if you ask Google for the place of birth, it answers Trpanj, whereas Wikipedia lists Split. I was curious where Google got Trpanj from, and how to fix it (especially now that I am not at Google anymore).
The original article in English Wikipedia was created in August 2005 by Raoul DMR. The article listed her as a "native of Split", which in September 2005 was turned into "born in Split".
In April 2018, Lole484, a user who gets blocked for sockpuppeting later, adds that she was born in "Trpanj near Split". There is no Trpanj near Split, but there is a Trpanj on Pelješac. Realzing that, they remove the "near Split" part. In 2019, Ivan Ladic - a sockpuppet of Lole484 - adds a reference to the city of birth being Trpanj, Večernji list, a well known Croatian news magazine.
In April 2020, an anonymous editor changes the place of birth back to Split, and adds a reference to the Croatian national encyclopedia. Today, I changed it back to Trpanj, accidentally while not being logged in (thus anonymously), to possibly encourage a discussion, after starting a conversation on the talk page on English and Croatian a few weeks ago that had one reply.
Interestingly, within a minute after changing the text, I went to Google and asked again for the date of birth, and Google again shows me Trpanj - but this time with the Wikipedia article and the updated snippet as a source. That is impressive.
When I asked Bing, Bing was saying Split for the last three weeks, since I started this adventure, whenever I checked. Today, it still kept saying Split, referencing two sources, one of them English Wikipedia, although I had already changed English Wikipedia. Not as fresh. Let's see how long this will stick. (Maybe folks at Bing should also talk with my colleagues at Wikimedia Enterprise to improve their freshness?)
The Croatian article was created in 2006 after the English one already stated Split, and Split was presumably copied over from the English version. Lole484 changed it to Trpanj in May 2018, and was later also blocked on Croatian Wikipedia, for unrelated reasons of vandalism. The same anonymous editor as on English Wikipedia changes it back to Split in April 2020.
Serbian and Serbocroatian started their articles in 2007, Russian in 2012, Ukrainian in 2016, Albanian and Bulgarian in 2017, Egyptian Arabic was created in October 2020. They all had Split from the beginning and throughout until today, presumably copied from English, directly or indirectly.
Amusingly, Serbian Wikipedia's opening sentence, which includes the place of birth being Split, receives a reference in January 2022 - but the reference actually states Trpanj.
None of the other language editions had their article started in the 2018-2019 window when English and Croatian stated the place of birth as Trpanj.
The only other Wikipedia language edition that saw a change of the place of birth was the Bosnian. The article on Bosnian Wikipedia started a few months after the Croatian, in 2006 (and thus being the third oldest article), and presumably also just copied from either Croatian or English. Lole484 changed it to Trpanj in April 2018, just like on the other Wikipedias. Here it was reverted the next day, but Lole484's sockpuppet Ivan Ladic reinstated that change in January 2019. When I started this adventure, the only Wikipedia that stated Trpanj was Bosnian, all other eight language editions with an article said Split.
On Wikidata, the item was created in 2012, shortly after the launch of the site, based on the existing six sitelinks. The place of birth being Split is added the following year, imported from the Russian Wikipedia.
After I stumbled upon the situation, I added Trpanj as second place of birth, and added sources to both Trpanj and Split.
What's the situation outside of Wikipedia? Both places have pretty solid references going for them:
Trpanj
- Večernji list, article from 2016
- Biografija stated Trpanj, no date, but after 2013 (Archive has the first copy from October 2020)
- tportal.hr has an article on a photography exhibition in Trpanj about Ena Begović, saying the place is chosen because it is her place of birth, published 2016
- Jutarnji list, a well known Croatian newspaper, has a long article about the actress, calling their house in Trpanj the 'rodna kuća', their birth home, of Ena and her sister Mia. This does not necessarily mean that it is literally the house they were born in. Published 2010
- HRT (Croatian national broadcaster), published 2021
- Dubrovački Vjesnik, local newspaper close to Trpanj, lists Trpanj, article from 2020
- Slobodna Dalmacija, a local newspaper from Split, writes Trpanj (but note that this is the same author as the previous article)
- Juarnji list, published 2020 (but note that this is the same author as the previous article)
- Geni.com says Trpanj, last updated 2022
Split
- Croatian national encyclopedia, published in 2021
- Filmski leksikon from the same publisher, no date, but after 2008 (Archive has the first copy from 2022)
- Proleksis, but same publisher as above, as of 2013
- Gloria, a Croatian magazine, says she was born in Split, but Trpanj was her home, published 2020
- film.hr via Archive, from 2007
- Espreso.co.rs writes Split, published 2022
- Find-a-grave lists Split on the site, but more importantly, the photograph of her grave avoids a mention of the place, but only gives the date of her birth and death
- ČSFD (Czechoslovak film database)
- Prabook, from the World Biographical Encyclopedia
- Svensk Filmdatabas
- TMDB (The Movie Database)
- Discogs
24sata says she grew up in Trpanj, gives her date of birth, but avoids stating her place of birth.
Only very few of the sources predate the English Wikipedia article, most notably:
- net.hr published the news of her death and burial in 2000, and lists Split as the place of birth
- IMdb from April 2005 via Archive lists Split, and throughout (I guess?) until today
I also looked up her sister Mia and found her profile on Facebook and sent her a message, but I assume she never even saw this message request. At least I never received an answer (and I didn't expect to). For Mia, the situation is similar: her article originally stated Split, was changed by Lole484 and reverted by an anonymous user, both in English and Croatian, whereas the other languages just list Split throughout.
There were many other sources, and they were going one way or the other. Many of the sources probably just copied from each other. The fact that there were some sources, such as Večernji, that stated Trpanj before it ever made to Wikipedia, but after Split was listed in Wikipedia, was swaying me to think it is Trpanj. Also, it was not always the strongest sources (e.g. usually I would rank the national encyclopedia over Večernji) that said Trpanj, but it was the most in-depth articles, that looked like the authors actually took the time to do some research. Many of the sources looked like they were just bots copying from Wikipedia or Wikidata, or quick pieces taking the base data from Wikipedia.
But then, finally, I stumbled upon one more source: index.hr re-published in 2019 an 1989 interview by Kemal Mujičić with Ena and Mia Begović. Here's a quote from the interview:
Rođene su u Trpnju na Pelješcu.
Ena: Molim vas, to posebno naglasite: Svi misle da smo Dubrovkinje.
Mia: Zanimljivo je da smo u Trpnju rođene kao podstanarke. Roditelji su tek poslije sagradili onu kućicu.
Translation:
They (Ena and Mia) are born in Trpanj on Pelješac.
Ena: Please put an emphasis on this: everyone thinks we are from Dubrovnik.
Mia: It is interesting that in Trpanj we were born as renters. Our parents built the little house (in which we lived) only later.
Ha! It is amusing to see that Ena's worry was that everyone thinks they are from Dubrovnik. I couldn't find a single source claiming that (but she went to high school (gimnazijum) in Dubrovnik, which is probably the source of that statement from 30 years ago). Also, so much for birth house.
Given all of that, I am going with Trpanj, and making the changes to the Wikipedia languages as much as I can (if someone can help with Arabic and Egyptian Arabic for Ena and Mia, that would be swell, I cannot edit that language edition). Let's see if it sticks.
So, why did Google know the correct answer, even though their usual sources, such as Wikidata and Wikipedia where saying Split? I mustn't say too much but it is due to the Google Knowledge Graph team and their quality processes. Seriously, congratulations to my former colleagues at Google for getting that right!
Just for fun, I also asked ChatGPT (on February 15). And the answer surprised me: when I asked in English, it gave me, unsurprisingly, Split (certainly what the Web seems to believe). But when I asked in Croatian, it gave me a different answer! And the answer was neither Split, nor Trpanj, and also not Dubrovnik - but Zagreb! It is interesting that something like the place of birth of an actress would lead to different answers depending on the language. I would have expected this knowledge to be in the 'world knowledge' of the LLM, not in the 'language knowledge'. I can't check out Bing's chat interface, as I have no access to it, but I would be curious what it says and how long it takes to update.
Thank you for going along on this rather nerdy ride of citogenesis.
Update
Ah, only a few hours after this publication, Bing got updated. And they not only switched from Split to Trpanj, they use this very blogpost as one of the two authoritative references for Trpanj!
Ina Kramer (1948-2023)
1990 erschien die erste aventurische Regionalkarte "im 3D Effekt", wie es damals beworben wurde, "Das Bornland" im Abenteuer "Stromaufwärts" von Michelle Schwefel. Später im Jahr erschien dann die Spielhilfe "Das Königreich am Yaquir", in dem die Karte zum Lieblichen Feld war.
Ich habe stundenlang diese Karten angestarrt. Sie waren so unglaublich detailliert. So wunderschön. Ich war sprachlos, wie schön diese Karten waren. Ich kannte nichts was die Qualität dieser Karten hatte, nicht nur bezüglich Karten für Rollenspielwelten und Fantasywelten, sondern überhaupt.
Es war ein frecher Traum, sich vorzustellen, ganz Aventurien in diesem Format, eins zu einer million, zu haben, und dennoch, innerhalb eines guten Jahrzehnts war der Traum erfüllt, Box für Box, Publikation für Publikation.
Wir verdanken dieses Meisterwerk, Aventurien im Massstab von 1:1.000.000, der Autorin und Grafikerin Ina Kramer. Ina's Bilder und vor allem Porträts und Karten in den DSA Publikationen der späten 80er und den 90er haben für mich mein Bild von DSA und wie ich mir Aventurien vorstellte geprägt wie sonst nur Caryad. Ob das Porträt von Kaiser Hal, Haldana von Ilmenstein, Prinz Brin, so viele andere. Neben ihren Bildern schrieb sie auch vielerlei Texte, vor allem Romane.
Das Rad ist zerbrochen. Am 10. Februar 2023 ist Ina Kramer im Alter von 74 Jahren gestorben.
Ina, vielen Dank für Deine Werke. Ich durfte Ina ein paar Mal treffen, auf Konventen und manchen anderen Gelegenheiten. Ihre Werke haben für mich einen wichtigen Teil meines Lebens mit Bildern und Karten erfüllt. Ich glaube auch, dass Inas Karten mein lebenslanges Interesse an Landkarten weckte.
Connectionism and symbolism: The fall of the symbolists
The big tech layoffs happen, unfortunately and entirely by coincidence, at a time of incredibly elevated expectations regarding machine learned generative models: ChatGPT may not be the 'best' language model out there, but due to the hard work by OpenAI to turn it into an easy to use product, and the huge amount of resources made available for free so that a very large audience could play with it, has in a very short time managed to captured the imagination of many and the conversation. I would say, rightfully. The way ChatGPT was released led to a shock in the sense that we are right now dazed and confused about what effect this technology will have on the world.
And while we are still in the middle of processing this shock, large scale strategic decisions regarding many projects and people were made. Anyone in big tech who worked on symbolic approaches in natural language processing, knowledge representation and reasoning, and other fields of artificial intelligence had a hard time to keep their job. It feels right now like large language models will make all of these symbolic approaches superfluous (I think, this might be true, but is more likely to turn out to be mistaken).
It is always difficult to predict how events will be viewed historically. The advent of wide-spread deep learning approaches in the 2010s, culminating in the well-deserved recognition of Hinton, LeCun, and Bengio with the Turing Award show clearly what dominated the research agenda and the attention in AI in the last decade. But until now it felt like symbolic approaches still had some space left, that the growth in deep learning was in addition to other approaches. Symbolic approaches were ready to offer impulses and work on ideas for a field which might well be climbing towards a local maximum.
But a good number of the teams that were disbanded in the layoffs were exactly teams working with such symbolic approaches, and it feels like these parts of AI are now entering a bitter-cold winter.
A lot of knowledge is being lost right now, and many paths to innovative ideas are being buried. I have no doubt that there are still a lot of breakthroughs to be had in machine learning, and that there is immense value to be collected from the research results in machine learning from the last few years. And with immense I mean tens and hundreds of billions of dollars.
Nevertheless I expect that we will hit a wall. Reach a local maximum. Run into problems and limitations. And it would be good to keep a wider net to cast. To keep a larger search space alive. Alas, it seems it is not meant to be. In this abundance of capital and potential value, we seem to be on the way to starve research, optimise away alternatives, and to give everything to the mainstream ideas.
22 years of Wikipedia
I was just reading a long discussion regarding the differences between Open Street Maps and Wikipedia / Wikidata, and one of the mappers complained "Wiki* cares less about accuracy than the fact that there is something that can be cited", and calling Wikipedia / Wikidata contributions "armchair work" because we don't go out into the world to check a fact, but rely on references.
I understand the expressed frustration, but at the same time I'm having a hard time letting go of "reliability not truth" being a pillar of Wikipedia.
But this makes Wikipedia an inherently conservative project, because we don't reflect a change in the world or in our perception directly, but have to wait for reliable sources to put it in the record. There's something I was deeply uncomfortable with: so much of my life is devoted to a conservative project?
Wikipedia is a conservative project, but at the same time it's a revolutionary project. Making knowledge free and making knowledge production participatory is politically and socially a revolutionary act. How can this seeming contradiction be brought to a higher level of synthesis?
In the last few years, my discomfort with the idea of Wikipedia being conservative has considerably dissipated. One might think, sure, that happened because I'm getting older, and as we get older, we get more conservative (there's, by the way, unfortunate data questioning this premise: maybe the conservative ones simply live longer because of inequalities). Maybe. But I like to think that the meaning of the word "conservative" has changed. When I was young, the word conservative referred to right wing politicians who aimed to preserve the values and institutions of their days. An increasingly influential part of todays right wing though has turned into a movement that does not conserve and preserve values such as democracy, the environment, equality, freedoms, the scientific method. This is why I'm more comfortable with Wikipedia's conservative aspects than I used to be.
But at the same time, that can lead to a problematic stasis. We need to acknowledge that the sources and references Wikipedia has been built on, are biased due to historic and ongoing inequalities in the world, due to different values regarding the importance of certain types of references in the world. If we truly believe that Wikipedia aims to provide everyone with access to the sum of all human knowledge, we have to continue the conversations that have started about oral histories, about traditional knowledges, beyond the confines of academic publications. We have to continue and put this conversation and evolution further into the center of the movement.
Happy Birthday, Wikipedia! 22 years, while I'm 44 - half of my life (although I haven't joined until two years later). For an entire generation the world has always been a world with free knowledge that everyone can contribute to. I hope there is no going back from that achievement. But just as democracy and freedom, this is not a value that is automatically part of our world. It is a vision that has to be lived, that has to be defended, that has to be rediscovered and regained again and again, refined and redefined. We (the collective we) must wrest it from the gatekeepers of the past (including me) to allow it to remain a living, breathing, evolving, ever changing project, in order to not see only another twenty two years, but for us to understand this project as merely a foundation that will accompany us for centuries.
Good bye, kuna!
Now that the Croatian currency has died, they all come to the Gates of Heaven.
First goes the five kuna bill, and Saint Peter says "Come in, you're welcome!"
Then the ten kuna bill. "Come in, you're welcome!"
So does the twenty and fifty kuna bills. "Come in, you're welcome!"
Then comes the hundred kuna bill, expecting to walk in. Saint Peter looks up. "Where do you think you're going?"
"Well, to heaven!"
"No, not you. I've never seen you in mass."
(My brother sent me the joke)
Happy New Year, 2023!
For starting 2023, I will join the Bring Back Blogging challenge. The goal is to write three posts in January 2023.
Since I have been blogging on and off the last few years anyway, that shouldn't be too hard.
Another thing this year should bring is to launch Wikifunctions, the project I have been working on since 2020. It was a longer ride than initially hoped for, but here we are, closer to launch than ever. The Beta is available online, and even though not everything works yet, I was already able to impress my kid with the function to reverse a text.
Looking forward to this New Year 2023, a number that to me still sounds like it is from a science fiction novel.
Goal for Wikidata lexicographic data coverage 2023
At the beginning of 2022, Wikidata had 807 Croatian word forms, covering 5.8% of a Croatian language corpus (Croatian Wikipedia). One of my goals this year was to significantly increase the coverage, trying to add word forms to Wikidata from week to week. And together with a yet small number of contributors, we pushed coverage just in time for the end fo the year to 40%. With only 3,124 forms, we covered 40% of all occurrences of words in the Croatian Wikipedia, i.e. 11.4 Million word occurrences (tokens).
Since every percent is more and more difficult to add, for next year I aim for us to reach 60% coverage, or 5.7 Million more word occurrences. Below's a list of most frequent words in the corpus that are still missing. Let's see how many forms will be covered by the end of 2023! I think that's ambitious, even though it is, in coverage term only half of what we achieved this year. But as said, every subsequent percentage will become more difficult than the previous one.
Statistics and missing words for 55 languages: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage
Current statistics for Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Statistics
Statistics as of end of year 2022: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1797161415
Statistics for end of year 2021: https://www.wikidata.org/w/index.php?title=Wikidata:Lexicographical_coverage/hr/Statistics&oldid=1551737937
List of most frequent missing forms in Croatian: https://www.wikidata.org/wiki/Wikidata:Lexicographical_coverage/hr/Missing
Using ChatGPT for fact checking
I wanted to explore the idea that we could use ChatGPT for fact checking. So I took a random article - it gave me the article on Jewish Ideas Daily, copied the text into ChatGPT with the following prompt:
Here's the text of a Wikipedia article. Please find the three statements that are most likely incorrect and rank them, in order to guide fact checking:
Followed by the Wikipedia article text. Here's the answer:
- "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." This statement is incorrect because according to the article, Margot Lurie was the editor of Jewish Ideas Daily "until December 2012."
- "Jewish Ideas Daily drew notice for controversial features including one accusing Christopher Hitchens of antisemitism." This statement is difficult to verify without more context, as it is not clear when this feature was published or what specifically it accused Hitchens of.
- "Like Jewish Review of Books, and Jewish Ideas Daily, Mosaic is funded by the Tikvah Fund." This statement is incorrect because according to the article, Mosaic succeeded Jewish Ideas Daily in June 2013 and is therefore not funded by the Tikvah Fund in the same way as Jewish Ideas Daily and Jewish Review of Books.
Regarding the first statement, GPT says that the sentence "Jewish Ideas Daily was edited by Margot Lurie from its founding in January 2010 until December 2012." is incorrect. I am not disagreeing, but that sentence does not appear in the Wikipedia article text.
Regarding the second statement, GPT says that there is no reference for that statement. In fact, there is, and Wikipedia provides it.
Regarding the third statement, I didn't check the statement, but the argumentation for why it should be checked is unconvincing: if Tikvah fund financed Jewish Ideas Daily, why would it not finance the successor Mosaic? It would be good to add a reference for these statements, but that's not the suggestion.
In short: the review by ChatGPT looks really good, but the suggestions in this case were not good.
The exercise was helpful insofar the article infobox and the text were disagreeing on the founding of the newspaper. I fixed that, but that's nothing ChatGPT pointed out (and couldn't, as I didn't copy and paste the infobox).
Economic impacts of large language models, a take
Regarding StableDiffusion and GPT and similar models, there is one discussion point floating around, which I find seems to dominate the discussion but may not be the most relevant one. As we know, the training data for these models has been "basically everything the trainers could get their hands on", and then usually some stuff which is identified as possibly problematic is removed.
Many artists are currently complaining about their images, for which they hold copyright, being used for training these models. I think these are very reasonable complaints, and we will likely see a number of court cases and even changes to law to clarify the legal aspects of these practises.
From my perspective this is not the most important concern though. I acknowledge that I have a privileged perspective in so far as I don't pay my rent based on producing art or text in my particular style, and I entirely understand if someone who does is worried about that most, as it is a much more immediate concern.
But now assume that these models were all trained on public domain images and texts and music etc. Maybe there isn't enough public domain content out there right now? I don't know, but training methods are getting increasingly more efficient and the public domain is growing, so that's likely just a temporary challenge, if at all.
Does that change your opinion of such models?
Is it really copyright that you are worried about, or is it something else?
For me it is something else.
These models will, with quite some certainty, become similarly fundamental and transformative to the economy as computers and electricity have been. Which leads to many important questions. Who owns these models? Who can run them? How will the value that is created with these models be captured and distributed across society? How will these models change the opportunities of contributing to society, and there opportunities in participating in the wealth being created?
Copyright is one of the current methods to work with some of these questions. But I don't think it is the crucial one. What we need is to think about how the value that is being created is distributed in a way that benefits everyone, ideally.
We should live in a world in which the capabilities that are being discovered inspire excitement and amazement because of what might be possible in the future. Instead we live in a world where they cause anxiety and fear because of the very real possibility of further centralising wealth more effectively and further destabilizing lives that are already precarious. I wish we could move from the later world to the former.
That is not a question of technology. That is a question of laws, social benefits, social contracts.
A similar fear has basically killed the utopian vision which was once driving a project such as Google Books. What could have been a civilisational dream of having all the books of the world available everywhere has become so much less. Because of the fears of content creators and publishers.
I'm not saying these fears were wrong.
Unfortunately, I do not know what the answer is. What changes need to happen. Does anyone have links to potential answers, that are feasible? Feasible in the sense that the necessary changes have a chance of being actually implemented, as changes to our legal and social system.
My answer used to be Universal Basic Income, and part of me still thinks it might be our best shot. But I'm not as sure as I used to be twenty years ago. Not only about whether we can ever get there, but even whether it would be a good idea. It would certainly be a major change that would alleviate many of the issues raised above. And it could be financed by a form of AI tax, to ensure the rent is spread widely. But we didn't do that with industrialization and electrification, and there are reasonable arguments against.
And yet, it feels like the most promising way forward. I'm torn.
If you read this far, thank you, and please throw a few ideas and thoughts over, in the hope of getting unstuck.